 1701
1701 
Вместо Trino и ClickHouse: что такое StarRocks и как оно устроено, архитектура и принципы работы, сценарии использования и место в корпоративной архитектуре данных.
Архитектура и принципы работы StarRocks
Хотя ClickHouse сегодня считается одним из наиболее популярных колоночных хранилищ для аналитики больших объемов данных в реальном времени, это не единственный представитель подобных систем. В качестве альтернативы можно рассмотреть StarRocks — высокопроизводительную аналитическую базу данных с открытым исходным кодом. StarRocks поддерживает прием данных в реальном времени и пакетный импорт из данных различных источников. Подобно Trino, StarRocks также позволяет напрямую анализировать данные, хранящиеся в озерах данных, без их фактического копирования. StarRocks поддерживает ANSI SQL и протокол MySQL, что позволяет использовать его вместе с MySQL-совместимыми клиентами и BI-системами.
Аналогично ClickHouse, StarRocks имеет массово-параллельную архитектуру (MPP, Massive Parallel Processing) и полностью векторизованный механизм выполнения, а также колоночный движок хранения, который поддерживает аналитику и обновления данных в реальном времени. В БД есть полностью настраиваемый оптимизатор на основе затрат (CBO), синхронные и асинхронные материализованные представления, а также другие механизмы настройки быстрого выполнения SQL-запросов.
Благодаря колоночному механизму хранения и полностью векторизованным операторам, реализованным на C++, StarRocks в полной мере использует возможности современных многоядерных процессоров и инструкции SIMD для повышения производительности. Полностью векторизованный механизм выполнения эффективно использует вычислительную мощность ЦП, включая кэш. Колоночные вычисления сокращают количество вызовов виртуальных функций и ветвлений, что приводит к более достаточным потокам инструкций ЦП. Векторизованный механизм выполнения также полностью использует инструкции SIMD, выполняя больше операций с данными с меньшим количеством инструкций. Это повышает общую производительность операторов в десятки раз. Помимо векторизации, StarRocks использует технологию Operation on Encoded Data для непосредственного выполнения операторов над закодированными строками без необходимости декодирования. Это снижает сложность SQL и увеличивает скорость запросов более чем в 2 раза.
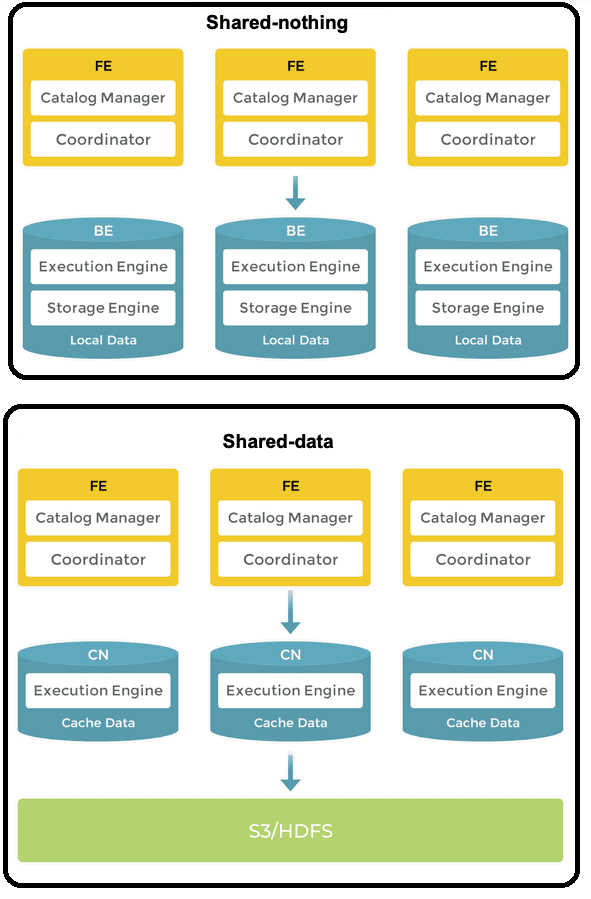
Архитектура StarRocks состоит только из двух типов компонентов: фронтендов (FE) и бэкендов (BE или CN, вычислительные узлы). Обычно для FE достаточно 8 ядер ЦП, 16 ГБ ОЗУ и не более 100 ГБ жесткого диска на каждый узел. В отличие от FE, BE более требовательны к ресурсам ЦП и памяти, особенно при работе с высококонкурентными и/или сложными запросами на больших наборах данных. Рекомендуется выделять 16 ядер ЦП и 64 ГБ ОЗУ на каждый узел BE.
