 642
642 
Содержание
В этой статье для обучения дата-инженеров рассмотрим, как крупнейший медиа-банк Storyblocks добился обновления данных в корпоративном хранилище без простоев с помощью DevOps-идеи сине-зеленого развертывания и механизма TaskGroup в Apache Airflow.
Проблемы ETL при массовой загрузке данных в Data Lake и DWH
Storyblocks – это крупнейший в мире банк данных, включающий лицензионное видео, изображения и аудио. Учитывая огромный объем данных, не удивительно, что у компании есть базы данных, множество приложений и ETL-конвейеры, которые импортируют их в корпоративное DWH. Например, массовое копирование баз данных MySQL, размещенных на Amazon RDS, в хранилище данных в Amazon Redshift можно выполнить даже за одну ночь, но при таком наивном подходе возникают три проблемы: задержка, снижение надежности данных и прерывание рабочих нагрузок. Все это может случиться из-за операций массовой загрузки, которые загружают целевые данные в корпоративное озеро или хранилище данных. Некоторые ETL-инструменты, такие как Amazon Database Migration Service (AWS DMS), упрощают настройку обычной миграции данных, но при этом по умолчанию удаляют или очищают целевые таблицы.
Облачный сервис AWS DMS помогает выполнить миграцию баз данных на платформу AWS, поддерживая источник в полностью рабочем состоянии во время миграции, что сводит к минимуму время простоя использующих ее приложений. Сервис поддерживает как однородные миграции, например из Oracle в Oracle, так и разнородные между различными платформами баз данных, например из Oracle или Microsoft SQL Server в Amazon Aurora, а также консолидацию разных баз данных в хранилище объемом несколько петабайт путем потоковой передачи данных в Amazon Redshift.
Тем не менее, даже с таким мощным инструментом дата-инженерии надежность данных может пострадать, если ETL-процесс сбрасывает целевые таблицы перед массовой загрузкой новых данных. Любая необработанная ошибка в процессе загрузки может оставить озеро/хранилище данных в незавершенном состоянии. Когда в ETL добавляется все больше и больше процессов обработки данных, а в озеро или хранилище данных добавляются различные рабочие нагрузки, некоторые операции массовой загрузки могут привести к прерыванию рабочих нагрузок. Например, ETL может стереть длительную операцию SELECT для производной таблицы аналитика или задание механизма рекомендаций, которое запустил Data Scientist. В результате этих ограничений ETL часто назначается только один раз в день на ночь, а задержка данных может всегда отставать на день.
Избежать вышеописанных проблем поможет поддержка двух наборов целевых данных для каждого источника. Это соответствует идее «сине-зеленого» развертывания, которое считается одной из лучших DevOps-практик и сокращает время простоя за счет запуска двух идентичных производственных сред: синей и зеленой. В любой момент активна только одна из этих сред: она обслуживает весь трафик, а старое задание заменяется новым, когда оба запущены и только одно из них обрабатывает данные. При этом немного снижается скорость отправки новых заданий, которая зависит в основном от количества доступных ресурсов. Сине-зеленое развертывание может занять несколько минут.
Также сине-зеленое развертывание дает быстрый способ отката: если что-то пошло не так, можно переключить маршрутизатор обратно в синюю среду. При этом по-прежнему остается проблема обработки пропущенных транзакций, когда зеленая среда была активной. Но в зависимости от дизайна можно передавать транзакции в обе среды так, чтобы синяя среда оставалась резервной, когда зеленая среда активна. Также можно перевести приложение в режим только для чтения перед переключением, запустить его на некоторое время в режиме только для чтения, а затем переключить его в режим чтения-записи. Две среды должны быть разными, но максимально идентичными, хотя могут быть представлены разными аппаратными средствами или виртуальными машинами. Они также могут представлять собой единую операционную среду, разделенную на отдельные зоны с отдельными IP-адресами для двух частей. Эту же стратегию можно использовать для обновления Apache AirFlow, о чем мы рассказываем в новой статье. А как Storyblocks применили эту идею к загрузке данных в целевые таблицы корпоративного озера и хранилища, рассмотрим далее.
Сине-зеленое развертывание с группами задач в Apache AirFlow
Название «сине-зеленый» происходит от концепции разработки ПО и непрерывной интеграции/непрерывной доставки, предполагая развертывание нового кода на наборе серверов и постепенному сокращению трафика на новые серверы. Применяя идею сине-зеленого развертывания к ETL-процессам, можно сделать выводы о необходимости поддерживать 2 набора данных: «синий» и «зеленый», а также простой слой представления поверх них, который фактически используют все потребители. Например, есть рабочая база данных учетных записей, будут базы данных account_blue и account_green в хранилище данных с заполненными таблицами. Также будет база данных учетных записей, которая просто содержит представления каждой таблицы, указывающие на активную БД.
