Что не так с датасетами в системах машинного обучения, с какими трудностями сталкиваются аналитики, инженеры данных и специалисты по Data Science при внедрении MLOps, почему важна согласованность различных информационных хранилищ, зачем и как внедрять оперативный мониторинг за качеством данных. Разбираем трудности разработки и поддержки Machine Learning в production. 5 проблем...
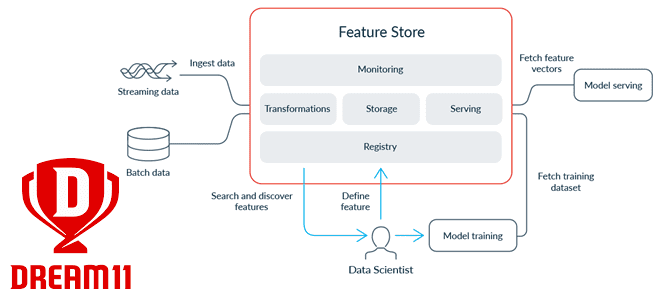
Современные ML-системы представляют собой сложные комплексные платформы из множества компонентов, одним из которых является хранилище фичей для моделей машинного обучения. Индийская gamedev-компания Dream11 делится своим опытом, как построить такое Feature Store на базе Apache HBase с Phoenix, а также RonDB и Kafka. Что такое хранилище фичей и зачем это Dream11...
Зачем нужен мониторинг ML-систем в production, чем он отличается от простого отслеживания метрик ПО и при чем здесь MLOps. Как настроить телеметрию ML-приложений в New Relic: 5 простых шагов для специалистов по Machine Learning и дата-инженеров. Зачем нужен мониторинг ML-систем и при чем здесь MLOps В реальных системах машинного обучения...
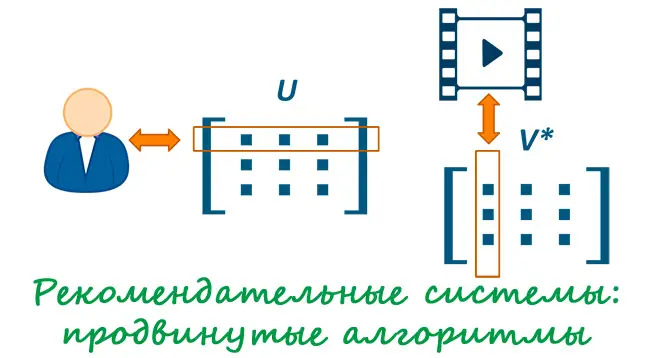
В прошлой статье мы разобрали методы построения рекомендательных систем: коллаборативная фильтрация; фильтрация на контенте; фильтрация на знаниях; гибридный подход. Мы намеренно не упомянули об одном важном подходе построения рекомендаций: об использовании матричных разложений. Описание данного метода заслуживает отдельной статьи! Будем эксплуатировать традиционный для рекомендательных систем кейс рекомендации фильмов пользователям. Напомним,...
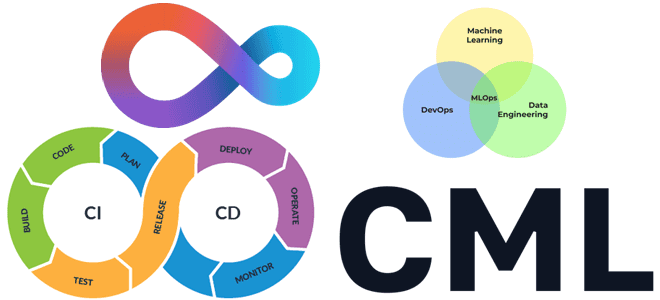
Что такое непрерывное машинное обучение, как оно работает и при чем здесь MLOps. Почему сложно вести разработку ML-моделей в стиле CI/CD и как CML помогает обойти эти ограничения. Автоматизация процессов непрерывной интеграции и доставки с помощью open-source CLI-инструмента от Iterative.ai. Трудности CI/CD в Machine Learning и MLOps Поддерживаемые DevOps-концепцией идеи...

