Чтобы добавить в наши курсы для ИТ-архитекторов и дата-инженеров еще больше полезных материалов, сегодня рассмотрим, как модернизировать аналитические рабочие нагрузки в транзакционных системах с помощью гибридной архитектуры Data Mesh. А также поговорим о том, как реализовать этот подход с организационной и технической точек зрения.
Аналитика и транзакции: versus или вместе?
Довольно часто у пользователей транзакционного приложения возникает запрос на панель мониторинга, которая позволит понимать, что именно происходит в системе, чтобы принимать решения, основанные на данных. Если такой запрос реализован после нескольких лет работы приложения, оно содержит несколько представлений, в т.ч. материализованных, реплик чтения и сложных двунаправленных взаимодействий между репликой чтения и рабочей базой данных. Когда данных становится много, могут возникнуть проблемы совместимости аналитических и транзакционных нагрузок.
Транзакционные приложения обычно ориентированы на транзакционные рабочие нагрузки, что реализуется с помощью реляционных баз данных. Аналитические рабочие нагрузки могут влиять на транзакционные, поскольку часто решаются путем направления их на реплику чтения рабочей базы данных. При этом для повышения производительности используются следующие методы оптимизации:
- денормализация, чтобы избежать множества SQL-запросов на соединения различных таблиц через JOIN;
- индексирование для ускорения поиска и улучшения фильтрации;
- собственные подсказки запросов (хинты, hint) для принудительного выполнения определенных планов запросов;
- сплит-разделение таблиц по горизонтали (по столбцам) или по вертикали (партиционирование) для уменьшения объема обрабатываемых данных;
- сжатие строк для компромисса между операциями записи и чтения.
Суть этих методов в том, чтобы преобразовать транзакционную нагрузку с высокой степенью параллелизма, предназначенную для эффективной обработки большого количества мелких транзакций, в аналитическую систему с низкой степенью параллелизма, которая считывает все данные. Хотя в целом это довольно дорого и требует много времени, команда разработки транзакционного приложения может удовлетворить все требования своих клиентов с помощью используемого технологического стека. Однако, даже при больших усилиях, это не позволяет гарантировать максимальную производительность транзакционных систем. Чтобы обойти это ограничение, разработчикам придется менять стек технологий, выбирая наиболее подходящие решения для аналитических нагрузок.
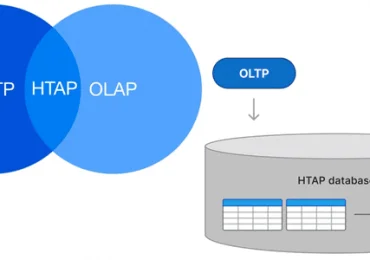
В частности, аналитические рабочие нагрузки выигрывают от использования хранилища, ориентированного на столбцы, поскольку пользователям отчетов необходимо видеть все данные, в отличии от выборки строк в транзакционных системах. Для этого оперативные данные часто выгружают в корпоративное хранилище или озеро, направляя туда также и все аналитические рабочие нагрузки. Затем дата-инженеры выполняют соответствующие преобразования, чтобы предоставить пользователям необходимые данные. Но, т.к. эти конвейеры обработки данных обычно строятся на необработанных таблицах, каждый небольшой рефакторинг в рабочей базе данных будет влиять на них. Если при этом задействовано несколько инженерных команд, сложно избежать простоев и несогласованности в работе. Справиться с этим помогут контракты, в которых обмен структурами данных обеспечивается и гарантируется транзакционным приложением. При этом необходимо обеспечить команде разработки транзакционных приложений возможность управления, сохраняя разделение операционных и аналитических данных.
Вместо разделения аналитических и операционных функций в отдельных командах более эффективным является кросс-функциональный подход. Это обеспечивает целостность данных, а также согласованность конвейеров их обработки. Аналитика данных должна без проблем поддерживаться в транзакционных приложениях без необходимости привлекать дополнительную команду разработчиков. Вместо переноса каждой таблицы или представления в рабочей базе данных в центральное хранилище или озеро, лучше сосредоточиться на точных вариантах использования, ограничив копирование. Следует также отказаться от попытки универсализации подхода для всех сценариев: каждый случай оптимально реализуется с использованием подходящей технологии. В частности, колоночное хранилище данных отлично подойдет для огромных табличных отчетов вместе с системой обмена сообщениями в режиме реального времени.
