 782
782 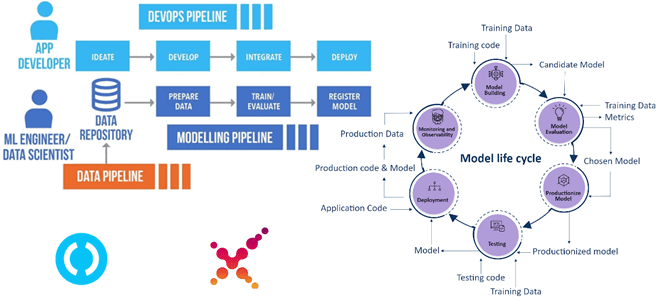
Содержание
Чтобы сделать наши курсы для специалистов в области Data Science и ML-инженеров еще более полезными, сегодня рассмотрим, как организовать сквозной CI/CD-конвейер разработки и развертывания системы машинного обучения в соответствии с MLOps-концепцией на 4-х популярных Python-инструментах: MLflow, DVC, Airflow, ClearML. А в качестве примера практической реализации этой идеи разберем кейс банка «Открытие» и ИТ-интегратора NeoFlex по созданию корпоративной MLOps-платформы.
Идеи и инструменты реализации непрерывного конвейера Machine Learning
Напомним, концепция MLOps представляет собой набор практик, направленных на надежное и эффективное развертывание и поддержку моделей машинного обучения в производственной среде. Это предполагает следующий сквозной цикл шагов:
- определение проблем машинного обучения согласно бизнес-потребностям и целям;
- сбор и подготовка данных для обучения ML-модели;
- поиск архитектуры ML-решения и разработка алгоритмов обучения моделей;
- развертывание моделей Machine Learning;
- непрерывный мониторинг, оптимизация и поддержание производительности работающей системы, включая обновление данных и фичей, особо важных для получения результатов.
MLOps позволяет достичь разных целей при разработке моделей Machine Learning, от проведения воспроизводимых экспериментов с обеспечением качества и управляемости, до ускорения развертывания и отслеживания особенностей эксплуатации. Чтобы повысить эффективность работы ML-инженера, необходимо сократить долю ручного труда на каждом этапе, автоматизируя типовые задачи. Для этого MLOps предлагает строить различные конвейеры (pipeline):
- конвейер данных;
- конвейер машинного обучения;
- конвейер CI/CD с подходами переобучения.
Каждый раз при изменении данных, кода или поведения модели в рабочей среде, эти конвейеры должны перезапускаться автоматически. Для этого существуют специализированные инструменты, такие как MLFlow, dvc, ClearML, Apache Airflow, KubeFlow, Kedro, GitHub Actions, Docker и пр. Примечательно, что все они поддерживают основной язык программирования в Data Science проектах, Python, и доступны в виде пакетов. Рассмотрим их основные возможности:
- MLflow — платформа с открытым исходным кодом для сквозного цикла машинного обучения, включая воспроизводимые эксперименты, развертывание и центральный репозиторий моделей для отслеживания или записи кода, данных, конфигурации и результатов, упаковки кода для развертывания на любой платформе запуска и в различных средах обслуживания. Реестр обеспечивает хранение, аннотирование, обнаружение и управление различными ML-моделями в репозитории. Подробнее про MLFlow мы писали здесь.
- Airflow — популярный инструмент дата-инженера для организации ETL-конвейеров, планирования и оркестровки пакетных процессов обработки данных. Рабочие процессы представлены в виде цепочек направленного ациклического графа (DAG), вершинами которого являются отдельные задачи, выполняемые с помощью готовых или самостоятельно разработанных операторов на Python.
- ClearML — open-source платформа для отслеживания, организации и автоматизации процесса разработки машинного обучения, позволяющая разрабатывать и развертывать конвейеры в облаке или локальной среде, используя Python-фреймворки. Можно запланировать контейнерные среды с полным мониторингом, логированием, триггерами и пр.
