 1110
1110 
Как сделать крупное обновление, вставку или удаление данных в Neo4j без OOM-ошибки и APOC-процедур при выполнении транзакции с параллельным выполнением подзапросов: функция CICT, ее возможности, ограничения и отличия от конструкции CALL IN TRANSACTIONS.
Подзапросы в транзакциях Neo4j: CIT-запросы Cypher vs процедуры APOC
Параллельная обработка данных быстрее последовательной. Поэтому многие фреймворки и базы данных поддерживают параллельное выполнение запросов. Популярная графовая база данных Neo4j тоже с конца 2023 года поддерживает параллельную среду выполнения, о чем мы рассказывали здесь. Чтобы еще больше повысить эффективность обработки графов, в релиз 5.21 добавлена функция CICT (CALL IN CONCURRENT TRANSACTIONS), которая обеспечивает высокий рост производительности запросов мутации данных, т.е. их вставки и удаления. Она особенно полезна при крупномасштабных вставках данных или обновлениях графов при миграции, рефакторинге и удалении данных, которые могут привести к огромным транзакциям.
CICT основана на функции CIT (CALL IN TRANSACTIONS), которая была впервые представлена в выпуске 4.2 Neo4j, чтобы решать проблемы с памятью при выполнении больших транзакций. Когда требуемая память превышает лимиты, доступные в настроенном пуле транзакций, это приводило к прерыванию транзакции. Чтобы устранить это, CIT предоставляет встроенный в Cypher способ разбиения транзакций на пакеты строк, разбивая эти обновления на несколько более мелких транзакций, каждая из которых потребляет меньше памяти.
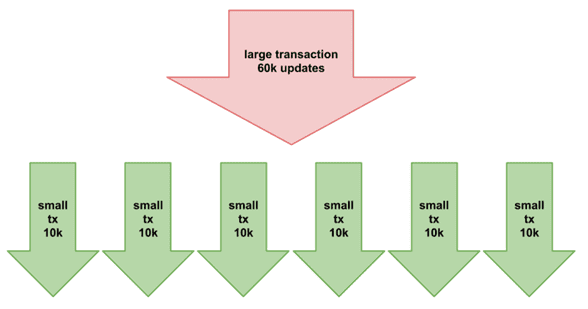
Конструкция CALL { … } IN TRANSACTIONS допускается только в неявных транзакциях, которые открываются и фиксируются автоматически после успешного завершения одного Cypher-запроса. Например, следующий запрос
LOAD CSV FROM 'file:///friends.csv' AS line
CALL (line)
{ CREATE (:Person {name: line[1], age: toInteger(line[2])})
} IN TRANSACTIONS OF 2 ROWS
фиксирует три отдельные транзакции в следующем порядке:
- Первые два выполнения подзапроса (для первых двух входных строк из LOAD CSV) происходят в первой транзакции;
- Затем первая транзакция фиксируется перед продолжением;
- Следующие два выполнения подзапроса (для следующих двух входных строк) происходят во второй транзакции;
- Вторая транзакция зафиксирована;
- Последнее выполнение подзапроса (для последней входной строки) происходит в третьей транзакции;
- Третья транзакция зафиксирована.
Можно использовать конструкцию использовать CALL { … } IN TRANSACTIONS OF n ROWS для удаления всех данных в пакетном режиме, чтобы избежать огромной сборки мусора или OOM-исключения (OutOfMemory). Например, следующий запрос:
MATCH (n)
CALL (n) {
DETACH DELETE n
} IN TRANSACTIONS OF 2 ROWS
Вообще в Neo4j CALL-подзапросы могут быть выполнены в отдельных внутренних транзакциях, производя промежуточные фиксации. Это полезно при выполнении больших операций записи, таких как пакетные обновления, импорты и удаления. Чтобы выполнить CALL-подзапрос в отдельных транзакциях, надо добавить модификатор IN TRANSACTIONS после подзапроса. Внешняя транзакция открывается для отчета о накопленной статистике для внутренних транзакций (созданные и удаленные узлы, связи и пр.), и она будет выполнена (успешно или неудачно) в зависимости от результатов этих внутренних транзакций. По умолчанию внутренние транзакции группируют пакеты по 1000 строк. Отмена внешней транзакции также отменит внутренние.
