 1028
1028 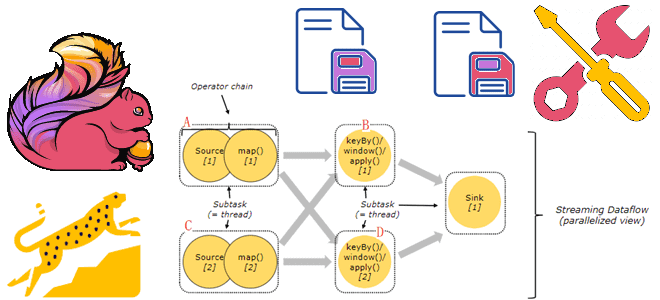
Содержание
Почему хранить состояния Flink-приложений лучше на локальных SSD-диски, а не на твердотельных накопителях с удаленной файловой системой NFS или HDFS, зачем отключать блочный кэш RocksDB и как настроить параллелизм заданий.
Проблемы сохранения состояния в RocksDB и способы их решения
Как мы уже упоминали здесь, key-value хранилище RocksDB является самым популярным бекэндом состояний для stateful-приложений Flink. Это встраиваемое постоянное хранилище взаимодействует с Flink через собственный Java-интерфейс (JNI) и размещается на узле кластера Flink. RocksDB полностью встроен в процесс диспетчера задач (TaskManager) и полностью управляется им. RocksDBStateBackend можно настроить на уровне кластера по умолчанию для всего кластера или на уровне задания для отдельных заданий. Конфигурация уровня задания имеет приоритет над конфигурацией уровня кластера.
Хотя эта СУБД хранит некоторые данные в памяти, большая часть состояния сохраняется на диске. Поэтому при работе с большими stateful-приложениями требуются очень производительные диски. Однако, это становится очевидно не сразу. Например, для приложений с небольшим состоянием, такими как смещения потребителя Kafka, вполне подойдут тома сетевой файловой системы (NFS), которая обеспечивает повышенную отказоустойчивость.
Однако, для приложений с большими состояниями (несколько терабайт) это решение не подойдет, т.к. рабочее состояние Flink-приложения в RocksDBStateBackend передается в файлы на диске, которые расположены в каталоге, указанном в конфигурации state.backend.rocksdb.localdir. Поскольку производительность диска напрямую влияет на производительность RocksDB, рекомендуется располагать этот каталог на локальном диске, а не на удаленном, таком как NFS или HDFS, поскольку запись на удаленные диски обычно происходит медленнее.
Поэтому лучше использовать локальные твердотельные накопители (SSD), в которых используется технология энергонезависимой памяти (флеш-память NAND), и для хранения данных на них не требуется питание. В отличие от классических жестких дисков на основе магнитных вращающихся пластин (HDD), твердотельные накопители не имеют ограничений по размеру и форме. А из-за отсутствия вращающейся магнитной головки, скорость доступа к данным не зависит от их физического расположения и держится на высоком уровне.
Локальные SSD-диски предпочтительнее, если требуется высокая пропускная способность диска: снимки состояния сохраняются в удаленном долговременном хранилище. Во время создания снимков состояния диспетчеры задач делают снимок текущего состояния и сохраняют его удаленно. Передача снимка состояния в удаленное хранилище выполняется исключительно самим диспетчером заданий без участия серверной части состояния. Таким образом, параметр state.checkpoints.dir, установленный в коде приложения для конкретного задания, может находиться в разных местах, например, в локальном кластере HDFS или в облачном объектном хранилище (Amazon S3 , Azure Blob Storage, Google Cloud Storage, Alibaba OSS и пр.). При этом стоит помнить, что при использовании локального SSD для RocksDB, развернутой в облачной платформе, например, в Google Cloud Platform, надежность снижается из-за возможного выхода инстанса из строя. Но благодаря механизмам обеспечения отказоустойчивость Flink, таким как контрольные точки и точки сохранения, состояние приложения можно восстановить.