Все узлы можно горизонтально масштабировать без простоя. StarRocks имеет механизм репликации для метаданных и сервисных данных, что повышает надежность данных и эффективно предотвращает появление единых точек отказа. BE развертываются, когда используется локальное хранилище для данных, а CN используются, когда данные хранятся в объектном хранилище или HDFS. БД поддерживает два режима разделения ресурсов:
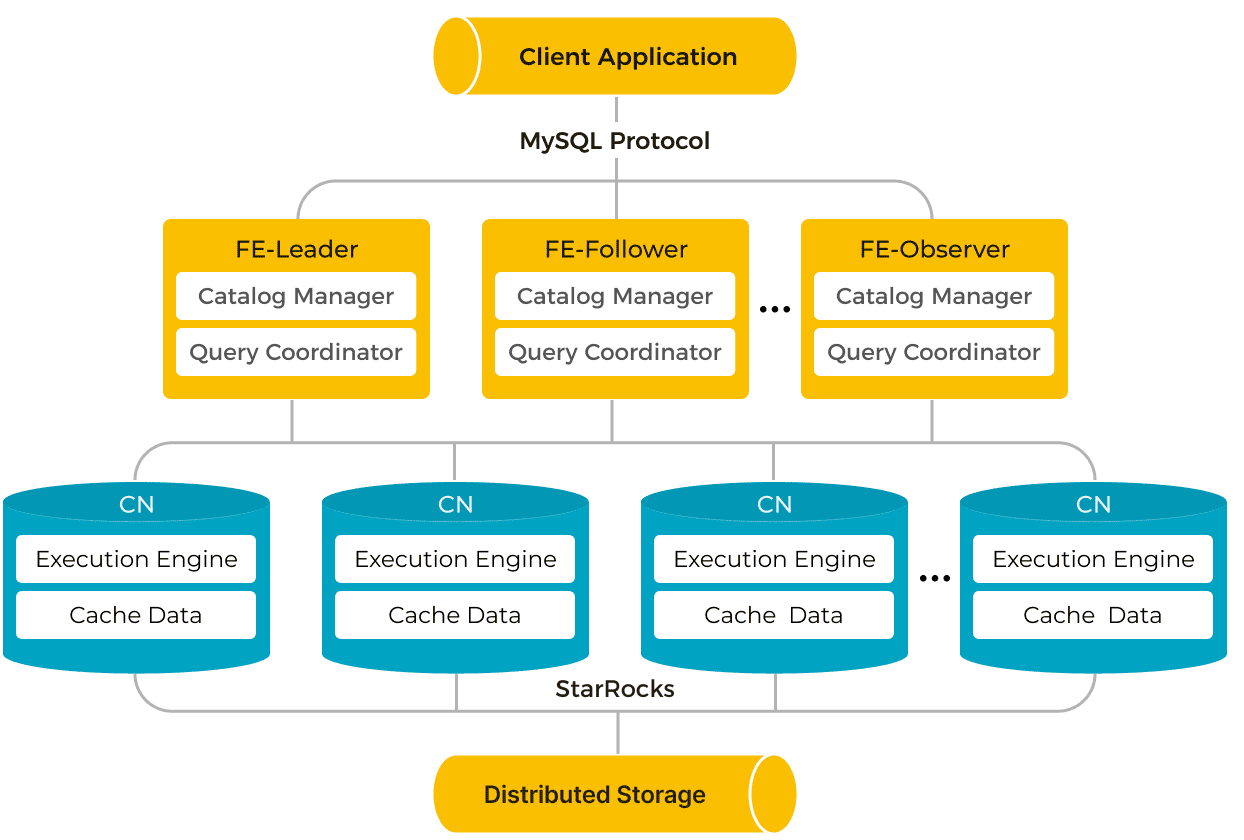
- без разделения ресурсов (shared-nothing), когда каждый BE имеет часть данных в своем локальном хранилище. FE отвечают за управление метаданными, управление клиентскими соединениями, планирование запросов и диспетчеризацию запросов. Каждый FE использует BDB JE (Berkeley DB Java Edition) для хранения и поддержки полной копии метаданных в своей памяти, обеспечивая согласованные услуги во всех FE. Если лидер FE выходит из строя, подписчики выбирают нового на основе протокола Raft. BE выполняют планы запросов и хранят данные, используя локальное хранилище для ускорения запросов и механизм множественных реплик для обеспечения высокой доступности. Прямой доступ к локальным данным BE позволяет быстро выполнять локальные вычисления, избегая передачи и копирования данных. Этот режим хорошо подходит для сценариев, где нужна оптимальная производительность запросов.
