 673
673 
Содержание
Где stateful-операторы хранят состояния, почему RocksDB лучше HDFSBackedStateStore и как Databricks адаптировал key-value хранилище к особенностям Spark Structured Streaming, чтобы сделать потоковую обработку больших данных еще быстрее.
Где stateful-операторы Spark Structured Streaming хранят состояния?
Хотя Apache Spark Structured Streaming реализует потоковую парадигму обработки информации, он по-прежнему использует микропакеты, т.е. ограниченные наборы данных, с которыми выполняется операция. Например, рассмотрим типовую задачу анализа данных в некотором временном окне, например, определить скользящее среднее количество запросов, поступивших из разных городов в течение 5 минут. Чтобы получить результат, необходимо знать не только данные в текущем микропакете, но и в предыдущих. Такие операции с данными называются stateful, а сами обрабатываемые при этом данные называются состоянием, которое необходимо сохранить. В Spark Structured Streaming состояния хранятся в хранилищах состояний исполнителей, потребляя их ресурсы: память и дисковое пространство. Как мы уже отмечали в прошлой статье, в Apache Spark есть две встроенные реализации провайдера хранилища состояний:
- распределенная файловая система Hadoop (HDFS), используемая по умолчанию. Здесь все данные на первом этапе MapReduce-вычислений сохраняются в памяти, а затем в файлах в файловой системе, совместимой с HDFS. В реализации HDFSBackedStateStore данные о состоянии хранятся в памяти JVM исполнителей, а большое количество объектов состояния создает нагрузку на память JVM, вызывая большие паузы в работе сборщика мусора (Garbage Collector).
- RocksDB – реализация на основе key-value БД, добавленная в Apache Spark с версии 3.2. Она позволяет избежать проблем с JVM при множестве ключей для stateful-операций, когда сборка мусора приостанавливается, вызывая большие различия во времени микропакетной обработки. Вместо хранения состояния в памяти JVM используется NoSQL-хранилище RocksDB для эффективного управления состоянием в собственной памяти и на локальном диске. При этом любые изменения этого состояния автоматически сохраняются структурированной потоковой передачей в указанное местоположение контрольной точки, обеспечивая полные гарантии отказоустойчивости.
Именно RocksDB рекомендуется использовать в качестве хранилища состояний для производственных рабочих нагрузок, поскольку со временем размер состояния обычно увеличивается и превышает миллионы ключей. Использование RocksDB позволяет избежать проблем с памятью, связанных с кучей JVM, или замедления работы из-за сборки мусора, что характерно для HDFS.
Как показали бенчмаркинговые тесты, проведенные дата-инженерами компании Databricks, stateful-операции, сохраняющие состояние в RocksDB, выполняются в несколько раз быстрее по сравнению с использованием HDFS. Такая скорость достигается за счет адаптации внутренних механизмов RocksDB к особенностям Spark Structured Streaming, что мы рассмотрим далее.
Как работает RocksDB в Apache Spark?
Вообще RocksDB — это встраиваемое постоянное хранилище типа ключ-значение, которое использует механизм базы данных со структурой логов. Ключи и значения представляют собой потоки байтов произвольного размера. Оно оптимизировано для быстрого хранения данных с низкой задержкой (флэш-накопители и высокоскоростные диски) и обеспечивает высокую скорость чтения и записи данных.
RocksDB использует память для memtables, блочного кэша и других закрепленных блоков. Раньше все обновления в микропакете буферизировались в памяти с помощью метода WriteBatchWithIndex(), а пользователи могли настраивать только отдельные ограничения памяти экземпляра для использования буфера записи и блочного кэша. Это позволяло неограниченно использовать память для каждого экземпляра, но приводило к проблеме, когда несколько экземпляров хранилища состояний запланированы на одном рабочем узле. Чтобы избежать этого, команда Databricks реализовала такие изменения, которые ограничивают возможности пользователей по управлению памятью с помощью функции менеджера буфера записи. Это позволяет пользователям устанавливать единый глобальный лимит памяти для управления блочным кэшем, буфером записи и фильтрацией использования блочной памяти между экземплярами хранилища состояний на одном узле исполнителя. Также устранена зависимость от метода WriteBatchWithIndex(): обновления больше не буферизуются без ограничений, а записываются непосредственно в базу данных. Это позволяет не использовать журнал упреждающей записи (WAL), поскольку все обновления безопасно записываются локально в виде SST-файлов и впоследствии сохраняются в постоянном хранилище как часть каталога контрольных точек для каждого микропакета.
