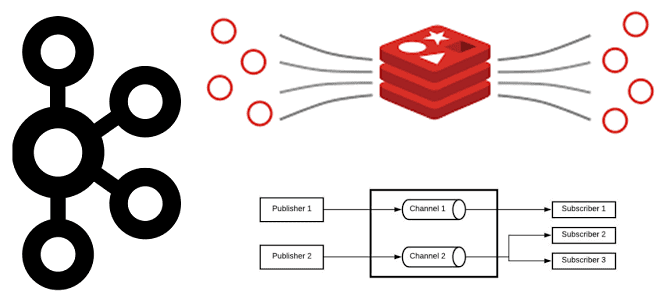
Как key-value СУБД Redis может работать с потоковыми данными и чем Pub/Sub и Streams отличаются от Apache Kafka. Сравнение и рекомендации по использованию. Потоковое сохранение данных Redis Будучи очень быстрым key-value хранилищем, NoSQL-СУБД Redis часто используется в качестве слоя кэширования для разгрузки основной базы данных. В отличие от многих других...

Насколько быстро ClickHouse выполняет SQL-запросы: тестирование СУБД в открытой онлайн-песочнице. Примеры запросов и время их выполнения. Работа с онлайн-песочницей Clickhouse: выполнение SQL-запросов Будучи реляционной аналитической СУБД, ClickHouse позволяет обрабатывать гигабайты данных в реальном времени. Архитектурные особенности, благодаря которым реализуется такая скорость, мы недавно разбирали здесь. Чтобы оценить это на практике,...

Сходства и различия популярных реляционных аналитических СУБД с открытым исходным кодом: что общего у Greenplum с ClickHouse, чем они отличаются, что и когда выбирать. Greenplum и Clickhouse: обзор возможностей для аналитики больших данных Обе СУБД являются реляционными и относятся к классу OLAP-систем, т.е. ориентированы на аналитические варианты использования, т.е. чтение...
Что такое алгоритм k-medoids, чем он отличается от k-means и как этот метод кластеризации применяется для анализа графов: принципы и инструменты. Что такое медоид и как устроен алгоритм кластеризации k-medoids Кластеризация — это метод машинного обучения для поиска кластеров или сообществ в наборе данных. Цель в том, чтобы найти кластеры,...

Что не так с Neosemantics и зачем нужна очередная библиотека для Neo4j: знакомство с Python-пакетом для RDF-графов rdflib-neo4j. Возможности, ограничения и пример использования. Что не так с Neosemantics и зачем нужна очередная библиотека для Neo4j Что такое RDF-графы, триплеты и плагин Neosemantics для работы с этими концепциями в графовой СУБД...
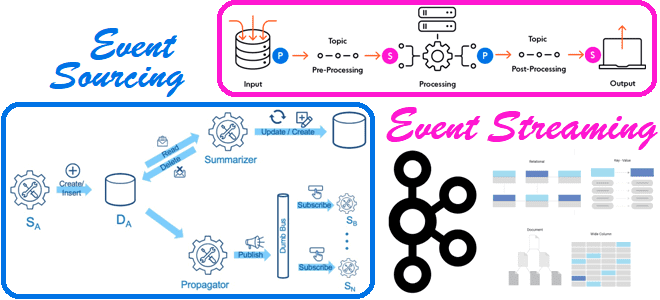
В чем разница между потоковой передачей событий и источником событий и при чем здесь Apache Kafka: разбираемся с паттернами проектирования событийно-ориентированной архитектуры. 2 паттерна проектирования EDA-архитектуры Напомним, что сегодня для построения сложных систем, зачастую состоящих из множества взаимодействующих компонентов, и реактивно реагирующих на события внешнего мира, активно используется идея архитектуры,...
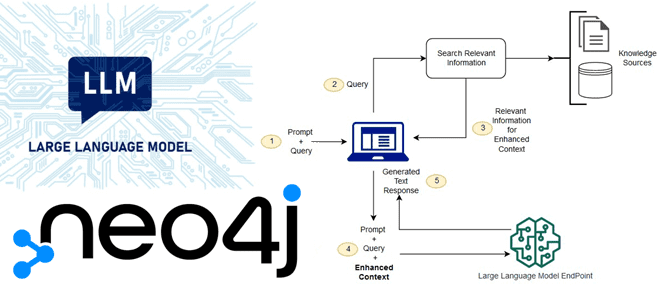
Что не так с большими языковыми моделями, как RAG-приложения расширяют возможности LLM и зачем в графовой СУБД Neo4j добавлена поддержка векторного индекса. Зачем нужны RAG-приложения: ограничения базовых LLM-сетей С появлением ChatGPT и других генеративных нейросетей, большие языковые модели (LLM, Large Language Models) стали активно применяться для решения множества бизнес-задач, связанных...

