
Как расширить возможности Apache Flink с помощью дополнительных плагинов: подключение внешних ресурсов и обогащение отказов пользовательскими метками. Разбираемся с продвинутыми настройками для эффективной эксплуатации фреймворка. Внешние ресурсы Apache Flink Помимо процессора и памяти, многим рабочим нагрузкам также требуются другие ресурсы, например, графические процессоры для глубокого обучения. Для поддержки внешних ресурсов...
Управление ресурсами и планирование рабочей нагрузки в ClickHouse
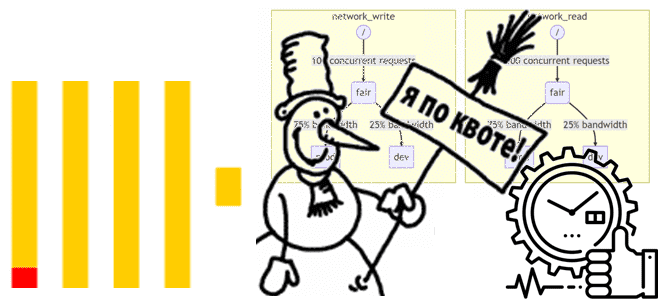
Как эффективно распределять и использовать ресурсы ClickHouse, зачем ограничивать возможности пользователей с помощью квот и классифицировать рабочие нагрузки. Управление ресурсами в ClickHouse Благодаря своей децентрализованной архитектуре ClickHouse, когда один экземпляр включает несколько серверов, к которым напрямую приходят запросы пользователей, эта колоночная СУБД работает очень быстро. Для репликации данных и выполнения...
Интеграция ClickHouse с Apache AirFlow

Чем полезна интеграция ClickHouse с Apache Airflow и как ее реализовать: операторы в пакете провайдера и плагине на основе Python-драйвера. Принципы работы и примеры использования. 2 способа интеграции ClickHouse с AirFlow Продолжая разговор про интеграцию ClickHouse с другими системами, сегодня рассмотрим, как связать эту колоночную СУБД с мощным ETL-движком Apache...
Новинки Apache Kafka 3.7: обзор свежего релиза

В конце февраля вышел очередной релиз Apache Kafka за номером 3.7. Поддержка JBOD в KRaft-кластерах, новый протокол перебалансировки потребителей, мониторинг метрик клиента на брокере, новинки Streams и Connect, и другие изменения самой популярной платформы потоковой передачи событий для дата-инженера и администратора. Изменения в брокерах, продюсера, контроллерах и Admin Client 27...
Разделять ли топик Apache Kafka: 5 главных соображений
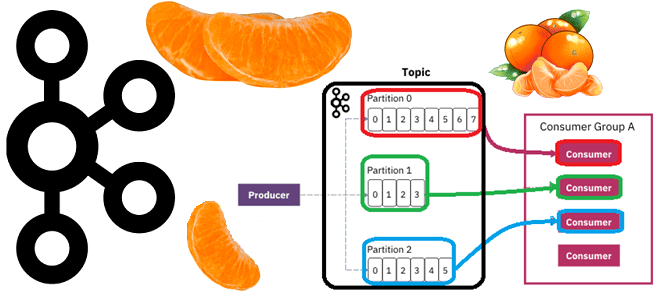
Почему раздел называется единицей параллелизма и как определить оптимальное число разделов в топике Apache Kafka в зависимости от количества потребителей и вариативности их поведения, разницы пропускной способности публикации и потребления сообщений, семантики партиционирования, толерантности к упорядоченности событий и ресурсных возможностей узла кластера. Что учитывать при разделении топика Apache Kafka Хотя...
Плавное завершение работы брокера Apache Kafka и перевыборы лидера

Что такое graceful shutdown в Apache Kafka, когда используется такое плавное завершение работы, при чем здесь синхронизация реплик и как это влияет на плановые операции обслуживания кластера. Как работает механизм Graceful shutdown в Apache Kafka Благодаря множеству внутренних механизмов обеспечения отказоустойчивости, Apache Kafka имеет высокую надежность и позволяет строить нагруженные...
Администрирование Greenplum с помощью утилиты gpsupport

Как найти зависший процесс в базе данных Greenplum, создать резервную копию каталога, разделить лог-файл по тестам и проверить его на наличие повреждений. Знакомимся с набором утилит gpsupport. 6 инструментов утилиты gpsupport для техподдержки Greenplum Как и любая крупная система Greenplum, помимо компонентов, обеспечивающих ее ключевые функции, также включает дополнительные инструменты,...
Как создать и запустить docker-контейнер Apache AirFlow на Windows

Что такое WSL, Docker и как запустить веб-сервер Apache AirFlow в контейнере на локальной машине в Ubuntu поверх Windows вместо любимого Google Colab. Пошаговое руководство для начинающих дата-инженеров. Краткий ликбез по WSL и Docker для любителей Windows Обычно я всегда запускала веб-сервер Apache AirFlow в интерактивной среде Google Colab, которая...
Как сменить SQLLite на PostgreSQL для бэкенда Apache AirFlow
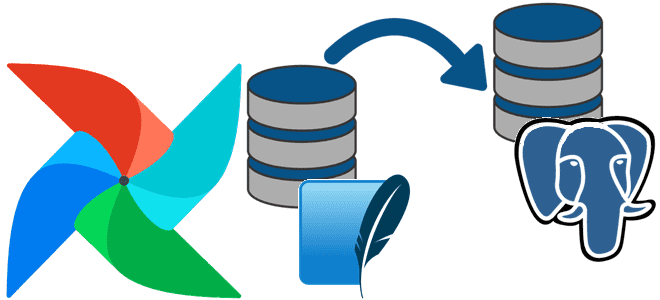
Зачем менять базу данных метаданных в производственном развертывании Apache AirFlow и как это сделать: пошаговое руководство для дата-инженера с примерами и рекомендациями. 5 шагов перехода от SQLLite к PostgreSQL: миграция базы данных метаданных Apache AirFlow Чтобы планировать и запускать конвейеры обработки данных, Apache AirFlow хранит сведения о задачах, DAG, исполнителях,...
Журналирование событий в Apache Spark и сжатие лог-файлов

Когда журналирование событий может привести к OOM-ошибке, где отслеживать системные метрики приложения Apache Spark, зачем сжимать лог-файлы и как это сделать. Логирование системных метрик в приложении Apache Spark Поскольку фреймворк Apache Spark изначально предназначен для создания высоконагруженных распределенных приложений пакетной и потоковой обработки больших объемов данных, он позволяет отслеживать системные...