 1177
1177 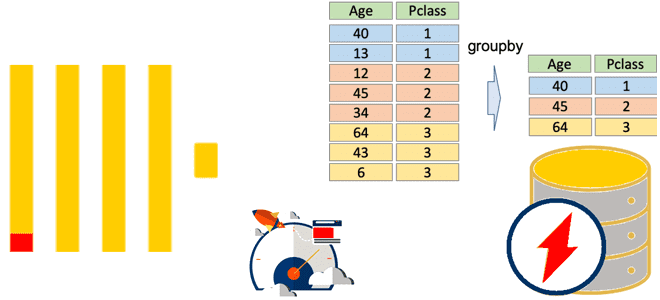
Содержание
Как работают агрегатные функции в ClickHouse, почему SQL-запросы с GROUP BY потребляют много памяти и что поможет сделать их быстрее и эффективнее: лайфхаки многопоточной агрегации в колоночной базе данных.
Особенности выполнения оператора GROUP BY в ClickHouse
Агрегатные функции позволяют вычислить экстремум (минимум/максимум), среднее значение, количество, сумму или другое результирующее значение в группе. Агрегации необходимы для аналитики данных, поэтому ClickHouse поддерживает не только стандартные агрегатные функции (count, min, max, sum, avg, any, stddevPop, stddevSamp, varPop, varSamp, covarPop, covarSamp), но специфичные для этого колоночного хранилища данных. Поскольку агрегации вычисляются по группе значений, перед использованием функции данные надо сгруппировать с помощью SQL-оператора GROUP BY.
В отличие от операторов DISTINCT и LIMIT BY, GROUP BY в ClickHouse является многопоточным, возвращая результат только по завершении агрегации. В GROUP BY указывается ключевое выражение (ключ группировки) – одно или несколько значений, по которым будут группироваться данные для вычисления общего результата. Все выражения в операторах SELECT, HAVING и ORDER BY должны быть вычислены на основе ключевых выражений или на агрегатных функциях над неключевыми выражениями, включая столбцы. Каждый столбец, выбранный из таблицы, должен использоваться либо в ключевом выражении, либо внутри агрегатной функции, но не в обоих.
В результате агрегирования SELECT-запрос будет содержать столько строк, сколько было уникальных значений ключа группировки в исходной таблице. Обычно агрегация значительно уменьшает количество строк, часто на порядки, но не обязательно: количество строк остается неизменным, если все исходные значения ключа группировки были различны. Если запрос содержит столбцы исходной таблицы только внутри агрегатных функций, то можно обойтись и без GROUP BY, выполняя агрегирование по пустому набору ключей. В этом случае всегда возвращается только одна строка. Чтобы вычислить подытоги в агрегации, можно добавить модификатор WITH с ключевым словом ROLLUP, CUBE или TOTALS. В отличие от многих других СУБД, отсутствующее значение (NULL) ClickHouse при агрегации интерпретирует как обычное, то есть NULL==NULL.
По умолчанию ClickHouse выполняет агрегацию в памяти с помощью хэш-таблицы, которая имеет более 40 специализаций, выбираемых автоматически в зависимости от типа данных ключа группировки. ClickHouse использует неблокируемые хэш-таблицы, поэтому каждый поток имеет как минимум одну хэш-таблицу. Это позволяет не беспокоиться о синхронизации между несколькими потоками, но имеет потребляет много памяти и требует объединения хэш-таблиц для каждого потока, снижая производительность при группировке множества различных ключей. Поэтому, чтобы распараллелить слияние хэш-таблиц, т.е. выполнить такое слияние через несколько потоков, ClickHouse использует сперва создает 256 блоков для каждого потока (определяется одним байтом хэш-функции), а затем объединяет эти 256 блоков независимо несколькими потоками.
Как повысить эффективность группировки
При выполнении GROUP BY во внешней памяти ClickHouse выгружает эти блоки на диск, чтобы потом считать их оттуда и объединить. Поэтому для выполнения агрегатных функций оперативной памяти должно быть достаточно для хранения одного блока.
Если добавить сортировку при выполнении агрегаций, они могут выполняться более эффективно, если выражение GROUP BY содержит ключ сортировки или инъективную функцию с этим ключом. В таких случаях в момент считывания из таблицы нового значения ключа сортировки промежуточный результат агрегирования будет финализироваться и отправляться на клиентскую машину. Чтобы включить такой способ выполнения запроса, надо настроить параметр optimize_aggregation_in_order. Подобная оптимизация позволяет сэкономить память во время агрегации, но может привести к увеличению времени выполнения запроса. Такое замедление случается, поскольку ClickHouse приходится считывать и обрабатывать данные в определенном порядке, что значительно усложняет распараллеливание чтения и агрегации. Но потребление памяти в таком случае намного меньше памяти, поскольку ClickHouse может передавать потоковые данные, без необходимости хранить их в памяти.
Чтобы ограничить потребление оперативной памяти при выполнении GROUP BY, можно включить сброс временных данных на диск. Для этого используется настройка max_bytes_before_external_group_by, которая определяет пороговое значение потребления оперативной памяти, по достижению которого временные данные агрегирования сбрасываются в файловую систему. По умолчанию этот параметр равен 0, что означает отсутствие сброса временных данных на диск. Если max_bytes_before_external_group_by не равен 0, то максимальное значение используемой памяти max_memory_usage рекомендуется установить приблизительно в два раза больше max_bytes_before_external_group_by. Это следует сделать, потому что агрегация выполняется в два этапа:
- чтение и формирование промежуточных данных;
- слияние промежуточных данных.
Сброс данных на файловую систему может производиться только на этапе 1. Если сброса временных данных не было, то на этапе 2 может потребляться до такого же объёма памяти, как на этапе 1. Например, если max_bytes_before_external_group_by равен X, то max_memory_usage следует задать равным 2X. На практике при срабатывании внешней агрегации, если происходит сброс временных данных в файловую систему, максимальное потребление оперативности будет чуть больше max_bytes_before_external_group_by. При распределённой обработке запроса внешняя агрегация производится на удалённых серверах. Чтобы снизить количество потребляемой памяти на сервере-инициаторе запроса, нужно установить distributed_aggregation_memory_efficient равным 1.
Поскольку оператор GROUP BY использует память хэш-таблиц, потребление RAM растет с увеличением размера ключей группировки и количества их уникальных комбинаций. Поэтому следует очень осторожно использовать функции, состояние которых может использовать неограниченный объем памяти и неограниченно расти: groupArray (groupArray(1000)()), uniqExact(uniq,uniqCombined), quantileExact (medianExact) (quantile,quantileTDigest), windowFunnel, groupBitmap, sequenceCount (sequenceMatch), Map. Если использование GROUP BY потребляет всю оперативную память, можно отладить этот SQL-запрос с помощью трассировки, установив настройку set send_logs_level=’trace’. Далее, чтобы понять, сколько памяти потребляет оператор GROUP BY, следует поочередно удалять функции агрегации из запроса, определяя наибольшее потребление RAM.
Узнайте больше про применение ClickHouse и Apache NiFi для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

