Зачем в ClickHouse 24.6 добавлена настройка optimize_row_order для оптимизации порядка строк MergeTree-таблиц, как она работает и где ее применять.
Как связаны индексация и сортировка таблиц в ClickHouse
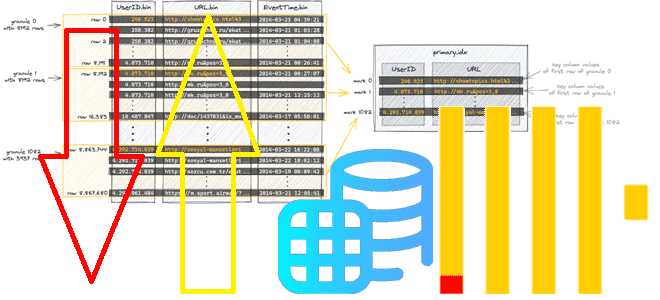
Даже не будучи классической реляционной СУБД, ClickHouse поддерживает индексацию, насколько это возможно в его колоночной природе, индексируя первичным ключом целую группу строк (гранулу) в таблице из частей данных, отсортированных по первичному ключу. Подробнее об этом мы писали здесь. Физический порядок строк на диске в таблицах основного движка MergeTree определяется их ключом сортировки, указанном в операторе ORDER BY. Оператор ORDER BY и связанный с ней физический порядок строк используются для создания разреженного индекса в диапазонных запросов и определения ключ для режимов слияния, например, таблиц Aggregating- или ReplacingMergeTree. Также физический порядок строк обеспечивает улучшенное сжатие данных путем их совместного размещения в файлах столбцов. Это особенно важно при работе с огромными объемами данных, для чего изначально и создавался ClickHouse.
Чтобы сжимать данные еще более эффективно, для обычных MergeTree-таблиц в релизе 24.6, выпущенном в начале июля 2024 года, добавлен новый параметр optimize_row_order. После сортировки по столбцам с помощью ORDER BY он автоматически сортирует строки таблицы во время приема данных по оставшимся столбцам на основе их мощности, обеспечивая оптимальное сжатие. Популярные кодеки сжатия, такие как LZ4 и ZSTD достигают максимальных показателей, если данные имеют закономерность, например, длинные последовательности (серии) одинаковых значений в каждом столбце. Оптимизация достигается благодаря физическому хранению строк, отсортированных по значениям столбцов, начиная со столбцов с наименьшей кардинальностью. Для диапазона строк с одинаковыми значениями столбцов ORDER BY строки сортируются по значениям оставшихся столбцов, упорядоченных по диапазону и локальному количеству столбцов в порядке возрастания. Раньше, при упорядочивании строк по значениям столбцов с высокой кардинальностью, их было невозможно сортировать на основе значений других столбцов для создания длинных серий одинаковых значений, что приводило к низкому коэффициенту сжатия файлов столбцов. Изменения в ClickHouse 24.6 устраняют эту проблему: параметр optimize_row_order улучшает сжатие данных при вставке в таблицы движка MergeTree. Как это работает, посмотрим далее.
Настройка optimize_row_order в релизе 24.6
Новый метод оптимизации в ClickHouse не пытается полностью оптимизировать порядок строк, а сортирует строки внутри так называемых классов эквивалентности – групп строк с одинаковыми значениями в первичных ключах. Для каждой такой группы строки сортируются по значениям столбцов, не являющихся первичными ключами. Это уменьшает количество переходов между значениями и увеличивает длину последовательностей одинаковых значений, лучше сжимая данные.
Как уже было отмечено выше, эта настройка подходит для таблиц без первичных ключей или с первичными ключами с небольшим числом уникальных значений. Если первичный ключ имеет много уникальных значений, например, временные метки, особого смысла от этой настройки не будет. Также настройка подойдет для обычных MergeTree-таблиц с ключом ORDER BY с низкой кардинальностью, т.е. с несколькими различными значениями ключа сортировки.
Например, следующий DDL-запрос создает таблицу user_events для хранения данных о пользователях, посещенных ими веб-страницах, событиях пользовательского поведения и времени этих событий.
CREATE TABLE user_events
(
UserID UInt32,
URL String,
Event String,
EventTime DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS optimize_row_order = 1;
В этой таблице комплексный первичный ключ состоит из двух столбцов: идентификатора пользователя UserID и URL веб-страницы. Данные в таблице будут отсортированы по столбцам UserID, URL и EventTime. Это означает, что записи будут физически располагаться в указанном порядке, что ускоряет выполнение запросов фильтрации или сортировки по этим столбцам. Настройка optimize_row_order = 1 включает оптимизацию порядка строк: ClickHouse пытается переставить строки так, чтобы одинаковые значения шли подряд, что улучшает сжимаемость. В этом примере одинаковые значения будут часто встречаться в столбцах UserID, URL и Event. Поэтому включение оптимизации порядка строк при создании таблицы с событиями пользовательского поведения отлично подходит для сценариев фильтрации и поиска событий пользователей с учетом хронологического порядка.
Новая оптимизация с помощью optimize_row_order применяется только к частям данных, созданным во время вставки, но не во время слияний частей. Впрочем, большинство слияний обычных MergeTree-таблиц просто объединяют неперекрывающиеся диапазоны ключа ORDER BY, поэтому уже оптимизированный порядок строк чаще всего сохраняется.
Бенчмаркинговые тесты показали, что сжатие данных с новой настройкой улучшается примерно на 30%. Однако, включение optimize_row_order добавляет дополнительные затраты на процесс вставки данных, увеличивая время вставки на 30-50%, но улучшает показатели сжатия на 20-40%. О том, какие новые возможности представлены в следующем релизе этой колоночной СУБД, читайте в нашей статье про ClickHouse 24.7.
Освойте использование ClickHouse для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