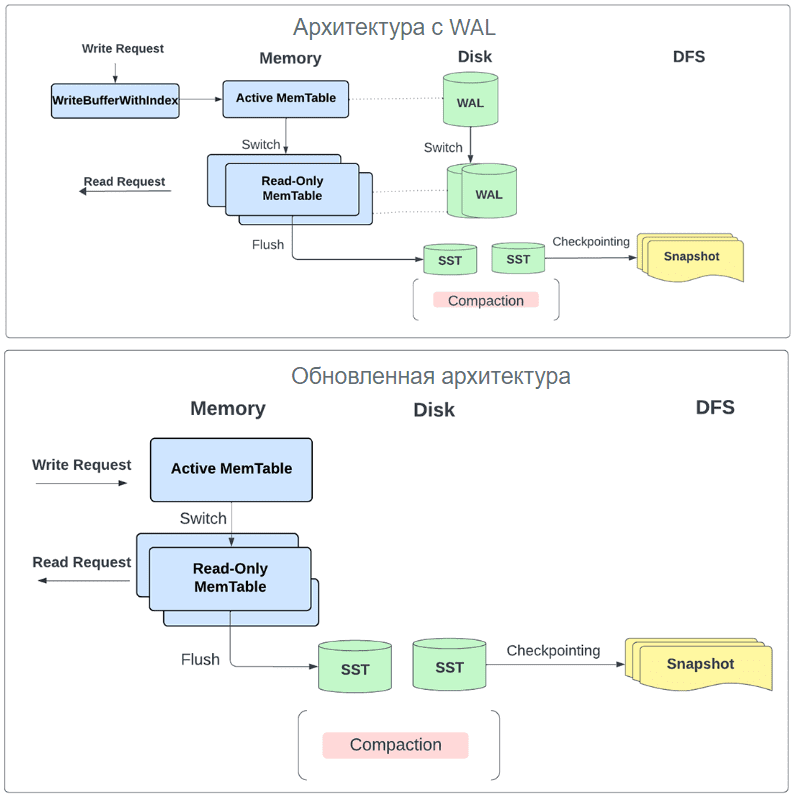
Помимо обслуживания всех операций чтения и записи в основном из памяти, это изменение позволяет периодически сбрасывать записи в хранилище, когда включена контрольная точка журнала изменений, а не для каждого микропакета.
Вообще именно задержка контрольных точек состояния является узким местом в производительности потоковой передачи Spark. Эта задержка возникала из-за периодических приостановок работы экземпляров RocksDB, связанных с фоновыми операциями, а также процессом создания и загрузки моментальных снимков, который был частью фиксации пакета.
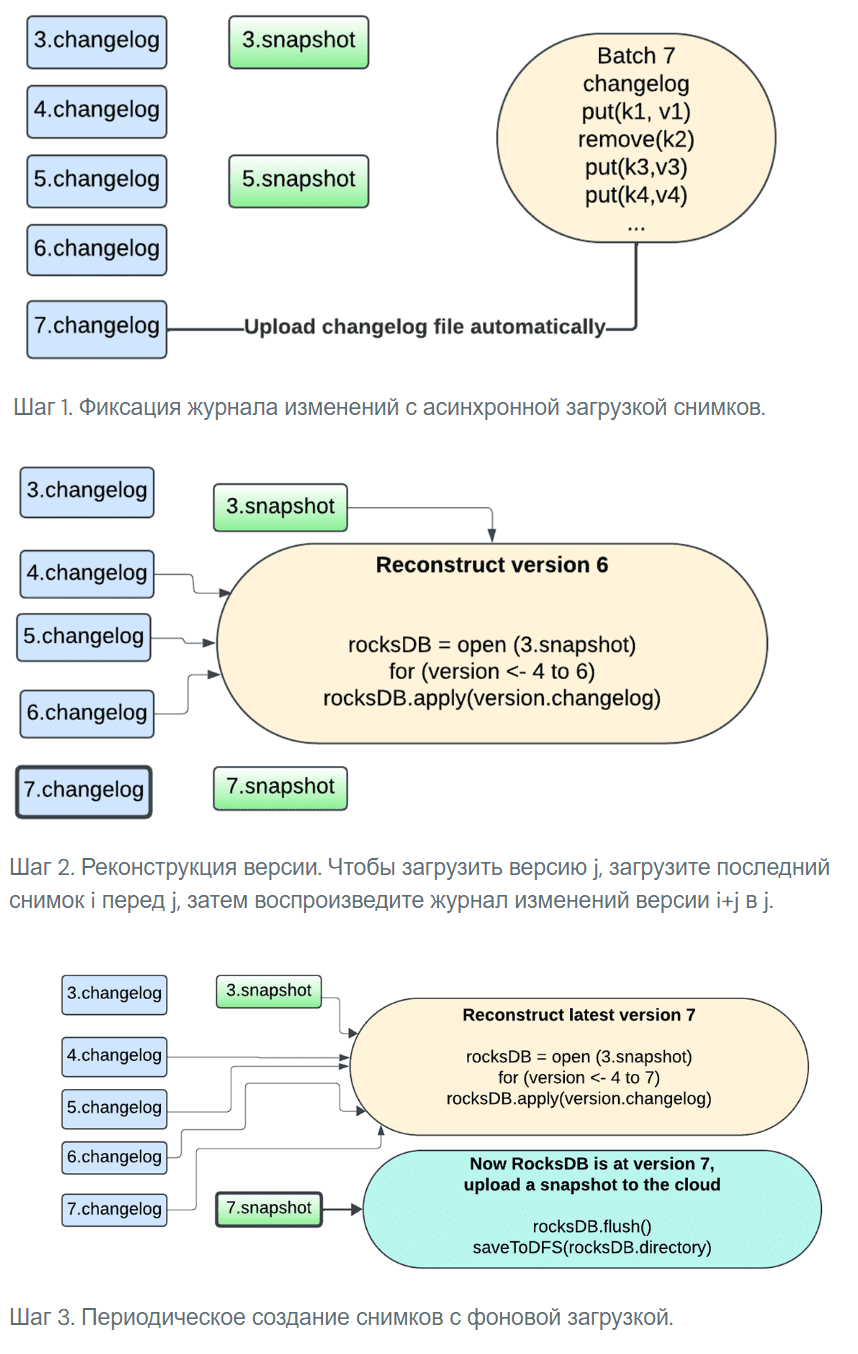
Измененный дизайн использования RocksDB для хранения состояний в Spark Structured Streaming не требует создавать снимок всего состояния до контрольной точки __cpLocation. Вместо этого теперь используется контрольная точка журнала изменений, которая делает состояние микропакета устойчивым, сохраняя только изменения с момента последней контрольной точки при каждой фиксации микропакета.
Контрольная точка журнала изменений отключена по умолчанию. Ее можно на уровне SparkSession, задав конфигурации spark.sql.streaming.stateStore.rocksdb.changelogCheckpointing.enabled значение True.
Процесс создания снимков теперь обрабатывается тем же экземпляром базы данных, который выполняет обновления, а снимки загружаются асинхронно с использованием задачи фонового обслуживания, чтобы избежать блокировки выполнения задачи. Теперь у пользователя есть возможность гибко настраивать интервал создания снимков, чтобы найти компромисс между восстановлением после сбоя и использованием ресурсов. Любую версию состояния можно реконструировать, выбрав снимок и воспроизведя журналы изменений, созданные после этого снимка. Это позволяет ускорить проверку состояния с использованием RocksDB.