- DVC — инструмент для управления версиями данных, построенный поверх git. Он использует дайджест сообщения для отслеживания данных, обеспечивая управляемое обновление входов для ML-моделирования.
Если объединить все перечисленные инструменты в сквозной MLOps-конвейер, он будет выглядеть следующим образом:
- модель Machine Learning обучается с использованием одного или нескольких разных алгоритмов с различными параметрами. Все прогоны регистрируются на сервере mlflow для отслеживания или мониторинга различных версий модели.
- DVC используется для отслеживания данных и создания конвейера машинного обучения в виде этапов в файле dvc.yaml. Используя команду dvc repro, можно запустить конвейер, который обнаружит изменения, запустит измененный этап и выберет лучшую модель из всех версий согласно заданному значению точности.
- Лучшая ML-модель развертывается в Docker-среде с помощью действий GitHub. Здесь конвейер CI/CD автоматизирован с помощью действий GitHub, позволяя запустить ML-конвейер с помощью одной команды.
- При производственной эксплуатации модели можно отслеживать ее производительность и изменения входящих данных. Если модель не работает должным образом или возникли какие-либо аномалии в данных, необходимо переобучить модель.
Автоматизировать весь жизненный цикл разработки и развертывания модели машинного обучения можно с использованием облачных сред, создав Docker-образ и отправив его в Docker Hub. Подобные идеи и инструменты использовались в проекте банка «Открытие» совместно с ИТ-интегратором NeoFlex, что мы рассмотрим далее.
Практический пример банковской MLOps-платформы
Всего за 1 год банк «Открытие» совместно с ИТ-интегратором NeoFlex реализовали масштабный проект по разработке и внедрению общебанковской MLOps-платформы для создания и поддержки эксплуатации моделей машинного обучения. Проект выполнялся в течение 12 месяцев, с ноября 2020 по октябрь 2021 и занял 22000 человеко-часов. Помимо значительной коммерческой выгоды от внедрения, эта работа также была отмечена дипломом победителя ежегодного ИТ-конкурса «Проект года» от профессионального сообщества GlobalCIO в номинации DataScience / Blockchain.
Реализованная на базе открытый технологий (Jupyter, MLFlow, Airflow, Kubernetes, F5, Keycloak, minio, Artifactory, ArgoCD, Vault, Gitlab, ELK, Grafana), MLOps-платформа стала одной из первых на российском банковском рынке. Она позволяет бесшовно внедрять модели машинного обучения любой сложности, от логистической регрессии до градиентного бустинга и нейросетей, в бизнес-процессы, сократив время внедрение с нескольких месяцев до пары минут. Это достигается благодаря возможности индивидуальной настройки ПО под потребности различных разработчиков ML-моделей и гибкого распределения вычислительных ресурсов. Разумеется, обеспечивается версионирование экспериментов, программного кода ML- моделей и данных.
От старта проекта до ввода платформы в промышленную эксплуатацию прошло чуть меньше года, платформа уже интегрирована со всеми системами принятия решения, продолжается интеграция с командами и проектами различных data-science подразделений компании. До конца 2022 года планируется завершить переход на эту MLOps-платформу все процессы и проекты машинного обучения Банка «Открытие».
Важным результатом стала интеграция большого количества внедряемых компонентов с открытым исходным кодом и облачных сред в единую систему разработки и эксплуатации ML-моделей с учетом требований банка к надежности, доступности и оптимизации серверных мощностей. Также была попутно проведена унификация различных библиотек и методов машинного обучения, используемых данных, инструментов и прочих MLOps-артефактов. Читайте в нашей новой статье про еще один полезный MLOps-инструмент с открытым исходным кодом, который обеспечивает непрерывной машинное обучение в стиле CI/CD.
Узнайте, как внедрить лучшие практики MLOps с Apache Spark и другими инструментами аналитики больших данных, на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

