 179
179 
Что такое непрерывное машинное обучение, как оно работает и при чем здесь MLOps. Почему сложно вести разработку ML-моделей в стиле CI/CD и как CML помогает обойти эти ограничения. Автоматизация процессов непрерывной интеграции и доставки с помощью open-source CLI-инструмента от Iterative.ai.
Трудности CI/CD в Machine Learning и MLOps
Поддерживаемые DevOps-концепцией идеи непрерывной интеграции и доставки (CI/CD, Continuous Integration/Delivery), когда разные группы разработчиков разрабатывают приложение, постоянно интегрируя новые изменения, исправляя ошибки, а также добавляя улучшения, отлично применяются в процессах создания традиционного ПО. Например, в рамках создания простого веб-приложения команда будет состоять из фронтенд-и бэкенд-разработчиков, администраторов баз данных и инженеров по развертыванию. У каждой профильной группы будут свои репозитории кода на GitHub или в каком-либо сервисе хостинга репозиториев. По мере внесения изменений в код и исправления ошибок разработчики начнут добавлять код в ветки функций и исправлений. После проверки кода создается запрос на включение изменений в основную ветку; после слияния последнего кода запускается конвейер для сканирования и тестирования кода, после чего программный код может быть упакован и развернут.
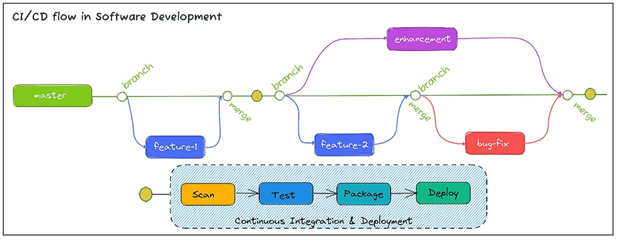
Однако, в случае разработки системы Machine Learning все не так просто, о чем мы уже подробно писали здесь и здесь. Помимо разработки и тестирования самого программного кода, много времени и усилий уходит на валидацию данных для обучения, а также саму математику ML-моделей. При этом производительность системы сильно зависит от обучающего и валидационного датасетов. Дополнительную сложность добавляет отсутствие четких широко известных паттернов – в отличие от разработки ПО по стандартизованным архитектурам, в ML пока не сложились общепринятые шаблонов проектирования, и каждая команда может следовать своему собственному стилю. Более того, для решения одной и той же задачи фактически можно использовать несколько разных классификаторов и алгоритмов. Частично эти вопросы решает концепция MLOps как набор практик, направленных на надежное и эффективное развертывание и поддержку моделей машинного обучения в производственной среде. Однако, вопрос про машинное обучение в стиле непрерывной интеграции остается открытым. Именно здесь поможет так называемое непрерывное машинное обучение или CML (Continuous Machine Learning). Что это такое и как работает, мы рассмотрим далее.
Что такое CML и как это работает
Инструментально CML — это CLI-средство с открытым исходным кодом от Iterative.ai для реализации CI/CD в рамках MLOps. Оно подходит для автоматизации рабочих процессов разработки ML-моделей, включая их предоставление, обучение и оценку, сравнение экспериментов в истории проекта и мониторинг меняющихся наборов данных. CML основан на следующих принципах:
- GitLab или GitHub для управления экспериментами ML, мониторинга обучения моделей и изменения данных с помощью DVC;
- автоматические отчеты для экспериментов машинного обучения с метриками и графиками в каждом pull-запросе Git, чтобы принимать обоснованные решения на основе данных;
- отсутствие дополнительных сервисов – только GitLab, Bitbucket или GitHub, Docker и DVC. При желании можно добавить облачные хранилища, а также самостоятельные или облачные исполнители типа AWS EC2 или MS
Рассмотрим типовой процесс запуска модели ML в производство: группа специалистов по Data Science работает над проблемой, извлекает данные, строит модель, обучает ее, тестирует и оценивает. При этом Data Scientist’ы рассматривают ML-модель со следующих точек зрения, задавая себе и коллегам следующие вопросы:
- может ли модель, созданная одним ML-инженером, быть воспроизведена другими в разных системах и средах;
- используется ли правильная версия данных для обучения;
- поддаются ли проверке показатели производительности модели?
