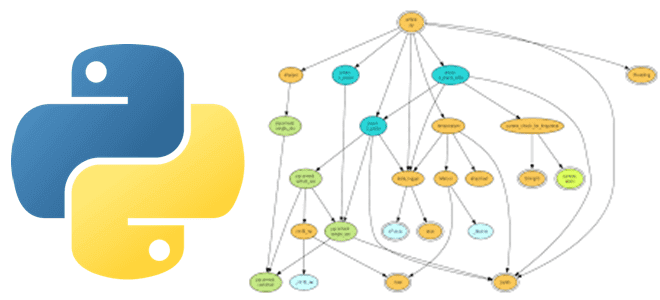
Практически каждый Python-разработчик и Data Scientist использует в своем коде сторонние библиотеки и внешние решения, которые хранятся в разных репозиториях и связаны со множеством других файлов. Этот открытый код настолько распределен, что возникает «ад зависимостей», что сильно осложняет разработку. Читайте, как справиться с этой проблемой, используя методы анализа графов. Проблема...

Как повысить качество данных и пакетных конвейеров с их обработки в Apache AirFlow с Python-библиотекой Whylogs. Что это за средство регистрации и профилирования, как оно работает, каким образом совместимо с DAG-графом задач Apache AirFlow и чем полезно дата-инженеру. Что такое Whylogs и зачем это Apache AirFlow Apache AirFlow активно используется...
Рассмотрим, как дата-инженеры Airbnb делятся своим опытом перевода корпоративного Data Lake на Apache HDFS в облачное объектное хранилище AWS S3. Почему пришлось переводить аналитические нагрузки с Apache Hive на Iceberg и Spark, и какие результаты это принесло. Предыстория: Data Lake на HDFS и Apache Hive Будучи крупнейшей онлайн-площадкой для размещения...
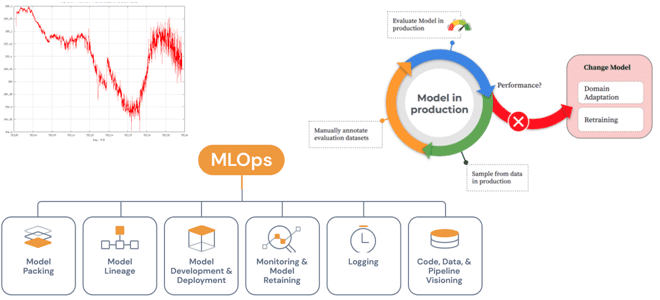
Специально для обучения ML-разработчиков сегодня разберем проблемы развертывания моделей Machine Learning в производстве и способы их решения с помощью MLOps-инструментов. А также поговорим про дрейф данных и его обнаружение методами математической статистики. Жизненный цикл ML-моделей и MLOps Каждый проект машинного обучения начинается с данных, подготовка которых занимает большую часть жизненного...

Чтобы добавить в наши курсы для ИТ-архитекторов и дата-инженеров еще больше полезных материалов, сегодня рассмотрим, как модернизировать аналитические рабочие нагрузки в транзакционных системах с помощью гибридной архитектуры Data Mesh. А также поговорим о том, как реализовать этот подход с организационной и технической точек зрения. Аналитика и транзакции: versus или вместе?...
Сегодня разберем тему, важную для обучения дата-инженеров и разработчиков распределенных Spark-приложений. Почему чтение данных из реляционных баз в Apache Spark может быть медленным и как его ускорить, изменив SQL-запрос или структуру таблицы. JDBC-источники данных для Apache Spark Apache Spark является средством обработки, а не хранения больших данных. Поэтому, чтобы использовать...
Мы уже писали про поиск сложных событий при их потоковой обработке средствами Apache Flink. Продолжая эту важную для обучения дата-инженеров тему, сегодня рассмотрим, как CDC-коннектор от GetIndata упрощает запуск распознавание шаблонов на потоках данных из многих источников. Проблемы захвата измененных данных из реляционной базы с помощью JDBC-драйвера и способы их...
В этой статье для обучения дата-инженеров рассмотрим, как крупнейший медиа-банк Storyblocks добился обновления данных в корпоративном хранилище без простоев с помощью DevOps-идеи сине-зеленого развертывания и механизма TaskGroup в Apache Airflow. Проблемы ETL при массовой загрузке данных в Data Lake и DWH Storyblocks – это крупнейший в мире банк данных, включающий...
Мы уже писали о Python-клиентах Apache Kafka, которые позволяют разрабатывать приложения потоковой передачи события, используя популярный Python вместо сложных языков Java и Scala. Сегодня познакомимся с еще одной Python-библиотекой, которая представляет асинхронный клиент для Kafka. Что такое aiokafka и чем это отличается от kafka-python: краткий обзор для обучения инженеров данных...

Сегодня рассмотрим важную тему для обучения дата-инженеров и разработчиков распределенных Spark-приложений. Как устроена потоковая обработка данных в Apache Spark Structured Streaming, зачем нужны водяные знаки и с какими сложностями при этом можно столкнуться. Как работают водяные знаки в потоковой передача событий Apache Spark Библиотека потоковой обработки событий Structured Streaming основана...