Как организовать миграцию схемы Neo4j и импортировать в графовую базу данные из реляционных систем. Знакомимся с инструментами проекта Neo4j Labs: Neo4j-ETL и Neo4j-Migrations. Как работает Neo4j-ETL В рамках развития своих продуктов, таких как графовая СУБД Neo4j и экосистема элементов вокруг нее (Graph Data Science, Neo4j Bloom, Neo4j Browser и пр.),...
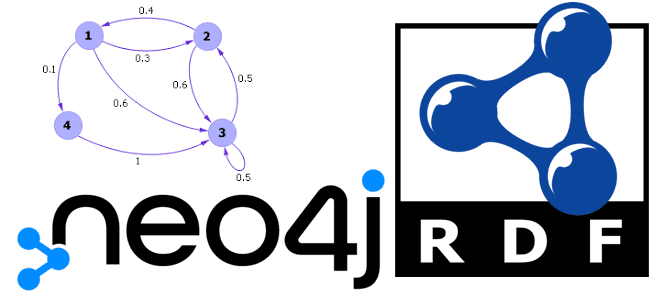
Что такое триплеты, чем они отличаются от обычных графов свойств и где используются на практике. Знакомимся с RDF и возможностями графовой СУБД Neo4j работать с этой структурой описания веб-ресурсов с помощью плагина Neosemantics. Что такое триплеты и при чем здесь RDF Триплеты (triples) — это текстовый формат, используемый для хранения...
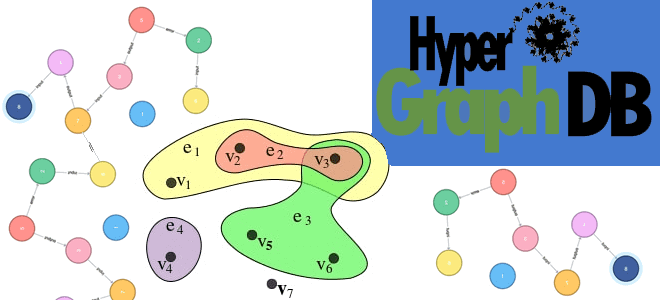
Чем гиперграфы отличаются от обычных графов знаний, где они используются на практике и как эта математическая концепция поддерживается в NoSQL-СУБД HyperGraphDB. Что такое гиперграф Гиперграф — это графовая модель данных, в которой отношения (гиперребра) могут соединять любое количество заданных узлов. Можно сказать, что это обобщение графа, в котором каждым ребром...
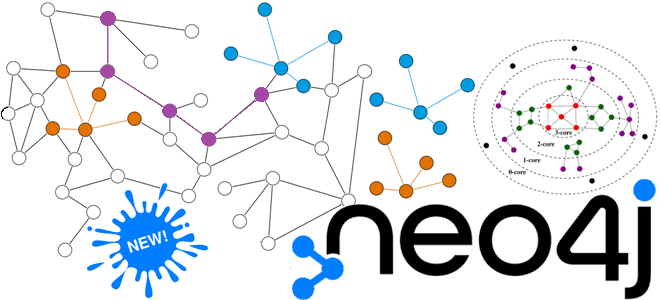
Как включить отрицательные веса в поиск пути, выявлять центральные и периферийные кластеры на основе заданной плотности, а также делать выборки из больших графов для масштабирования машинного обучения. Знакомимся с графовыми алгоритмами, недавно добавленными в библиотеку Neo4j Graph Data Science 2.4: декомпозиция K-ядра, алгоритм кратчайшего пути Беллмана-Форда и случайное блуждание с...
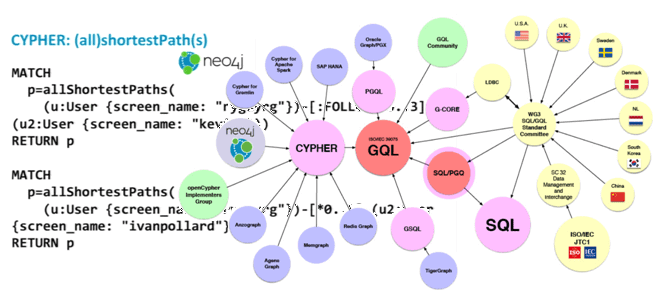
Кто и зачем создает аналог SQL для запросов к графовым базам данных, когда выйдет официальная версия стандарт и при чем здесь Cypher из Neo4j. Что такое GQL и кто его разрабатывает В рамках продвижения нашего курса по графовым алгоритмам в бизнес-приложениях мы часто рассказываем про инструменты хранения и анализа графовых...

Зачем биомедикам понадобился свой язык описания онтологий, как эти задачи решает BioCypher и при чем здесь Neo4j: практическое приложение Data Science и графовых алгоритмов в биомедицинской сфере. Что такое BioCypher Графовые алгоритмы активно применяются в биомедицине для анализа различных биологических данных, таких как геномные, протеомные, данные о белковых взаимодействиях и...