Несмотря на то, что составные базы данных Neo4j позволяют получать доступ к нескольким графам в одном запросе, в одной транзакции можно изменить только один граф. Однако, CIT-конструкция предлагает способ построения запросов, которые изменяют несколько графов.
Целью CIT является не только повышение производительности запросов, но и выполнение этих пакетных подзапросов в одном потоке ЦП, а не параллельно. Поэтому многие разработчики продолжают применять процедуру apoc.periodic.iterate() для ускорения крупных независимых транзакций записи, поскольку он обеспечивает способ параллельного выполнения запросов, т. е. использования нескольких ядер ЦП для выполнения одного запроса.
Напомним, процедура apoc.periodic.iterate() позволяет выполнить указанное количество операторов операций за одну транзакцию, в т.ч. параллельно. Однако, для сложных операций, таких как обновление или удаление отношений, не рекомендуется включение параллельного режима в apoc.periodic.iterate(). Если все же необходимо выполнить их параллельно, разработчику следует убедиться, что каждый подграф данных обновляется за одну операцию, например, путем передачи корневых объектов. При этом желательно включить повтор неудачных операций, установив значение параметру retries.
Тем не менее, несмотря на возможность настройки параметров процедуры apoc.periodic.iterate(), использование библиотеки APOC (Awesome Procedures on Cypher), о которой мы писали здесь, менее эффективно, чем нативные Cypher-запросы. Процедуры APOC обрабатывают Cypher-запросы как строковые параметры без поддержки синтаксиса языковым сервером Neo4j. Их сложнее читать, чем нативные Cypher-запросы. Кроме того, процедуры APOC должны проходить через весь стек Cypher для каждого выполнения оператора. Поскольку APOC является внешней библиотекой, при ее использовании планировщик Cypher имеет меньше возможностей для оптимизации запросов, а среда выполнения Cypher имеет меньше возможностей для управления памятью.
Поэтому в августе 2024 года разработчики графовой базы данных Neo4j добавили возможность параллельного выполнения нескольких Cypher-запросов, назвав ее CICT (CALL IN CONCURRENT TRANSACTIONS). Как она работает и чем отличается от своей предшественницы, функции CIC, рассмотрим далее.
CIT vs CICT
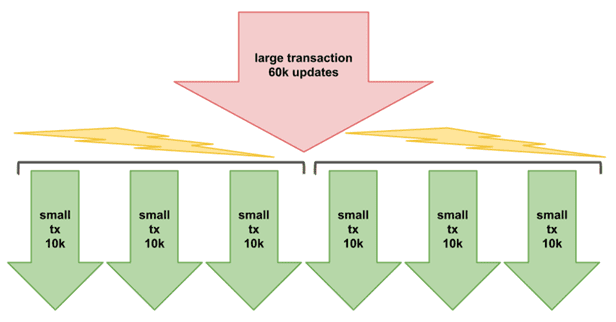
Функция CICT дает официальный синтаксис Cypher для выполнения пакетных подзапросов, сгенерированных CIT-подзапросом, в нескольких потоках ЦП, используя аналогичный подход к параллельной среде выполнения и распределяя доступную работу по пулу рабочих процессов.
Предположим, есть большой набор данных: множество узлов с меткой Person и свойством age, в котором нужно увеличить возраст каждого человека на 1 год. Чтобы выполнить это транзакционное обновление по частям, можно использовать конструкцию CALL { … } IN TRANSACTIONS для выполнения операции по частям:
CALL {
MATCH (p:Person)
RETURN p
} IN TRANSACTIONS OF 1000 ROWS
CALL {
WITH p
SET p.age = p.age + 1
} IN TRANSACTIONS
В этом примере внешний запрос выбирает узлы по 1000 строк за раз, а внутренний запрос обновляет свойство age для каждого узла в отдельной транзакции.
