Что выбрать для эффективного управления корпоративным кластером Apache Kafka, от чего зависит уровень централизации и какие факторы влияют на принятие решений.
Стратегии управления корпоративным кластером Apache Kafka
Типовой вариант использования Apache Kafka – это потоковая интеграция корпоративных приложений. Чтобы эффективно использовать эту платформу потоковой передачи событий в масштабах предприятия, необходимо внедрить внутренние стандарты ее эксплуатации и правила для команд разработки. При отсутствии общей стратегии потоковой передачи данных возможны проблемы с выполнением критически важных рабочих нагрузок на кластерах Kafka. Эффективная стратегия управления корпоративным кластером предполагает централизованный мониторинг системных показателей, а также анализ инцидентов с выявлением причин сбоев, чтобы все пользователи Kafka могли принять меры по устранению проблем.
Хорошим организационным решением будет выделение команды администраторов и DevOps-инженеров по сопровождению корпоративного кластера Kafka в команду, предоставляющую эту платформу потоковой передачи событий как услугу (KaaS, Kafka as a Service). Это позволит сосредоточить опыт и знания специалистов по Kafka в одном месте, а также избавит разработчиков приложений от непрофильных работ.
В любом случае стратегия управления корпоративным кластером Kafka должна согласовываться со стратегией данных и иметь оптимальный баланс между централизацией и децентрализацией.
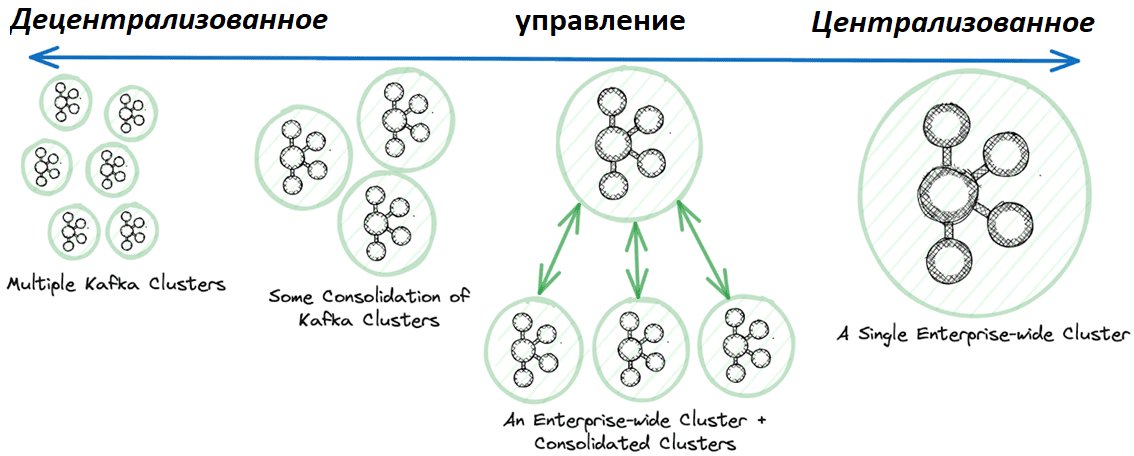
При абсолютно децентрализованной стратегии в компании есть несколько кластеров Kafka, каждый из которых обслуживает определенное решение, проект, географический регион или бизнес-подразделение. Эти разрозненные кластеры существуют независимо друг от друга и управляются локальными командами автономно.
При консолидации нескольких кластеров они остаются по большей части независимыми, но объединение позволяет сократить затраты на DevOps и инфраструктуру. Большая степень централизации наблюдается при выделении общего кластера для совместных и/или часто используемых данных. Наконец, полная централизация предполагает единый кластер Kafka на все предприятие, где обслуживаются все рабочие нагрузки потоковой передачи данных для эффективной утилизации человеческих и инфраструктурных ресурсов в масштабах всей компании.
Такая стандартизация снижает затраты и операционную нагрузку, связанную с разработкой и эксплуатацией нескольких кластеров Kafka. Консолидация инфраструктуры сокращает затраты на оборудование и операции обновления, мониторинга и масштабирования. При этом консолидированная платформа потоковой передачи данных обычно обеспечивает более высокое качество данных и равномерную загрузку узлов, повышая производительность и снижения риски управления данными. Поскольку каждый кластер Kafka имеет довольно большую площадь уязвимостей, сопровождение конфигураций, обновлений, мониторинга, контроля доступа и ведения журналов аудита легче делать централизовано.
Обратной стороной преимуществ централизованной стратегии управления корпоративными кластерами Apache Kafka есть следующие недостатки:
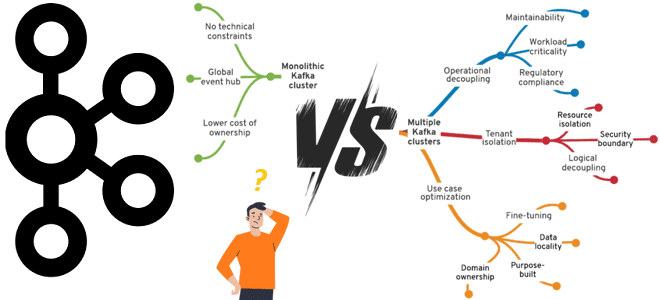
- централизованная служба должна отвечать расширенному набору требований всех ее составляющих, даже тех, выполнение которых сложно и дорого. Например, некоторым пользователям требуются очень низкие задержки обработки данных, тогда как у других в приоритете большие объемы сообщений. В таком случае лучше подойдет децентрализованная стратегия.