Как быстро и эффективно с помощью Neo4j выявить преступников, незаконно ввозящих в страну контрафактные товары. Почему графовая СУБД Neo4j обошла документо-ориентированную MongoDB, из чего состоит алгоритм поиска рецидивистов средствами технологий аналитики больших данных и как это может пригодиться в других бизнес-приложениях. Постановка задачи: сложности отслеживания контрафакта Каждый день практически в...
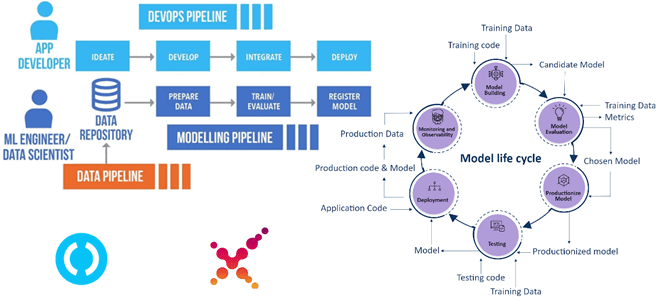
Чтобы сделать наши курсы для специалистов в области Data Science и ML-инженеров еще более полезными, сегодня рассмотрим, как организовать сквозной CI/CD-конвейер разработки и развертывания системы машинного обучения в соответствии с MLOps-концепцией на 4-х популярных Python-инструментах: MLflow, DVC, Airflow, ClearML. А в качестве примера практической реализации этой идеи разберем кейс банка...
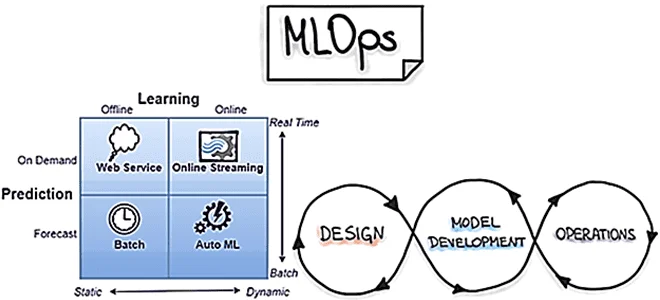
Сегодня рассмотрим наиболее распространенные в MLOps стратегии развертывания, т.е. подходы к внедрению моделей машинного обучения в производство. Выбор стратегии зависит от бизнес-требований и от контекста применения результатов ML-моделирования. Какие бывают стратегии и как они реализуются: краткий ликбез с примерами для ML-инженеров и MLOps-специалистов. Пакетное прогнозирование и веб-сервисы для MLOps Это...

Недавно мы писали про рекомендательную систему американской медиа-компании Meredith Corporation на основе графовой СУБД Neo4j и алгоритма непересекающихся множеств (Union-Find). Продолжая эту тему в рамках нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, как построить простой рекомендательный движок с помощью выражений и операторов языка запросов Cypher...
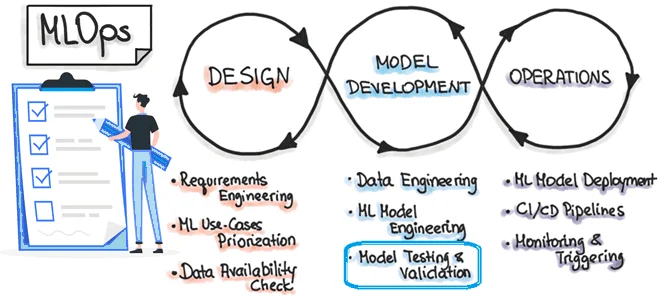
Поскольку разработка и развертывание ML-систем отличаются от традиционного ПО, о чем мы писали здесь и здесь, процесс тестирования модели машинного обучения тоже имеет свою специфику, которую учитывает концепция MLOps. Читайте далее, что и как тестировать при разработке систем Machine Learning, а также при чем здесь подход Arrange-Act-Assert. MLOps и тестирование...