Конфигурации и метрики RocksDB
Чтобы использовать RocksDB в качестве хранилища состояний для Spark Structured Streaming, надо установить конфигурацию spark.sql.streaming.stateStore.providerClass равной org.apache.spark.sql.execution.streaming.state.RocksDBStateStoreProvider. Также можно настроить следующие конфигурации:
- spark.sql.streaming.stateStore.rocksdb.compactOnCommit, чтобы применить диапазонное сжатие экземпляра RocksDB для фиксации операции (по умолчанию False);
- spark.sql.streaming.stateStore.rocksdb.blockSizeKB – примерный размер пользовательских данных, упакованных в блок для RocksDB BlockBasedTable, который является форматом файла SST по умолчанию (по умолчанию равно 4 КБ);
- spark.sql.streaming.stateStore.rocksdb.blockCacheSizeMB – емкость для блочного кэша (по умолчанию равно 8 МБ);
- spark.sql.streaming.stateStore.rocksdb.lockAcquireTimeoutMs — время ожидания в миллисекундах для получения блокировки в операции загрузки экземпляра RocksDB (по умолчанию равно 60000 мс);
- spark.sql.streaming.stateStore.rocksdb.resetStatsOnLoad – сброс статистики RocksDB при загрузке (по умолчанию True);
Каждый оператор состояния собирает метрики, связанные с операциями управления состоянием, выполняемыми на его экземпляре RocksDB. Это полезно для отладки, когда нужно понять, почему задание Spark Structured Streaming выполняется медленно. Показатели агрегируются (суммируются) для каждого оператора состояния в задании по всем задачам, в которых выполняется это оператор. Метрики являются частью сопоставления customMetrics внутри полей stateOperators в файлах StreamingQueryProgress. Можно отследить значение следующих метрик:
- rockdbCommitWriteBatchLatency — время (в миллисекундах), потраченное на применение поэтапной записи в структуру памяти (WriteBatch) к RocksDB;
- rockdbCommitFlushLatency – время (в миллисекундах), потраченное на сброс изменений в памяти RocksDB на локальный диск;
- RocksDBCommitCompactLatency – время (в миллисекундах), затраченное на сжатие во время фиксации контрольной точки, если конфигурация spark.sql.streaming.stateStore.rocksdb.compactOnCommit установлена в значение True;
- RocksDBCommitPauseLatency – время (в миллисекундах), затраченное на остановку фоновых рабочих потоков (для сжатия и т. д.) в рамках фиксации контрольной точки;
- rockdbCommitCheckpointLatency – время (в миллисекундах), потраченное на создание снимка исходной RocksDB и запись его в локальный каталог;
- RocksdbCommitFileSyncLatencyMs – время (в миллисекундах), потраченное на синхронизацию файлов, связанных со снимками RocksDB, с внешним хранилищем (местоположение контрольной точки);
- RocksDBGetLatency — среднее время (в наносекундах), потраченное на базовый собственный вызов RocksDB::Get;
- RockdbPutCount — среднее время (в наносекундах), потраченное на базовый собственный вызов RocksDB::Put;
- RocksDBGetCount – количество собственных вызовов RocksDB::Get (не включая Get в WriteBatch, пакете памяти, используемом для промежуточной записи);
- RockdbPutCount – количество собственных вызовов (не включая Put в WriteBatch);
- RocksDBTotalBytesReadByGet — количество несжатых байтов, прочитанных посредством собственных вызовов RocksDB::Get;
- RocksDBTotalBytesWrittenByPut — количество несжатых байтов, записанных посредством собственных вызовов RocksDB::Put;
- rockdbReadBlockCacheHitCount — количество раз, когда используется собственный блочный кеш RocksDB, чтобы избежать чтения данных с локального диска;
- rockdbReadBlockCacheMissCount — количество раз, когда собственный блочный кеш RocksDB пропадал и требовалось чтение данных с локального диска;
- RocksDBTotalBytesReadByCompaction – количество байтов, прочитанных с локального диска собственным процессом сжатия RocksDB;
- RocksDBTotalBytesWrittenByCompaction – количество байтов, записанных на локальный диск собственным процессом сжатия RocksDB;
- RocksDBTotalCompactionLatencyMs — время (в миллисекундах), затраченное на сжатие RocksDB (как фоновое, так и дополнительное сжатие, инициированное во время фиксации);
- RocksDBWriterStallLatencyMs — время (в миллисекундах), в течение которого запись была остановлена из-за фонового сжатия или сброса таблиц памяти на диск;
- rockdbTotalBytesReadThroughIterator — общий размер несжатых данных, считанных с помощью итератора, поскольку некоторые stateful-операции, например, обработка тайм-аута flatMapGroupsWithState или установка водяных знаков в оконных агрегатах, требуют чтения всех данных в БД через итератор.
Узнайте больше про возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Архитектура данных с Apache Spark
[elementor-template id=»13619″]
Источники
- https://www.databricks.com/blog/performance-improvements-stateful-pipelines-apache-spark-structured-streaming
- https://www.databricks.com/blog/deep-dive-latest-performance-improvements-stateful-pipelines-apache-spark-structured-streaming
- https://books.japila.pl/spark-structured-streaming-internals/rocksdb/
- https://spark.apache.org/docs/3.2.0/structured-streaming-programming-guide/#rocksdb-state-store-implementation
- https://docs.databricks.com/en/structured-streaming/rocksdb-state-store/