- общие данные (shared-data), когда все данные хранятся в объектном хранилище или HDFS, а каждый CN имеет только кэш в локальном хранилище. Удаленные объектные хранилища (AWS S3, Google GCS, Azure Blob Storage или MinIO) и HDFS обеспечивают низкую стоимость, надежность и масштабируемость. Благодаря разделению вычислений и хранения, stateless-узлы CN можно добавлять и удалять без повторной балансировки данных.
Таким образом, кластеры shared-data разделяют хранение данных и вычисления, позволяя масштабировать их независимо, что сокращает затраты и повышает эластичность. Однако, такая архитектура эта архитектура может снизить производительность запросов. Чтобы смягчить эти последствия, StarRocks предлагает многоуровневую систему доступа к данным, охватывающую память, локальный диск и удаленное хранилище. Запросы к горячим данным сканируют кэш напрямую, а затем локальный диск. Холодные данные необходимо загружать из объектного хранилища в локальный кэш для ускорения последующих запросов. Сохраняя горячие данные близко к вычислительным блокам, StarRocks достигает высокой скорости вычислений и экономически эффективного хранения. Доступ к холодным данным оптимизирован с помощью стратегий предварительной выборки данных.
Включить кэширование можно при создании таблиц, тогда данные будут записываться на локальный диск и в хранилище объектов бэкенда. Во время запросов узлы CN сначала считывают данные с локального диска. Если данные не найдены, они будут извлечены из хранилища объектов бэкенда и одновременно кэшированы на локальном диске.
Как уже было отмечено ранее, StarRocks использует подход MPP, когда один запрос разделяется на несколько физических вычислительных блоков, которые могут выполняться параллельно на нескольких машинах. Каждая машина имеет выделенные ресурсы ЦП и памяти. При этом используются ресурсы всех ядер ЦП на всех машинах. Таким образом, производительность одного запроса может непрерывно увеличиваться по мере масштабирования кластера. Общий объем хранилища, необходимый кластеру StarRocks, зависит от размера необработанных данных и степени их сжатия, а также количества реплик.
Тонкости выполнения SQL-запросов
При выполнении SQL-запроса StarRocks разбирает оператор на несколько фрагментов – логических единиц выполнения в соответствии с его семантикой. Затем, в зависимости от сложности вычислений, каждый фрагмент реализуется одним или несколькими экземплярами фрагмента – физическими единицами выполнения. Физическая единица выполнения — это наименьшая единица планирования в StarRocks, которая планируется на BE-узлы для выполнения. Одна логическая единица выполнения может содержать один или несколько операторов, таких как операторы Scan, Project и Agg. Каждая физическая единица выполнения обрабатывает только часть данных, которые потом объединяются. Параллельное выполнение логических единиц выполнения полностью использует ресурсы всех ядер ЦП и физических машин, обеспечивая высокую скорость работы системы. Например, бенчмаркинговые тесты, проведенные разработчиками этой БД, показали успешную обработку более 10 000 запросов в секунду на 16-ядерный экземпляр за счет оптимизированных точечных запросов и ускорения с индексацией по первичному ключу в гибридном строково-столбцовом хранилище.
Такая высокая скорость обеспечивается не только MPP-архитектурой StarRocks, но и его каскадным CBO-планировщиком выполнения запросов, оптимизированным для векторизованного движка. Эти оптимизации включают повторное использование общих табличных выражений (CTE), переписывание подзапросов и разные стратегии выполнения соединений. Это позволяет обеспечивать высокую производительность многотабличных запросов.
