Продолжая разговор про межрегиональную репликацию Apache Kafka, сегодня рассмотрим 4 способа ее реализации: мультирегиональный кластер, MirrorMaker 2, Cluster Linking в Confluent Server и Confluent Replicator. Чем георепликация Kafka с MirrorMaker 2 отличается от решений Confluent и что выбирать для различных сценариев. Мультирегиональный кластер Confluent Геораспределенная репликация реплицирует данные по кластерам...
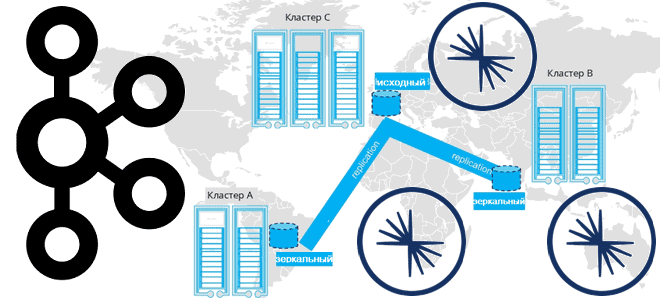
Недавно мы писали про мультирегиональную репликацию Apache Kafka. Сегодня рассмотрим, как выполнить геораспределенную репликацию с помощью Cluster Linking в Confluent Server и Kafka Connect с Confluent Replicator. Cluster Linking для Apache Kafka Связанные кластеры представляют собой 2 или более кластера в разных географических регионах. В отличие от топологии растянутого кластера,...
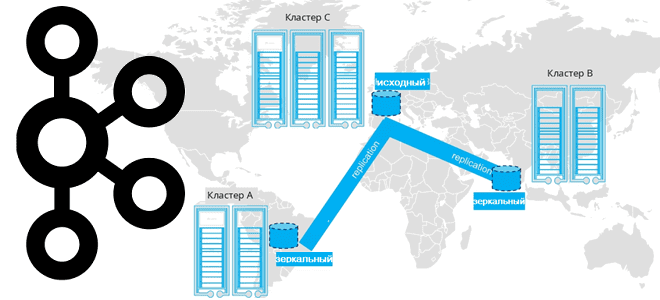
Какую топологию может иметь кластер Apache Kafka при межрегиональной репликации по нескольким ЦОД и как это реализовать. Чем брокеры-наблюдатели отличаются от подписчиков в Confluent Server и при чем здесь конфигурация подтверждений acks в приложении-продюсере. Принципы репликации данных в Apache Kafka Будучи средством интеграции информационных систем в режиме реального времени, Apache...

Какие инфраструктурные компоненты самые дорогие в эксплуатации популярной платформы потоковой передачи сообщений и как снизить затраты на сетевые ресурсы и хранилища данных при использовании Apache Kafka. TCO для Apache Kafka: что учитывать в расчете затрат Поскольку Apache Kafka используется для интеграции информационных систем в режиме реального времени, она становится критически...

Что лучше: один или несколько кластеров Apache Kafka, когда и зачем разворачивать новый кластер вместо масштабирования существующего, какие задачи администрирования поручить локальным DevOps-инженерам, а что решать централизовано. Один или несколько кластеров Apache Kafka? Продолжая разговор про эффективное управление корпоративным кластером Apache Kafka, сегодня рассмотрим, когда и зачем нужно разворачивать новый...

Зачем размещать задания Apache Spark на узлах HDFS, какую пропускную способность сети передачи данных выбрать, почему не рекомендуется использовать RAID для жестких дисков, сколько выделить памяти и ядер ЦП. Рекомендации по настройке оборудования для Spark-приложений На практике большинство заданий Spark считывает входные данные из внешней системы хранения, например, файловой системы...
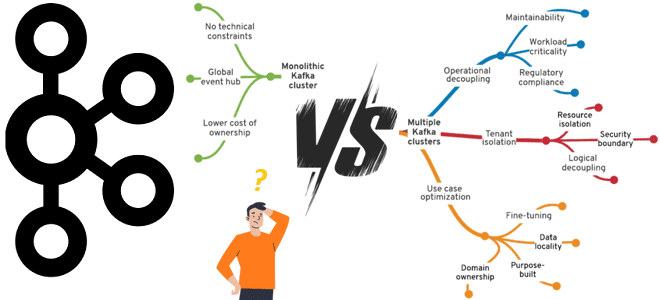
Что выбрать для эффективного управления корпоративным кластером Apache Kafka, от чего зависит уровень централизации и какие факторы влияют на принятие решений. Стратегии управления корпоративным кластером Apache Kafka Типовой вариант использования Apache Kafka – это потоковая интеграция корпоративных приложений. Чтобы эффективно использовать эту платформу потоковой передачи событий в масштабах предприятия, необходимо...
Как выполнить миграцию данных: лучшие практики и рекомендации на примере Greenplum. Особенности и принципы работы утилит gpbackup, gprestore и gpcopy. Миграция данных из Greenplum на 7 с утилитами gpbackup и gprestore Независимо от причины миграции данных из прикладной системы или корпоративного хранилища данных на новую технологию, эта процедура всегда остается...
Какие меры принять администратору кластера Apache Kafka, чтобы повысить надежность потоковой экосистемы, использующей эту распределенную платформу как средство интеграции различных приложений. Сбои в потоковой экосистеме и способы их устранения Хотя Apache Kafka считается высоконадежной системой благодаря множеству встроенных механизмов отказоустойчивости, таким как репликация и перевыборы лидера. Впрочем, это не исключает...
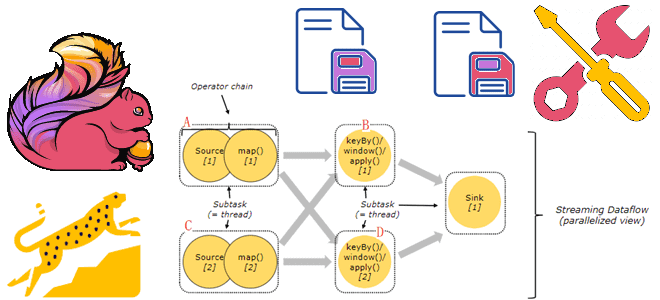
Почему хранить состояния Flink-приложений лучше на локальных SSD-диски, а не на твердотельных накопителях с удаленной файловой системой NFS или HDFS, зачем отключать блочный кэш RocksDB и как настроить параллелизм заданий. Проблемы сохранения состояния в RocksDB и способы их решения Как мы уже упоминали здесь, key-value хранилище RocksDB является самым популярным...