Иногда долго работающее Flink-приложение с большим количеством состояний может выдать OOM-ошибку, т.е. столкнуться с нехваткой памяти (Out Of Memory) и перезапускается. При этом причиной OOM-ошибки может быть совершенно не JVM, а то бэкенд состояния состояния RocksDB, который использует много собственной памяти за пределами виртуальной машины Java. Такое происходит, когда RocksDB пытается выделить больше памяти, чем было настроено на использование. Устранить эту проблему можно, отключив блочный кеш RocksDB с помощью публичного интерфейса RocksDBOptionsFactory, реализовав его в следующем коде:
import org.apache.flink.contrib.streaming.state.{ConfigurableRocksDBOptionsFactory, RocksDBOptionsFactory}
import org.rocksdb.DBOptions
import org.rocksdb.ColumnFamilyOptions
import org.rocksdb.BlockBasedTableConfig
import org.apache.flink.configuration.ReadableConfig
import java.util
class NoBlockCacheRocksDbOptionsFactory extends ConfigurableRocksDBOptionsFactory {
override def createDBOptions(currentOptions: DBOptions, handlesToClose: util.Collection[AutoCloseable]): DBOptions = {
currentOptions
}
override def createColumnOptions(
currentOptions: ColumnFamilyOptions,
handlesToClose: util.Collection[AutoCloseable]
): ColumnFamilyOptions = {
val blockBasedTableConfig = new BlockBasedTableConfig()
blockBasedTableConfig.setNoBlockCache(true)
// Needed in order to disable block cache
blockBasedTableConfig.setCacheIndexAndFilterBlocks(false)
blockBasedTableConfig.setCacheIndexAndFilterBlocksWithHighPriority(false)
blockBasedTableConfig.setPinL0FilterAndIndexBlocksInCache(false)
currentOptions.setTableFormatConfig(blockBasedTableConfig)
currentOptions
}
override def configure(configuration: ReadableConfig): RocksDBOptionsFactory = {
this
}
}
Отключение блочного кэша RocksDB не влияет на производительность, а затрагивает только на время заполнения кэша.
Пока данные записываются или перезаписываются в RocksDB, сброс из памяти на локальные диски и сжатие данных управляются в фоновом режиме потоками этой NoSQL-СУБД. Поэтому на машине с большим количеством ядер ЦП следует увеличить параллелизм фоновой очистки и сжатия, установив во Flink конфигурацию state.backend.rocksdb.thread.num, соответствующую max_background_jobs в RocksDB. Конфигурация по умолчанию обычно слишком мала для производственной установки. Если задание Flink часто считывает данные из RocksDB, можно включить фильтры Блума – компактную вероятностную структуру для проверки принадлежности элемента к множеству. Фильтры Блума активно используются для быстрого поиска данных, например, в Google BigTable они позволяют снизить количество обращений к жесткому диску при проверке на существование заданной строки или столбца в таблице базы данных. Bloom-фильтр отлично позволяет сократить число запросов к несуществующим элементам в структуре данных с дорогими read-операциями, например, доступ к данным на жестком диске или к сетевому хранилищу. Подробнее об этом мы писали здесь.
Как настроить параллелизм заданий Apache Flink
Приложение Flink состоит из нескольких задач, включая преобразования (операторы), источники данных и приемники. Эти задачи разбиваются на несколько параллельных экземпляров для выполнения и обработки данных. Параллелизм относится к параллельным экземплярам задачи и представляет собой механизм, позволяющий увеличивать или уменьшать масштаб вычислений. Это один из основных факторов, влияющих на производительность приложения. Увеличение параллелизма позволяет приложению использовать больше слотов задач, что повышает общую пропускную способность и производительность. Параллелизм приложений можно настроить на разных уровнях: уровень оператора, уровень среды выполнении, уровень клиента и системный уровень.
Выбор конфигурации действительно зависит от особенностей Flink-приложения. Например, если известно, что некоторые операторы в приложении являются узким местом, следует увеличить параллелизм только для этого узкого места. Рекомендуется начинать с одного значения параллелизма на уровне среды выполнения и при необходимости увеличивать его, поскольку совместное использование слотов задач позволяет лучше использовать ресурсы.
Когда подзадачи с интенсивным вводом-выводом блокируются, подзадачи, не связанные с вводом-выводом, могут использовать ресурсы диспетчера задач. Поэтому наибольшее значение параллелизма должно быть равно количество диспетчеров задач, умноженное на количество слотов задач в каждом диспетчере задач. Например, при использовании параллелизма 100 (определяемого либо как уровень среды выполнения по умолчанию, либо на уровне определенного оператора) потребуется запустить 25 диспетчеров задач, если каждый диспетчер задач имеет четыре слота: 25 x 4 = 100.
Читайте в нашей новой статье, как коммерческое облачное решение Ververica оптимизирует классические механизмы Flink, позволяя избежать повышения параллелизма благодаря замене традиционного бэкенда состояний для stateful-приложений RocksDB на GeminiStateBackend.
Узнайте больше про использование Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