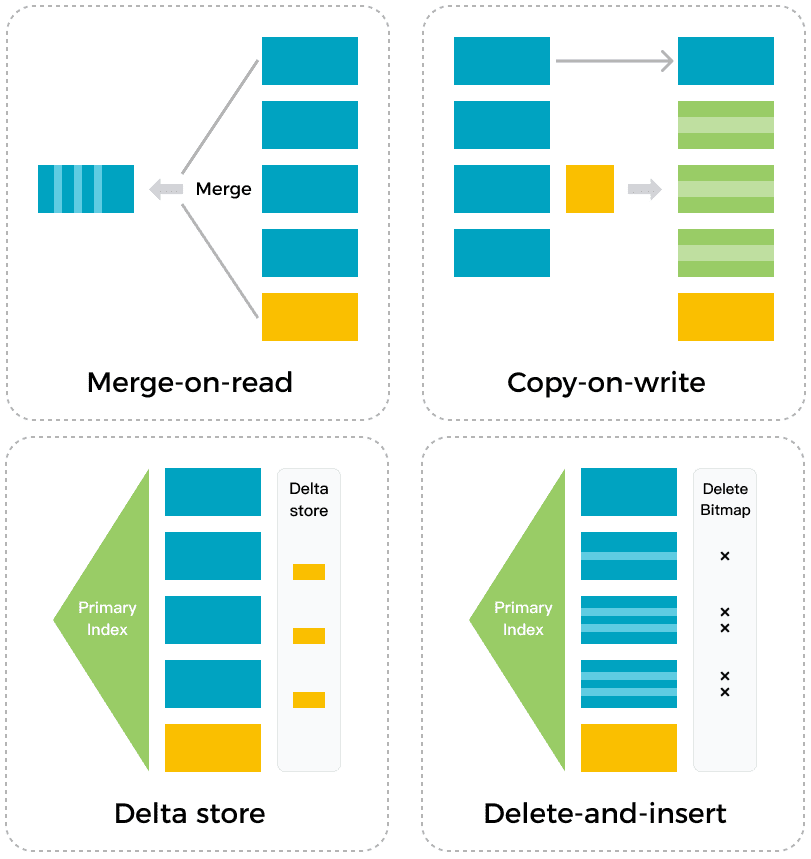
Благодаря колоночному механизму хранения, данные одного типа хранятся непрерывно и могут быть сжаты и закодированы более эффективно. Это снижает стоимость хранения и сокращает общее количество операций ввода-вывода для чтения данных. Помимо таких оптимизаций для OLAP-сценариев, StarRocks может принимать данные за считанные секунды в режимах массовой вставки или точечных обновлений, в отличие от ClickHouse, гарантируя соблюдение ACID-требований к транзакциям. Шаблон Delete-and-insert в механизме хранения позволяет эффективно выполнять операции частичного обновления и Upsert. Быстрая фильтрация данных обеспечивается благодаря индексам первичного ключа, устраняя необходимость в операциях Sort и Merge при чтении данных. Движок хранения также поддерживает вторичную индексацию, обеспечивая быструю и предсказуемую производительность запросов даже при большом объеме обновлений.