- как отслеживать и обеспечивать улучшение модели;
- как обеспечить правильную среду для обучения, учитывая возможность снижения затрат на облачные CPU/GPU, нужные только на время обучения;
- есть ли отчет с подробной информацией для последующего сравнения по завершении этапа обучения;
- какие проверки происходят и как они выполняются при переобучении модели.
CML помогает ответить на все эти вопросы, помогая обеспечивать введение непрерывного рабочего процесса для предоставления облачных экземпляров, обучения и оценки производительности ML-модели, сбора метрик и публикации сводных отчетов. Это позволяет разработчикам ввести серию контрольных точек, которые легче отслеживать и воспроизводить в различных сценариях. Примечательно, что CML не требует дополнительного технического стека и работает с помощью всего пары строк кода, которые легко интегрируются в существующий процесс разработки. Это повышает прозрачность создания ML-системы: любой Data Scientist имеет доступ к нескольким отчетам об обучении и метрикам для сравнения и оценки моделей Machine Learning. Таким образом, команды могут быстрее разрабатывать и запускать модели в производство, сокращая количество ручных доработок, связанных с исправлением при ухудшении производительности.
CML внедряет в рабочий процесс автоматизацию в стиле CI/CD: большинство конфигураций определены в файле cml.yaml, хранящемся в репозитории. Этот файл указывает, какие действия должны быть выполнены, когда новая функциональная ветка готова к слиянию с основной. Когда создается pull-запрос, действия GitHub используют этот рабочий процесс и выполняют действия, указанные в файле конфигурации, например запускают файл train.py или создают отчет о точности.
CML работает с набором функций, которые представляют собой предопределенные фрагменты кода, которые помогают рабочему процессу, например, позволяют публиковать отчеты в виде комментариев или запускают облачный сервис для выполнения отдельных операций.
Предположим, несколько специалистов по Data Science работают над созданием классификатора для распознавания и классификации разных фруктов. Первый Data Scientist начинает с базового бинарного классификатора, который распознает фрукт и классифицирует его как «яблоко» или «не яблоко». Далее другой член команды добавляет возможность распознавания апельсина и банана, выполняя следующий набор действий:
- создать свою функциональную ветку;
- написать новый код ML-модели, запустить его обучение и протестировать на предыдущей модели;
- вставить написанный код в функциональную ветку;
- отправить запрос на слияние написанного кода с основной веткой.
CML подключается, когда делается pull-запрос, и выполняет действия, указанные в файле конфигурации cml.yaml. Создается отчет, затем команда решает, объединять ли новый код с основной веткой или нет. При этом не создается никаких дубликатов файлов, копий одной и той же записной книжки. Внутри этого конфигурационного yaml-файла будет примерно следующее:
name: model-training
on: [push]
jobs:
train-model:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: actions/setup-python@v2
- uses: iterative/setup-cml@v1
- name: Train model
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
pip install -r requirements.txt
python train.py
cat metrics.txt >> report.md
cml publish plot.png --md >> report.md
cml send-comment report.md
Этот файл cml.yaml представляет собой скрипт GitHub Actions и сообщает GitHub следующее:
- как называется рабочий процесс (обучение модели);
- когда должен выполняться этот рабочий процесс (по запросу);
- какие работы выполняются в рамках этого рабочего процесса (обучение ML-модели);
- где должен работать рабочий процесс(на GitHub runner с последней версией ОС Ubuntu);
- какие шаги процесса выполняются (обучение ML-модели);
- что нужно для выполнения этого шага (checkout, setup-python, setup-cml). Это действия, доступные на GitHub, фрагменты кода, уже написанные кем-то для выполнения задачи, которые можно использовать повторно в своем сценарии. Таким образом, пользовательский код будет проверен на временной виртуальной машине Ubuntu, на которой будут установлены python и cml.