- Создание KaaS-решения потребует значительных организационных и процессных преобразований, включая достижение консенсуса со всеми стейкхолдерами. Помимо выявления и реализации технических требований, придется организовать выставление счетов за пользование платформой на основе использования, определить приоритеты запросов на новые возможности и предоставление поддержки в соответствии с SLA.
Таким образом, выбор стратегии управления корпоративным кластером Kafka зависит от затрат, вариативности сценариев использования и доступности ресурсов (человеческих и инфраструктурных). Далее рассмотрим, какие факторы надо при этом учитывать.
Стоимость, ценность и закон Конвея
Стоимость является одним из главных вопросов при инвестировании в любую технологию. Оценить затраты при использовании однотенантного кластера довольно легко: они складываются из стоимости потребляемых ресурсов. В случае мультиарендного кластера, при совместном использовании ресурсов Kafka на несколько команд придется обеспечить справедливое распределение затрат между всеми пользователями, учитывать окупаемость и период возврата инвестиций. Также масштабирование кластера будет зависит от совокупного роста количества пользователей и вариативности их сценариев.
Помимо прямых затрат следует учитывать ценность, которую централизованное или децентрализованное управление кластерами Kafka приносит компании. Для этого важно учитывать общую стоимость владения (TCO, Total Cost Ownership), которая включает материальные затраты на инфраструктуру и оборудование, лицензии, подписки, плату за обслуживание, а также затраты на разработку и эксплуатацию. Кроме прямых затрат есть еще скрытые, которые часто составляют значительную часть TCO, но просчитать их сложнее. Например, работы по устранению сбоев, управление клиентами во время ухудшения качества обслуживания, выделение ресурсов при простоях и реагирование на инциденты безопасности.
Чтобы осознанно управлять всеми затратами, следует определить корпоративный бюджет на KaaS. Мультитенантные услуги требуют четко определенного плана финансирования из одного или нескольких источников. В случае децентрализованного обеспечения следует установить четкие документированные правила учета и возмещения затрат пользователям. К примеру, определить механизмы возврата платежей и выставления счетов отдельным бизнес-подразделениям на основе значений показатели использования Kafka-кластера, включая его пропускную способность, задержку, сетевой трафик, использование диска и коэффициенты репликации.
Степень консолидации кластеров Kafka зависит от характера обмена данными между корпоративными приложениями. Зачастую проще использовать совместно расположенные данные в одном кластере, чем объединять данные из нескольких кластеров. Единый кластер снижает затраты, сложность, а также технические проблемы доступа к данным и их использования.
Однако, полнофункциональная платформа потоковой передачи данных может абстрагировать кластерную архитектуру от совместного использования и доступа к данным. Логично размещать данные, используемые совместно, в пределах одного кластера, отделяя их от тех, которые предполагают другие требования к задержке и изоляции.
Размер и сложность бизнеса также влияют на стратегию управления корпоративными кластерами Apache Kafka. Согласно закону Конвея, компании-разработчики систем обычно воспроизводят свою организационную структуру в создаваемых программных решениях. Поэтому для корпораций с четко определенными оргструктурами проще внедрить централизованное управление кластерами Kafka, чем распределенной проектной организации из множества фрилансеров.
Географическое распределение тоже играет роль в выборе стратегии управления кластерами Kafka. Например, 152-ФЗ требует, чтобы персональные данные граждан РФ хранились на серверах, расположенных в России, аналогично тому, как европейский регламент GDPR требует хранения аналогичной информации о гражданах ЕС в странах Евросоюза в соответствии с его законами о конфиденциальности, либо в юрисдикции с аналогичными уровнями защиты. Важно убедиться, что процессы управления KaaS-платформой исключают случайное нарушение этих требований, например, копирование или перемещение незащищенной личной информации за пределы региона.
С технической точки зрения на выбор степени централизации Kafka-кластеров влияет вариативность сценариев использования, в т.ч. диапазоны допустимых значений по задержке, пропускной способности, периодичности обновлений и авторизациям клиентов. Как правило, один кластер Kafka намного проще настроить и управлять им, чем поддерживать множество отдельных кластеров. Большим преимуществом централизации является объединение ресурсов. Вместо резервирования накладных расходов в каждом кластере, можно объединить их, снизив совокупную стоимость потребляемых ресурсов для всех пользователей и приложений.
Впрочем, из-за разных требований к задержке обработки данных и времени их хранения в Kafka-кластере (retention.size и retention.time), а также различные коэффициенты репликации проще соблюсти, распределив разные рабочие нагрузки по разным кластерам. Помимо сценариев использования и географического разделения, можно группировать кластеры Kafka по критичности рабочих нагрузок, учитывая последствия отказа. В случае централизованной стратегии управления отказ единого кластера, который поддерживает все бизнес-процессы, окажет огромное влияние на бизнес, тогда как выделенный кластер для каждой рабочей нагрузки имеет небольшое влияние. Также важна продолжительность простоя из-за отказа.
Наконец, стратегия управления корпоративными кластерами Kafka должна обеспечивать безопасность данных, гарантируя их конфиденциальность за счет предоставления доступов только аутентифицированным пользователям. Для этого можно внедрить политику авторизации на основе ролей (RBAC). При наличии нескольких кластеров каждая команда имеет права администрирования только своего экземпляра Kafka. А криптографические механизмы защиты данных могут быть включены централизовано для всех, например, SSL/TLS-шифрование трафика, использование защищенных протоколов и другие средства обеспечения безопасности Apache Kafka, о которых мы писали здесь.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники