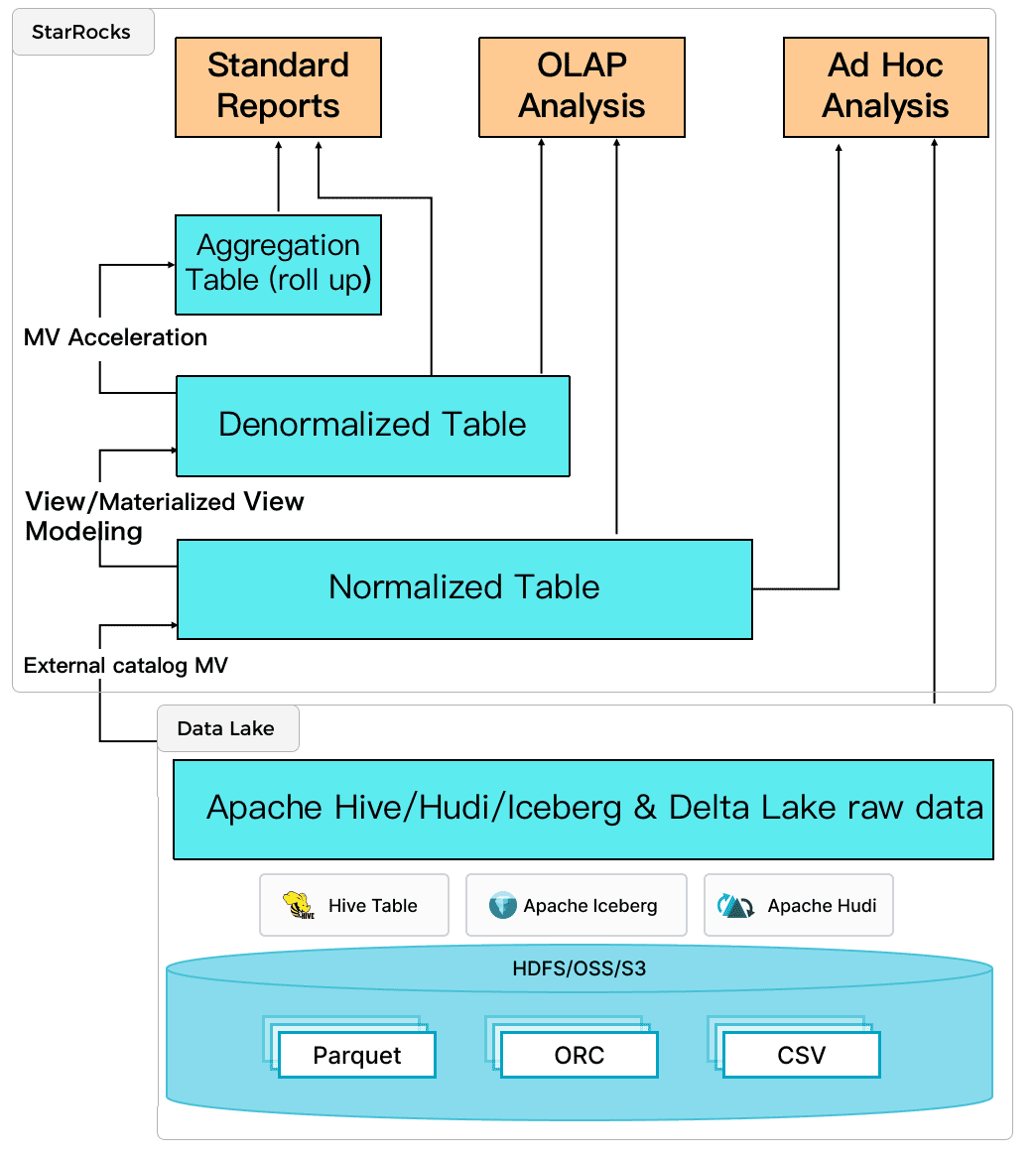
Для ускорения запросов StarRocks использует интеллектуальные синхронные и асинхронные материализованные представления. Они автоматически обновляют данные в соответствии с изменениями данных в базовой таблице без дополнительных операций. Выбор материализованных представлений происходит автоматически: если его использование повысит скорость выполнения запроса, запрос будет переписан автоматически. Это упрощает конвейер обработки данных, позволяя выполнять нормализацию и денормализацию таблиц для поддержки высококонкурентных запросов и повышения производительности их выполнения.
Благодаря этому StarRocks можно использовать не только как мощное аналитическое хранилище данных, но и как вычислительный механизм движок для анализа данных, хранящихся в озерах данных, включая Apache Hive, Iceberg, Hudi и Delta Lake. Это похоже на сценарии применения Trino, о сравнении с которым мы рассказываем в новой статье. Связь с внешним хранилищем метаданных реализуется с помощью внешнего каталога, позволяя пользователям напрямую запрашивать внешние источники данных: HDFS и облачные объектные хранилища. При этом поддерживаются различные форматы файлов: Parquet, ORC, CSV и пр. Таким образом, StarRocks может использоваться в разных сценариях современной архитектуры данных, выполняя роли механизма хранения и инструмента аналитики.
Узнайте, как построить эффективную архитектуру данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

