 708
708 
Практически каждый Python-разработчик и Data Scientist использует в своем коде сторонние библиотеки и внешние решения, которые хранятся в разных репозиториях и связаны со множеством других файлов. Этот открытый код настолько распределен, что возникает «ад зависимостей», что сильно осложняет разработку. Читайте, как справиться с этой проблемой, используя методы анализа графов.
Проблема зависимостей в Python-разработке
Основное препятствие, с которым сталкиваются инженеры данных, Python-разработчики и Data Scientist’ы при обращении к репозиториям открытого кода — это проблема зависимостей или связей между его модульными единицами. Каждый файл в этих репозиториях связан со множеством других посредством импорта. В итоге открытый код становится настолько распределенный и много модульный, что бывает сложно перейти к фактическому определению нужной функции. Это явление получило название «ад зависимостей» (dependency hell), став антипаттерном управления программной конфигурацией. Такое разрастание взаимозависимостей программных библиотек, возникшее из-за благих намерений реализации принципа DRY (Don’t Repeat Yourself) приводит к сложности установки новых и удаления старых продуктов.
В частности, иногда программные продукты требуют наличия разных версий одной и той же библиотеки или несовместимых друг с другом пакетов. Это очень осложняет процессы разработки и тестирования, поскольку одна библиотека может нарушить работу других зависимых пакетов. В Python-разработке ад зависимостей часто возникает из-за того, что популярный менеджер пакетов pip не имеет распознавателя зависимостей и все зависимости являются общими для всего проекта. Подробнее про управление зависимостями Python в распределенном PySpark-приложении читайте в нашей новой статье.
Некоторые системы управления зависимостями, такие как npm, избегают этой проблемы, делая все зависимости локальными зависимостями, а не локальными проектами. Другие создают переименованные версии зависимостей (например, «затенение» в Maven). В любом случае, упростить понимание таких зависимостей поможет их наглядная визуализация в виде направленного графа. Для этого существует целый ряд инструментов:
- Pydeps;
- Modulegraph;
- Pipdeptree;
- Snakefood.
Что представляет собой каждый из этих модулей, мы рассмотрим далее.
4 библиотеки для построения графа зависимостей
Начнем с Pydeps – библиотеки визуализации зависимостей модулей Python, которая строит графы с использованием пакета Graphviz. Установив обе эти библиотеки через менеджер пакетов pip, можно с их помощью отобразить зависимости в Python-файле.
pip install pydeps pip install graphviz
Pydeps находит импорт по кодам операций импорта в байт-кодах Python (.pyc-файлах). Будут найдены только импортированные файлы, pydeps не просматривает неимпортированные файлы в пользовательском каталоге. Кроме того, будут учитываться только файлы, которые можно найти с помощью механизма импорта Python, т. е. если модуль отсутствует или не установлен, он не будет включен независимо от фактического импорта. Это можно изменить, используя флаг —include-missing.
Введя в командной строке команду
pydeps pydeps --rankdir TB
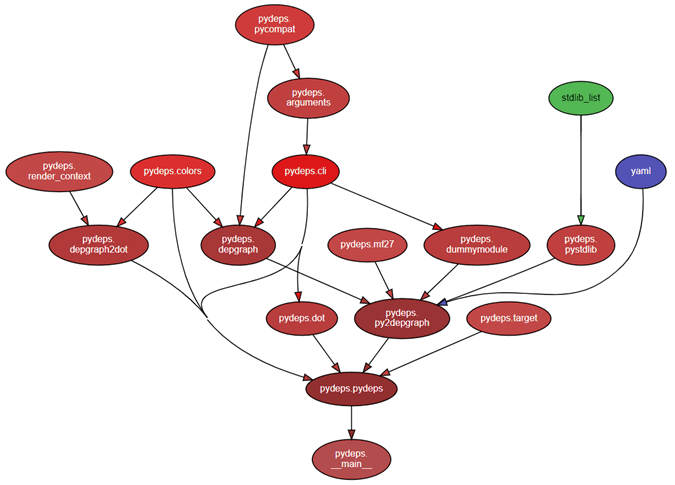
получим граф зависимостей, которые есть в самой библиотеке Pydeps:
Библиотека snakefood тоже позволяет создавать графы зависимостей из кода Python. Этот пакет использует AST-дерево для анализа файлов Python, что очень надежно и всегда работает. В отличие от аналогов, snakefood не имеет проблемы с загрузкой модулей для определения зависимостей, что требует дополнительной настройки, поскольку многие кодовые базы запускают код инициализации в глобальном пространстве имен. Snakefood работает с набором файлов, т.е. не нужно указывать один скрипт, можно выбрать каталог или пакет: все файлы Python найдутся рекурсивно и автоматически.
Путь к Python-файлам (PYTHONPATH) автоматически настраивается, чтобы включить необходимые корни пакетов, определяя пути, которые требуются от файлов/каталогов, указанных в качестве входных данных. Не нужно ничего настраивать и следить за зависимостями между модулями – snakefood по умолчанию он рассматривает только те файлы и каталоги, которые указаны в командной строке, и их непосредственные зависимости. Пакет состоит из нескольких простых программ, выходные данные которых объединяются с помощью конвейеров. snakefood можно комбинировать с grep, sed и прочими подобными инструментами.
Еще одной полезной библиотекой для решения проблемы с зависимостями является pipdeptree — утилита командной строки для отображения установленных пакетов Python в виде дерева. Он работает для пакетов, установленных глобально на компьютере, а также в виртуальной среде. Поскольку команда pip freeze показывает все зависимости в виде плоского списка, определение того, какие пакеты являются пакетами верхнего уровня и от каких пакетов они зависят, требует много усилий. Также утомительно разрешать конфликтующие зависимости, которые могли быть установлены, потому что в более старой версии менеджера пакетов pip не было настоящего разрешения зависимостей. Утилита pipdeptree поможет справиться с этой проблемой, выявив конфликтующие зависимости, установленные в среде. Однако, pipdeptree просто просматривает установленные пакеты в текущей среде с помощью pip, строит дерево, а затем выводит его в указанном формате. Если вы хотите сгенерировать дерево зависимостей без установки пакетов, понадобится преобразователь зависимостей, например, pipgrip или poetry.
В заключение рассмотрим пакет modulegraph, который определяет граф зависимостей между модулями Python в первую очередь путем анализа байт-кода для операторов импорта. Он использует аналогичные методы для поиска модулей из стандартной библиотеки, но использует более гибкое внутреннее представление и является расширяемым.
Как использовать методы и средства анализа графов для аналитики больших данных и разработки ПО в реальных проектах, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

