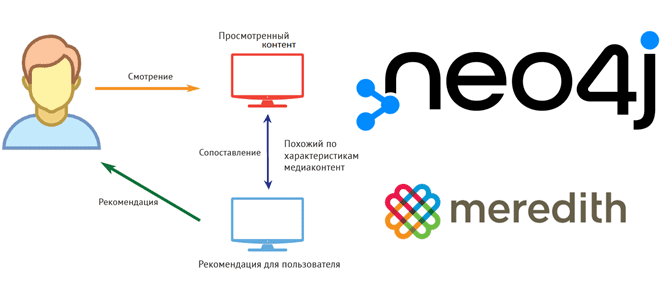
Развивая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим американского медиаконгломерат Meredith Corporation по персонализации пользовательских профилей с помощью графовой СУБД Neo4j и алгоритма непересекающихся множеств (Union-Find). Постановка задачи: сложности идентификации анонимных клиентов Различными контент-продуктами конгломерата Meredith Corporation ежемесячно пользуется более 180 миллионов человек через приложения,...

Недавно мы писали про сложности разработки и развертывания ML-систем и способы их решения с помощью концепции MLOps. Продолжая эту тему, важную для обучения специалистов по Data Science, аналитиков и инженеров данных, сегодня рассмотрим основные некоторые преимущества фреймворка MLFlow для создания надежных конвейеров CI/CD в системах машинного обучения. CI/CD в MLOps...

Мы уже рассказывали о победителях российского ИТ-конкурса «Проект Года 2020» от профессионального сообщества GlobalCIO в номинации «Аналитика и Big Data», где «Газпром нефть» и банк ВТБ делятся опытом применения российских продуктов Arenadata. Сегодня рассмотрим кейс призера 2021 года - проект «Фабрика данных» в АО «Народный банк Казахстана», в результате которого...

Постоянно добавляя в наши курсы по Apache Spark и машинному обучению практические примеры для эффективного повышения квалификации Data Scientist’ов и инженеров данных, сегодня рассмотрим задачу пакетного прогнозирования и планирование ее запуска по расписанию без применения масштабных MLOps-решений. Apache Spark для пакетного прогнозирования Есть много готовых решений и инструментов для пакетного...
Обучая специалистов по Data Science, аналитиков и инженеров данных лучшим практикам MLOps, сегодня поговорим про переносимость моделей машинного обучения между разными этапами жизненного цикла ML-систем, от разработки до развертывания в production. А в качестве примера разберем, как использовать обученную ML-модель из Apache Spark за пределами кластера, упаковав ее в ONNX...

В рамках обучения дата-инженеров и ML-специалистов лучшим практикам MLOps, сегодня рассмотрим практический пример построения конвейера машинного обучения на Airflow, MLFlow, SageMaker и других сервисах Amazon. А также как Apache Spark версии 3 сократил расходы на облачный EMR-кластер почти в 2 раза. MLOps с AirFlow и MLFlow в облаке AWS Ранее...
Практическая реализация MLOps-концепции на примере международной рекрутинговой компании Glassdoor. Как построить самоуправляемую автоматизированную систему разработки и сопровождения ML-моделей с MLFlow, Apache Spark и AirFlow, Kubernetes, GitLab, SageMaker Feature Store, Whylogs, Jenkins, Spinnaker и Prometheus с Grafana. Предыстория: зачем MLOps в Glassdoor Glassdoor с 2008 года помогает соискателям по всему миру...

Дополняя наши курсы по аналитике больших данных в бизнес-приложениях новыми полезными примерами, сегодня рассмотрим, как Apache Arrow помогает повысить производительность извлечения данных из Neo4j с помощью их колоночного представления и обработки в памяти, а не на диске. Чем neo4j-arrow лучше драйверов Java и Python, а также собственной Neo4j библиотеки Graph...

2022 год только начался, а John Snow Labs уже радует разработчиков ML-приложений новым релизом библиотеки Spark NLP. Ключевые фичи 3.4.0 для версии Apache Spark 3.2.x на Scala 2.12: новые GPT-2 трансформеры, аннотаторы для ALBERT, XLNet, RoBERTa, XLM-RoBERTa и Longformer, расширенный хаб готовых Machine Learning моделей и конвейеров, а также исправление...
В этой статье разберем кейс бразильской фудтех-компании Ifood по реализации микросервисной ML-системы на Apache Kafka и serverless NoSQL-СУБД DynamoDB с пропускной способностью миллиарды сообщений в секунду. Сложности масштабирования микросервисов и оперативное чтение данных из Feature Store с помощью библиотеки Sarama – Go-клиента для Apache Kafka. Проблема микросервисов при множестве обращений...