Сегодня заглянем внутрь Neo4j, чтобы разобраться с базовыми концепциями этой графовой базы данных. Какие уровни изоляции транзакций поддерживаются в Neo4j, почему одна установка по умолчанию содержит две базы данных, что такое составная БД и как с этим работать. Транзакции в Neo4j Neo4j — это популярная нативная графовая СУБД, способная управлять...
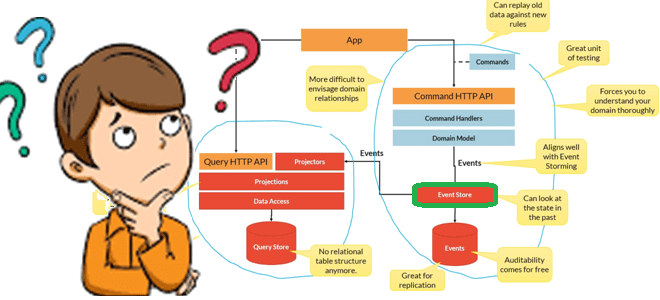
Что представляет собой паттерн проектирования микросервисов под названием источник событий (Event Sourcing) и как его реализовать в реляционных базах данных и NoSQL-системах. Разбираемся с архитектурой данных и архитектурой ПО на практических примерах. Архитектурный шаблон Event Sourcing Многие архитектурные шаблоны рассматривают сущности (entity) как основную концепцию, описывая способы их сохранения и...
Недавно мы разбирали, чем внутренне устройство графовых баз данных отличается от реляционных. Поэтому именно графовые базы целесообразно использовать для анализа больших графовов. Однако, на малых датасетах вполне можно обойтись и Python-библиотекой Networkx, что мы и рассмотрим далее на примере анализа банковских транзакций. Python-скрипт поиска сообществ в графе с библиотекой...
Что такое безиндексная смежность и как она снижает сложность алгоритмов обхода графа, позволяя быстро и эффективно запрашивать множество узлов и отношений. Разбираемся с уникальными принципами работы графовых баз данных на примере Neo4j. Архитектура и принципы работы графовых баз данных Несмотря на стремление разработчиков современных СУБД к унификации их решений, первичная...
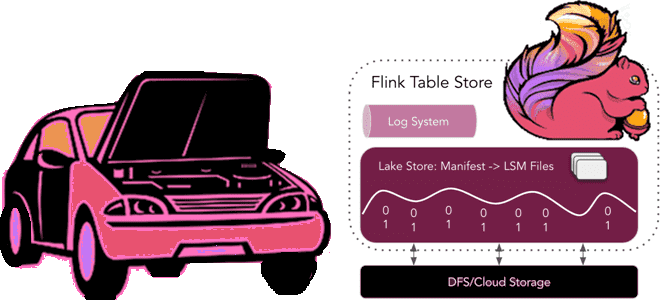
Год назад мы уже писали, как в Apache Flink появились табличные хранилища и зачем они нужны. Сегодня заглянем под капот Flink Table Store, познакомившись со структурой файлов и каталогов. Архитектура и принципы работы Flink Table Store Поскольку Apache Flink объединяет пакетную обработку данных с потоковой, для работы этого универсального stateful-механизма...
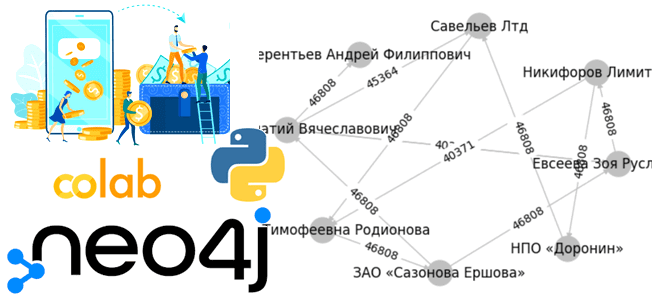
Чтобы показать еще один вариант использования графовой базы данных Neo4j, сегодня реализуем небольшое Python-приложение, которое генерирует граф знаний в облачной платформе Aura DB. Ищем финансовые переводы между компаниями и физическими лицами, считаем общую сумму и визуализируем найденные транзакции с помощью библиотеки Networkx. Python-приложение для работы с Neo4j в AuraDB Как...
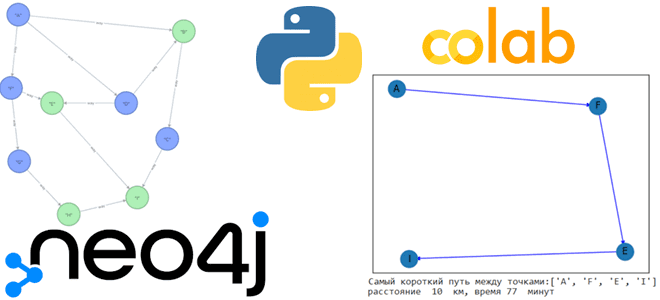
Сегодня решим логистическую задачу поиска кратчайшего пути, создав граф знаний в Neo4j, развернутой в облачной платформе Aura DB и визуализируем найденный путь с помощью Python-библиотеки Networkx. Работа с Neo4j в AuraDB В прошлой статье мы упоминали, что для работы с популярной графовой СУБД Neo4j совсем необязательно устанавливать ее локально. Можно...