- какие переменные среды следует использовать (REPO_TOKEN предоставляется GitHub, поэтому виртуальная машина знает, что только авторизованный репозиторий GitHub может выполнять эту задачу);
- какие команды следует выполнить на этом шаге (установить пакеты Python, запустить файл train.py, опубликовать отчеты об оценке в файле с именем report.md), включив туда данные о точности модели, показатели оценки и ошибок;
- CML-функции (cml publish и cml send-comment в последних двух строках скрипта), которые упрощают задачу создания подробного отчета об обучении модели в pull-запросе. Можно создать наглядный визуальный отчет с описанием производительности модели, чтобы Data Scientist быстрее понял, какой pull-запрос может быть одобрен для окончательного слияния.
Таким образом, разработчику новой функциональной ветки нужно лишь написать свой код, протестировать свою модель и отправить изменения в свою ветку, а затем инициировать запрос на включение. Остальные этапы оценки модели, сравнения и табулирования результатов выполняет CML. После того, как действия CML завершены, другим ML-инженерам и специалистам по Data Science доступен наглядный отчет о сеансе обучения для проверки и оценки в том же репозитории.
Если третий Data Scientist хочет использовать последний код и тренироваться со своими данными, чтобы добавить возможность давать процентную классификацию, CML также пригодится. Инструмент может использовать графический процессор CUDA для экономии времени и усилий, применяя специальное средство запуска облачных вычислений. CML позволяет подключиться к экземпляру графического процессора AWS и обучить свою модель, не тратя время и силы на настройки системы. Достаточно лишь настроить файл cml.yaml для использования настроек AWS и GPU. Затем рабочий процесс будет использовать пользовательский контейнер на основе графического процессора для обучения модели и публикации ее результатов.
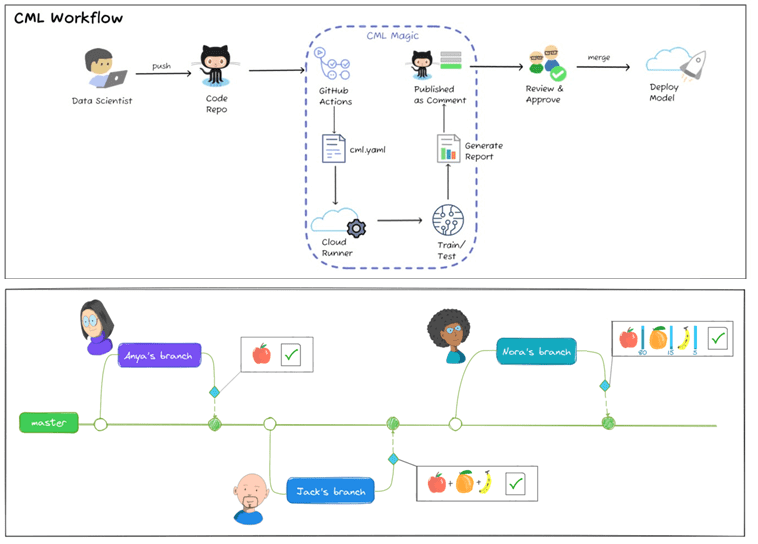
Теперь каждый раз, когда кто-то создает новую фичу, улучшая модель или производительность системы, а также исправляя ошибки, отчет об оценке будет доступен всем участникам процесса разработки во время слияния разных функциональных веток. Несколько специалистов по Data Science могут работать над параллельными версиями модели и разными алгоритмами классификатора одновременно. CML поможет в одном и том же workflow-репозитории увидеть, правильно ли обучены модели, можно ли их развернуть, и сравнить показатели. Читайте в наших следующих статьях про мониторинг ML-систем и организацию Feature Store для эффективного применения машинного обучения в реальных бизнес-задачах.
Узнайте, как внедрить лучшие практики MLOps с Apache Spark и другими инструментами аналитики больших данных, на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