Для более гибкой обработки данных можно передавать параметры в запрос. Например, нужно обновить только тех людей, чей возраст больше определенного значения, установленного в параметре $minAge. Параметр $minAge может быть передан в запрос для фильтрации узлов:
CALL {
MATCH (p:Person)
WHERE p.age > $minAge
RETURN p
} IN TRANSACTIONS OF 500 ROWS
CALL {
WITH p
SET p.age = p.age + 1
} IN TRANSACTIONS
Функция CIT использует упорядоченную семантику по умолчанию, где пакеты фиксируются в последовательном порядке строка за строкой. А CICT использует параллельную семантику, где количество строк, зафиксированных определенным пакетом, и порядок самих зафиксированных пакетов не определены. Поэтому результаты CALL-подзапросов, выполняемых в параллельных транзакциях, могут быть недетерминированными, т.е. могут возвращать разные результаты. Чтобы гарантировать детерминированные результаты, результаты подтвержденных пакетов не должны зависеть друг от друга. Таким образом, CICT-конструкция может стать причиной ошибки или некорректного вычисления.
В частности, если используется ON ERROR BREAK или ON ERROR FAIL и одна транзакция терпит неудачу, то никакие параллельные транзакции не могут быть прерваны и откатаны назад, хотя все последующие будут. Это связано с тем, что для параллельных транзакций не может быть предоставлено никаких гарантий по времени. Текущая транзакция может или не может быть успешно зафиксирована в окне времени, когда обрабатывается ошибка. Чтобы определить, какие пакеты были зафиксированы, а какие не были выполнены или не были запущены, надо смотреть отчет о состоянии выполнения внутренних транзакций с помощью конструкции REPORT STATUS AS var.
CICT-функция будет особенно полезна для больших и длительных операций загрузки данных, таких как LOAD CSV, где оператор использует большой объем транзакционной памяти и генерирует большое количество пакетов. CICT также пригодится при удалении большого объема данных. Однако, при удалении сложных графовых структур одновременно могут возникнуть блокировки, что приводит к тупикам. Поэтому более целесообразно вернуться к однопоточному удалению с большими размерами пакетов. Для изоляции транзакций Cypher, чтобы избежать работы с данными, которые только что были обновлены, вставляет Eager Operator для границ выполнения транзакции, чтобы выполнить все операции до того, как можно будет запустить следующую операцию. Это также может вызывать проблемы с чрезмерным использованием памяти до начала операции обновления. В таких случаях имеет смысл вернуться к методу APOC-библиотеки apoc.periodic.iterate(), который имеет другую семантику выполнения.
В заключение отметим еще некоторые ограничения CICT-функции:
- Вложенные предложения внутри подзапроса не поддерживается;
- Не поддерживается оператор UNION, который объединяет результаты двух или более запросов в один набор результатов, включающий все строки, принадлежащие всем запросам в объединении;
- запись данных может быть только внутри конструкции CALL { … } IN TRANSACTIONS.
Тем не менее, несмотря на эти ограничения, конструкция CALL { … } IN TRANSACTIONS в Neo4j позволяет выполнять вложенные запросы в транзакциях, что особенно полезно для обработки больших объемов данных. Она разбивает крупные операции на более мелкие, которые выполняются последовательно, но в разных транзакциях. Это позволяет избежать проблем с производительностью и блокировками графовой базы данных и дает больше контроля над процессом выполнения, а также возможность обработки больших наборов данных, таких как массовые обновления или вставки, без перегрузки системы.
Научиться использовать графовые СУБД для аналитики больших данных вам помогут специализированные курсы нашего лицензированного учебного центра обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://neo4j.com/developer-blog/concurrent-writes-cypher-subqueries/
- https://neo4j.com/labs/apoc/4.4/overview/apoc.periodic/apoc.periodic.iterate/
- https://neo4j.com/docs/cypher-manual/current/introduction/cypher-neo4j/#cypher-neo4j-transactions
- https://neo4j.com/docs/cypher-manual/current/subqueries/subqueries-in-transactions/

