 652
652 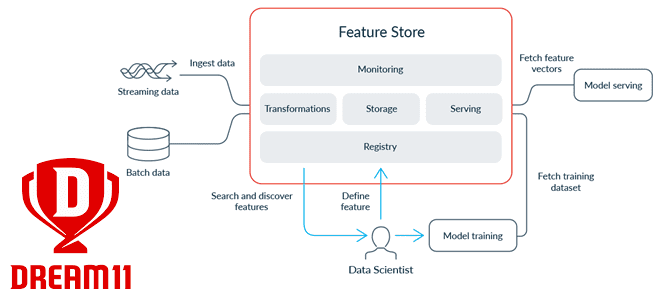
Содержание
Современные ML-системы представляют собой сложные комплексные платформы из множества компонентов, одним из которых является хранилище фичей для моделей машинного обучения. Индийская gamedev-компания Dream11 делится своим опытом, как построить такое Feature Store на базе Apache HBase с Phoenix, а также RonDB и Kafka.
Что такое хранилище фичей и зачем это Dream11
Dream11 – это индийская игровая платформа для фэнтези-спорта, которая позволяет пользователям играть в фэнтези-крикет, хоккей, футбол, баскетбол и другие игры. Существуя с 2008 года, сегодня она считается крупнейшей в мире и обслуживает более 120 миллионов активных пользователей. Чтобы повысить удовлетворенность клиентов, в Dream11 используется множество алгоритмов машинного обучения, которые создаются и поддерживаются разными командами Data Scientist’Ов, инженеров данных и разработчиков ПО. Чтобы повысить эффективность их работы за счет повторного использования различных наборов данных и предикторов (фичей, feature) для ML-моделей, было решено иметь централизованный репозиторий фичей (Feature Store) под названием Data Feast, чтобы консолидировано хранить, обнаруживать фичи и их метаданные, тем самым уменьшая дублирование усилий между командами.
Хранилище фичей — это продукт платформы данных, который упрощает создание, поиск, развертывание и использование фичей для различных вариантов использования. Feature Store обрабатывает, хранит и обслуживает данные, поддерживающие различные варианты использования моделей машинного обучения и платформы данных о клиентах. Оно помогает преобразовывать необработанные данные в значения фичей, сохранять их и использовать для обучения моделей и онлайн-выводов, снижая дублирование с помощью согласованного реестра или каталог для поиска сведений об имеющихся фичах. Хранилище фичей помогает свести к минимуму дублирование усилий по обработке данных, ускорить запуск ML-моделей в производство и улучшить сотрудничество между группами специалистов по обработке и анализу данных.
Инженеры Dream11 выделили 5 основных компонентов Feature Store:
- само хранилище, которое предоставляет возможности для хранения и извлечения данных о фичах для ML-моделей;
- уровень обслуживания, который отвечает за предоставление данных о фичах в согласованном формате;
- реестр, который позволяет стандартизировать определения фичей и метаданные для обнаружения и служит единым источником достоверной информации о фичах;
- инструменты мониторинга и оповещений, о важности которых мы недавно писали. Средства мониторинга и оповещения рассчитывают все показатели хранимых и обслуживаемых данных, описывая правильность и качество рассматриваемых фичей, а также генерируют уведомления в случае ошибок или критических отклонений фактов от плана.
- средства преобразования данных для создания новых фичей, которые затем могут использоваться моделями для вывода и прогнозирования.
Как все эти компоненты были реализованы в Dream11, мы рассмотрим далее.
Особенности реализации
Инженеры Dream11 выделили в хранилище фичей два основных уровня хранения — онлайн и оффлайн, чтобы поддерживать различные потребности в выводе и обучении моделей.
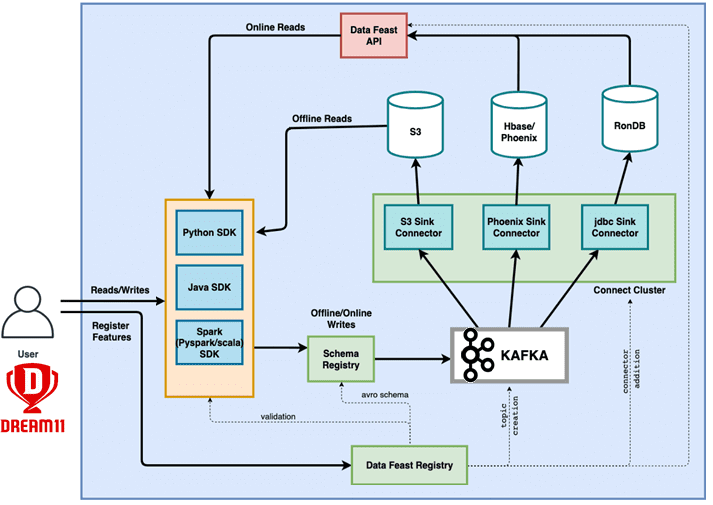
Уровень онлайн-хранилища должен иметь высокий потенциал пропускной способности порядка несколько миллионов запросов на чтение в секунду и возможности чтения с малой задержкой не более пары миллисекунд. Обычно они реализуются с помощью key-value хранилищ, к которым относится Apache HBase – популярная колоночная NoSQL-СУБД, которая работает поверх распределенной файловой системы HDFS и обеспечивает возможности BigTable для Hadoop, реализуя отказоустойчивый способ хранения больших объёмов разреженных данных. HBase обеспечивает случайный доступ в реальном времени к данным в Hadoop в сочетании с удобством пакетной обработки. Apache HBase не поддерживает язык SQL-запросов, но это ограничение легко устраняется за счет Phoenix – SQL-движка, который отлично интегрирован с HBase и выступает в качестве SQL-интерфейса для этого NoSQL-хранилища.
