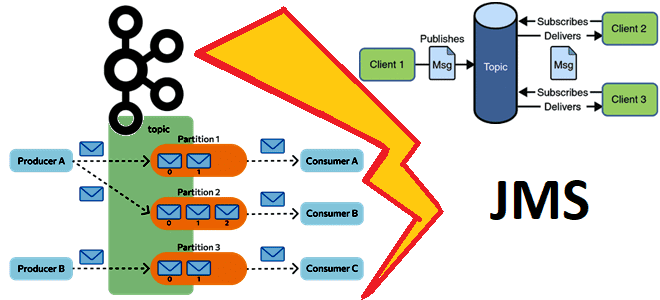
В этой статье для обучения дата-инженеров и разработчиков распределенных систем сравним Apache Kafka с популярными реализациями Java-стандартов обмена сообщениями, к которым относится Apache ActiveMQ, IBM MQ, Rabbit MQ и другие JMS-брокеры. Чем распределенная платформа потоковой передачи событий отличается от JMS-брокеров и что между ними общего. Что такое JMS-брокер Прежде чем...

Сегодня разберем тему, особенно полезную для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink: обнаружение сложных цепочек связанных событий в потоковой обработке. Как создать свой шаблон поиска сложных событий с библиотекой FlinkCEP. Комплексная обработка событий или зачем вам CEP Современный data-driven бизнес хочет принимать...

В этой статье для обучения дата-инженеров и аналитиков данных заглянем под капот Apache Hive, чтобы разобраться с механизмов LLAP. Как этот движок повышает производительность популярного SQL-on-Hadoop инструмента, поддерживая длительные процессы на одних и тех же ресурсах для кэширования и аналитической обработки больших данных. Что такое LLAP в Apache Hive и...
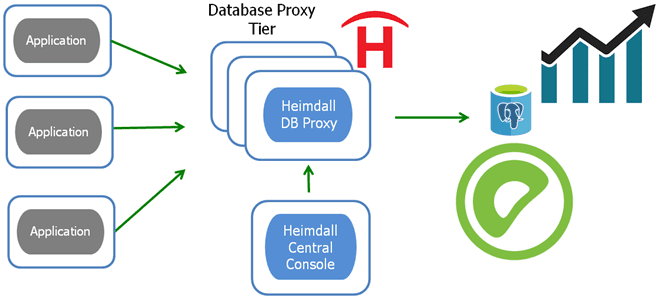
Сегодня рассмотрим, что такое Heimdall Database Proxy и как это пригодится администратору кластера Greenplum и разработчику распределенных приложений, взаимодействующих с этой MPP-СУБД. А также разберем, с какими проблемами администратор кластера может столкнуться при настройке совместного использования этих систем, и как их решить. Что такое Heimdall Database Proxy Хотя Greenplum работает...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем, как Airbnb использует графовые нейросети для улучшения машинного обучения. А также рассмотрим, как устроены GCN-нейросети и что определяет выбор между потоковым и пакетным ML-конвейером. Анализ графов для обогащения ML-моделей Многие проблемы машинного обучения могут быть...

Сегодня рассмотрим серьезную уязвимость CVE-2022-33140, связанную с авторизациями и обнаруженную в последнем выпуска Apache NiFi 1.16.3, о котором мы писали здесь. Почему проблема с ShellUserGroupProvider оказалась так значительна и что сделано для ее устранения. Уязвимость CVE-2022-33140 в Apache NiFi 1.16.3 В свежем релизе Apache NiFi 1.16.3, который вышел 15 июня...
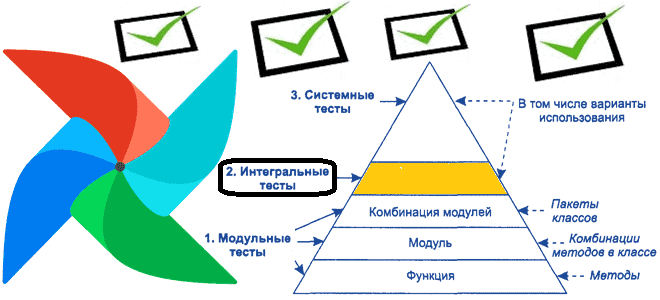
Продолжая тему тестирования DAG в Apache Airflow, сегодня рассмотрим следующий этап проверки качества ПО – разработку интеграционных тестов. Разберемся, как при этом дата-инженер может использовать Docker Compose и Pytest, а также познакомимся с возможностями REST API самого популярного в Big Data batch-оркестратора. Идеи и инструменты интеграционного тестирования DAG в Apache...

Недавно мы сравнивали разные форматы сериализации данных, поддерживаемые Apache Kafka. Однако, AVRO и JSON не могут похвастаться таким высоким коэффициентом сжатия, как колоночный бинарный формат Parquet. Читайте далее, как хранить больше потоковых данных на тех же ресурсах с помощью движка Deephaven и других open-source решений. Apache Kafka и Parquet Apache...

Постоянно добавляя в наши курсы по Apache Spark полезные материалы, сегодня мы рассмотрим, что происходит под капотом этого вычислительного движка, чтобы помочь разработчикам распределенных приложений и дата-инженерам повысить его эффективность. Тонкости сериализации данных, компиляции SQL-запросов в JavaBytecode и сборка мусора. 2 библиотеки сериализации данных в Apache Spark В распределенных системах...
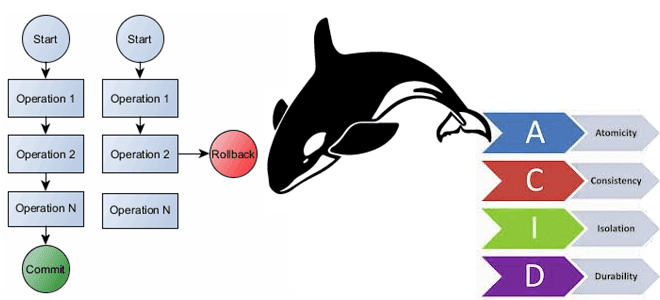
В этой статье для обучения архитекторов, дата-инженеров и аналитиков данных рассмотрим, как поддерживаются транзакции в Apache HBase и почему к ACID-свойствам также добавляется характеристика видимости обновлений. Насколько атомарны и консистентны мутации данных внутри строки HBase, почему сканирование не полностью согласовано и как разрешить устаревшие чтения или путешествия во времени в...