Таким образом, наилучшим вариантом организации такой доменно-ориентированной архитектуры данных является Data Mesh – сетка данных. Это децентрализованная по разным доменам архитектура данных 4-го поколения, которая имеет централизованное управление и единые стандарты, обеспечивающие интегрируемость данных, а также централизованную инфраструктуру, с возможностью использования в режиме самообслуживания. Data Mesh активно использует потоковую и пакетную парадигмы обработки данных вместе с децентрализованным подходом, когда различные наборы данных должны полностью управляться отдельными командами в разных бизнес-областях. При этом продукты данных каждой доменной команды должны быть обнаруживаемыми, совместимыми, безопасными, надежными и обладать самоописываемой семантикой и синтаксисом. Впрочем, Data Mesh — это не только технологии и инструменты, а также люди и организационная культура. Каковы роли специалистов в этой архитектуре данных, мы рассмотрим далее.
Роли специалистов в архитектуре Data Mesh
Помимо традиционных ролей в конвейерах обработки данных, таких как дата-аналитики и инженеры, Data Mesh вводит несколько новых и перепрофилирует некоторые из существующих. В частности, появляется владелец продукта данных (DPO, Data Product Owner). Поскольку Data Mesh рассматривает данные как продукт, DPO нужен, чтобы обеспечить строгое управление продуктом и удобство работы пользователей с их данными. Владелец продукта данных понимает сценарии использования, которые может обслуживать конкретный домен, превращает их в требования и применяет их к наборам данных домена. DPO осознает неограниченный характер вариантов использования данных, включая различные комбинации наборов множеством способов.
Владелец продукта данных несет ответственность за предоставление измеримых характеристик, демонстрирующих ценность и влияние наборов данных. Эти характеристики говорят о том, насколько данные доступны для обнаружения, понятны, адресуемы, безопасны, интероперабельны, надежны, доступны и ценны для предметной области.
Платформа, на которой размещаются данные и базовая инфраструктура, называется платформой данных, которую проектируют и реализуют инженеры платформы. Поскольку сетка данных одной направлена на предоставление доменам возможности автономно создавать и обмениваться данными, платформа должна позволять доменам управлять своими данными от начала до конца. Обычно для этого используются API платформы самообслуживания. В отличие от децентрализованных аспектов Data Mesh, таких как доменно-ориентированное владение данными, платформа управляется централизованно. Она не зависит от домена, абстрагируясь от предоставления и управления базовой инфраструктурой. Платформа также автоматизирует рутинные задачи, например, проверка целостности данных.
Дизайн и реализация этой платформы находятся на стыке разработки ПО и обработки данных, поэтому за нее отвечают дата-инженеры. А разработчики продуктов данных создают, поставляют, поддерживают и развивают данные, относящиеся к предметной области, которые моделируются как продукт. Разработчик продукта данных тесно сотрудничает с DPO, чтобы понять ожидания пользователей и обеспечить совместимость с другими продуктами данных в сетке. Аналогичным образом разработчик продуктов данных тесно сотрудничает с разработчиками ПО и дата-инженерами, владея кодом, логикой и схемой данных своего домена и предоставляя эти ресурсы через API платформы. На практике эту роль может выполнять разработчик Big Data приложений со знанием систем данных и событий.
Кроме инфраструктуры, управление данными является другой централизованной функцией в архитектуре Data Mesh. Хотя группа управления данными централизована, она представляет собой кросс-функциональную команду из разработчиков платформы, владельцев продуктов, а также экспертов по безопасности, правовым вопросам и соблюдению нормативных требований. Группа управления данными создает политики и стандарты того, как следует управлять данными и обслуживать их, чтобы гарантировать, что продукты данных безопасны и заслуживают доверия. В рамках этого комитета владельцы продуктов данных определяют политику, которая будет регулировать продукты данных из разных доменов. Инженеры платформы автоматизируют реализацию политик, например контроль доступа к конфиденциальным данным, шифрование или абстрагирование персональной идентифицируемой информации. Эксперты по безопасности следят за соблюдением правил конфиденциальности и соответствия данных требованиям регулятора.