Сперва именно комбинация Apache HBase с Phoenix использовалась в Dream11 в качестве Feature Store. Но по мере роста числа пользователей и масштабов обрабатываемых данных, производительность этого решения стала снижаться из-за ограничений серверов запросов Apache Phoenix, развернутых на узлах AWS EMR.
Поэтому инженеры Dream11 пришли к выводу, что одно хранилище не может полностью решить все задачи Feature Store. Чтобы удовлетворить требования к очень высокой пропускной способности и задержке в миллисекундах, было решено организовать второе Feature Store на RonDB. RonDB — это хранилище ключей и значений с возможностями SQL на основе на NDB Cluster, также известном как MySQL Cluster. Изначально созданный в Ericsson в 1980-х годах, NDB зарекомендовал себя во множестве телекоммуникационных проектов благодаря параллельной обработке запросов, отличной масштабируемости чтения и записи, а также высокому классу доступности (менее 30 секунд простоя в год) за счет 2-х уровней репликации.
RonDB обеспечивает согласованность данных в больших кластерах, дает предсказуемое время отклика, предоставляет гибкий API и множество популярных интерфейсов (MySQL, LDAP, файловой системы). Таким образом, RonDB удовлетворял всем требованиям Dream11 относительно низкой задержке и высокой масштабируемости. Поэтому именно эта СУБД была выбрана в качестве онлайн-уровня хранилища фичей в дополнение к офлайн-уровню на HBase с Phoenix.
Для офлайн-уровня все данные о фичах хранятся в AWS S3 в формате Parquet. Данные хранятся на уровне группы фич и разделены на фичи, версию и дату для упрощения запросов. Также поддерживается дедуплицированная копия значений признаков в дельта-формате для более быстрой автономной обработки данных в массовом/пакетном режиме.
Для обеспечения согласованности данных на обоих уровнях хранилища (онлайн и офлайн) используются кластеры Apache Kafka. Все данные, которые необходимо записать в Feature Store, можно просто опубликовать в Kafka. Эта дает большую гибкость для реализации потребителей и использования Kafka для передачи данных в несколько источников данных, т.е. онлайн- и офлайн-хранилища фичей. Так обеспечивается доступность данных в обоих хранилищах и отсутствие несоответствий в данных между онлайн- и офлайн-уровнями хранения.
Уровень обслуживания представлен масштабируемым сервисом REST API (Data Feast API) с малой задержкой, а также SDK на Python и Java для поддержки всех кодовых баз. За счет интеграции с реестром REST API знает, какая фича хранится в каком хранилище данных, поэтому быстро извлекает ее по запросу пользователя и предоставляет результат.
Реестр (Data Feast Registry) хранит все метаданные фичей: имя, описание, владелец, домен, команда, уровень хранения (офлайн/онлайн или оба), версии, типы данных и пр. Некоторые автоматизированные задания используют реестр для планирования и настройки приема данных и хранения фичей. Обслуживающие API используют реестр для получения информации о том, какие значения фич доступны, где их найти и как получить доступ к ним. Служба реестра предоставляет API для добавления, редактирования, удаления и извлечения метаданных о фичах и их группах и поддерживает источник достоверных данных. Это помогает сделать весь процесс регистрации фич и поиска метаданных максимально самостоятельным. Также используется реестр объединенных схем для поддержки схемы потока данных (Schema Registry) в Kafka и из него. Наконец, сервис реестра отвечает за другие операционные задачи, такие как регистрация схем объектов в реестре объединенных схем, создание топика Kafka и добавление коннектора приемника через Kafka Connect.
Мониторинг, оповещение и трансформации
Есть две основные категории метрик, которые необходимо зафиксировать, чтобы узнать состояние и работоспособность хранилища фичей: операционные метрики производственной системы в целом и метрики, связанные с данными, такие как data quality, свежесть, дрейф и пр. Инженеры Dream11 отслеживают показатели, связанные с хранилищем (доступность, емкость, использование), обслуживанием фичей (пропускная способность, задержка, частота ошибок) и приемом данных в Feature Store (показатель успешности выполнения заданий, пропускная способность, задержка обработки). Определены пороговые значения для этих показателей, которые вызывают инцидент и формируют уведомления ответственным инженерам, чтобы они могли оперативно принять меры по устранению нарушений. Также сейчас создается решение для сбора метрик, связанных с данными, включая проверку их актуальности и профилирование.
За трансформацию имеющихся и создание новых фичей в рамках интеграции конвейеров данных отвечает продукт собственной разработки Data Titan. Он позволяет выполнять вычисления данных в различных хранилищах данных с возможностью запуска федеративных запросов в пакетном и потоковом режимах. Data Titan Batch позволяет выполнять вычисления с пакетными данными из различных источников, таких как корпоративное озеро или различные хранилища данных. Data Titan может напрямую запускать вычисления в источнике данных и использует Apache Spark для выполнения федеративных запросов на основе источников данных и мест назначения.
В режиме реального времени Data Titan позволяет выполнять вычисления с такими источниками данных как Apache Kafka, и сохранять данные в Data Feast. За вычисления в реальном времени отвечает Apache Flink.
В перспективе инженеры Dream11 планируют интегрировать в Data Feast форматы Delta или Apache Hudi, чтобы перемещать данные объектов во времени. Также ведется работа над созданием компонента мониторинга, профилирования и оповещения о фичах, чтобы заранее предупреждать проблемы, связанные с данными.
Узнайте больше подробностей по администрированию и использованию Apache HBase для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
[elementor-template id=»13619″]
Источники