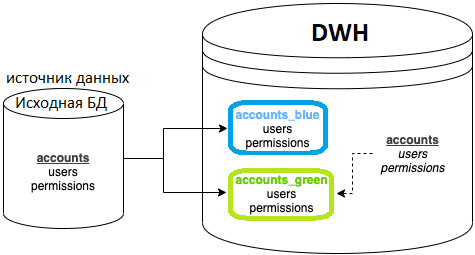
Многие ETL-инструменты загружают данные во временную таблицу, а затем меняют имя таблицы в конце процесса. Это вполне разумное решение, но в некоторых системах оно может привести к прерыванию рабочих процессов. А где-то такой вариант вообще невозможен, например, для Amazon DMS это невозможно сделать без дополнительных усилий.
Изначально в Storyblocks задания AWS DMS удаляли и загружали целевые таблицы, что приводило к проблемам. В частности, команда специалистов по машинному обучению пыталась считывать данные в своих собственных ночных заданиях и часто получала неполные результаты от еще не завершенных заданий DMS, или ETL прерывал их процесс, задерживая работу на целый день. Поэтому дата-инженеры компании решили применить Apache Airflow для этой задачи. Этот мощный ETL-инструмент активно используется в Storyblocks для планирования большинства процессов обработки данных.
Реализовать идею сине-зеленого развертывания с заданиями AirFlow можно, используя группы задач (TaskGroups) – механизм, появившийся во 2-ой версии фреймворка, о чем мы рассказывали здесь. Это более простая в использовании функция по сравнению с SubDag для многократного использования групп задач. Возможность представлять DAG-графы в виде отдельных задач реализуется с помощью механизма TaskGroup, который используется в качестве контекстного менеджера. Это позволяет соблюсти принцип модульности и визуально объединить задачи. Также это соответствует любимому разработчиками DRY-принципу (Don’t Repeat Yourself), помогая избежать повторения кода, если подграф используется несколько раз или экспортирован в другой DAG. По сути, группы задач – это конструкция пользовательского веб-интерфейса Apache AirFlow, которая не влияет на поведение задач при их выполнении, но упрощает создание, управление и просмотр больших вложенных файлов DAG.
До версии 2.0 в AirFlow не было возможности переключать задачи, которые создают DAG. С 2021 года TaskGroup позволяют инкапсулировать вложенные задачи в графическом представлении, визуально организовав их в иерархические группы. Это упрощает работу дата-инженера с объемными цепочками задач. В отличие от SubDagOperator, TaskGroup — это концепция группировки пользовательского интерфейса: задачи находятся в исходном DAG и соответствуют заранее заданным конфигурациям. По умолчанию дочерние задачи и группы задач имеют свои идентификаторы task_id и group_id с префиксом group_id их родительской группы TaskGroup. Это гарантирует уникальность их идентификаторов (group_id и task_id) во всей группе DAG.
Можно отключить префикс, установив параметр prefix_group_id в значение False при создании TaskGroup. Это дает пользователю полный контроль над фактическими идентификаторами group_id и task_id, которые должны быть уникальными во всей группе DAG. Такое отключение параметра prefix_group_id пригодится для помещения задач из существующих DAG в группу без изменения их task_id. Отношения зависимости могут применяться ко всем задачам в группе.
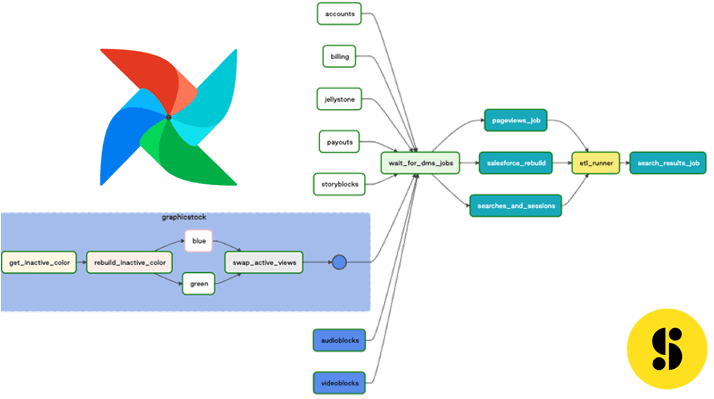
Возвращаясь к кейсу Storyblocks с сине-зеленым развертыванием ETL-процессов массовой загрузки данных в DWH, рассмотрим группу из трех отдельных задач, которые можно было бы логически сгруппировать в повторяющийся шаблон для базы данных:
- запросить хранилище, чтобы узнать, какой цвет неактивен;
- запустить ETL-процесс для неактивного цвета;
- переключите активный цвет в DWH, активировав слой просмотра данных на новый цвет.
В Storyblocks основной ETL-процесс для загрузки баз данных в КХД состоит из параллельных заданий Amazon DMS, за которыми следует серия заданий Apache Spark для создания производных таблиц. Наконец, выполняется массовая коллекция SQL-сценариев, поддерживаемая аналитиками (etl_runner). На следующем рисунке белым цветом выделены стандартные задачи DMS, а синие — группы задач, которые можно развернуть в пользовательском интерфейсе Apache Airflow.
Таким образом, комбинация простых, но эффективных концепций и их практическая реализация в виде механизма TAskGroup в Apache AirFlow помогла дата-инженерам Storyblocks улучшить корпоративные ETL-процессы. Как использовать этот и другие приемы администрирования и эксплуатации Apache AirFlow для дата-инженерии и аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