Как организовать работу всех этих специалистов на практике, а также какие технологии использовать для реализации архитектурного подхода Data Mesh, мы рассмотрим далее.
Стратегии и технологии реализации
В организациях с низкой степенью зрелости данных ранние настройки комплексной архитектуры имеют явное преимущество почти нулевого технического долга. Такие компании могут извлечь огромную выгоду из платформы данных, разработанной в соответствии с долгосрочным видением. На этом этапе первым звеном являются инженеры платформы данных, которые вместе с командами доменов, могут приступить к созданию различных блоков платформы. Далее следует выделить владельца продукта данных для нескольких доменов, чтобы установить общие методы управления продуктами в разных предметных областях. В то время как модель сетки данных рекомендует выделить DPO для каждого домена, на начальном этапе один DPO может играть роль архитектора управления продуктом и работать в разных доменах.
В компаниях с более высоким уровнем зрелости данных обычно уже бывает внедрена какая-то модель их структуры. Здесь часто наблюдается разграничение команд по разным доменам, выделены менеджеры продуктов, которые работают с кросс-функциональными командами, и дата-инженеры, создающие инфраструктуру данных. В таких организациях настроить модель Data Mesh довольно просто технически и организационно: роль DPO можно создать, перепрофилировав роль менеджера продукта. Инженер платформы данных также может быть ролью дата-инженера, которая была переопределена в соответствии с контекстом Data Mesh.
В зрелых data-driven компаниях данные являются неотъемлемой частью продукта и бизнес-стратегии. Такие организации уже давно прошли исследовательскую фазу экспериментов с инструментами и процессами, выяснив, что работает для них лучше всего. Компания находится на этапе внесения постепенных улучшений с помощью данных. Однако, внедрение архитектурного подхода Data Mesh в этих организациях может быть сложной задачей, а иногда и вовсе ненужной. Тем не менее, роль владелец продукта данных, все же может принести пользу. DPO может помочь с постепенными улучшениями полезности данных для конечных пользователей, унифицируя методы и процессы в разных предметных областях. Команда управления данными может быть диверсифицирована за счет включения представления предметной области и продукта.
Таким образом, когда речь идет о Data Mesh, не существует универсальной стратегии ее внедрения, подходящей для всех компаний. Роли, дизайн и реализация должны быть адаптированы к индивидуальным сценариям с учетом принципов Data Mesh. При этом следует создавать кросс-функциональные команды, обладающие всеми необходимыми навыками для создания комплексных решений, связанных с предметной областью, чтобы люди продолжали расширять свои знания и повышали эффективность для достижения бизнес-целей. Также рекомендуется снизить порог входа для работы с платформой данных, определив базовые знания каждого специалиста и обеспечивая периодическое профессиональное обучение для всех членов команды.
С технической точки следует настроить контракты для обмена структурами данных между разными дата-продуктами. Поставщик данных должен обеспечить стабильность и надежность этих структур с помощью автоматизированного тестирования. Поддержка и проверка кода для обучения разработчиков продуктов данных позволит им успешно предоставлять продукты данных для их совместного использования с платформой. А цикл обратной связи обеспечит постоянное улучшение качества предоставляемых услуг.
Чтобы загружать данные быстро, следует использовать типовые инструменты пакетной и потоковой интеграции данных, например, Trino + dbt, Debezium, Kafka, Snowflake, Airbyte, Meltano. Для преобразования данных подойдут dbt, Apache Spark, Flink, Dask. Автоматический захват метаданных, включая происхождение данных, документацию и показатели качества, обеспечат Apache Atlas, Amundsen, Dagster. Федеративные глобальные политики безопасности нужны, чтобы предоставить владельцам данных возможность управлять политиками безопасности своих собственных данных. Это можно сделать с Apache Ranger.
Возможность публиковать продукты данных, включая документацию, информацию о происхождении и показатели качества, реализуют Amundsen и DataHub. А для управления конвейерами обработки данных, включая их публикацию, планирование и мониторинг, подойдут Dagster и Apache Airflow.
Узнайте больше про современные дата-архитектуры для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Аналитика больших данных для руководителей
- Data Pipeline на Apache Airflow
- Data Pipeline на Apache AirFlow и Arenadata Hadoop
Источники