 1087
1087 
Рассмотрим, как дата-инженеры Airbnb делятся своим опытом перевода корпоративного Data Lake на Apache HDFS в облачное объектное хранилище AWS S3. Почему пришлось переводить аналитические нагрузки с Apache Hive на Iceberg и Spark, и какие результаты это принесло.
Предыстория: Data Lake на HDFS и Apache Hive
Будучи крупнейшей онлайн-площадкой для размещения и поиска краткосрочной аренды частного жилья по всему миру, Airbnb уделяет много внимания данным и работе с ними. Исторически корпоративное озеро данных компании размещалось на кластерах Apache Hadoop HDFS, а затем было перенесено на AWS S3, чтобы обеспечить лучшую стабильность и масштабируемость. Хотя изменение улучшило надежность и стабильность рабочих нагрузок, работающих с данными, это облачное объектное хранилище имеет некоторые ограничения масштабируемости и производительности, что негативно сказывалось на пользовательском опыте клиентов платформы.
В частности, с ростом числа разделов нагрузка на Apache Hive стала узким местом, замедляя операции с разделами, например, запросы к тысячам разделов для получения данных за месяц. В качестве обходного пути дата-инженеры Airbnb добавляли этап ежедневной агрегации и хранили 2 таблицы для запросов с разной степенью детализации по времени, к примеру, ежечасно и ежедневно. Чтобы сэкономить место в хранилище, промежуточные дневные таблицы Hive имели ограниченный срок хранения, равный 3 дня, а ежедневные таблицы сохранялись для более длительного хранения на несколько лет в другое место.
Впрочем, NoSQL-СУБД Hive изначально не предназначен для хранения объектов, это средство стека SQL-on-Hadoop для доступа к данным в HDFS средствами стандартных SQL-запросов. После перехода с HDFS на S3 потребовались определенные усилия, чтобы гарантировать согласованность наборов данных в операциях списка после записи. Для этого был настроен способ записи из Hive в S3 через временный кластер HDFS с последующим перемещением данных в S3 с помощью утилиты распределенного копирования distcp, которая записывает данные в уникальные местоположения, фиксируя информацию о списках файлов в отдельном хранилище для быстрого доступа. Этот инструмент для копирования внутри и между крупномасштабными кластерами Hadoop использует MapReduce для реализации распределения файлов, обработки ошибок и восстановления, а также создания соответствующих отчетов. В целом этот процесс, о котором мы подробно рассказывали здесь, работает без нареканий, но требует дополнительных ресурсов кластера.
В Airbnb используется 3 вычислительных механизма для доступа к данным в корпоративном хранилище: Apache Spark, Trino и Hive. Каждый из них обрабатывает изменения схемы данных по-своему. Поэтому изменения в схемах таблиц почти всегда приводили к проблемам с качеством данных или требовали от дата-инженеров выполнения дорогостоящей перезаписи. В частности, таблицы Hive разделены по фиксированным столбцам, и изменить их не так-то легко. Если нужно перераспределить набор данных, приходится создать новую таблицу и перезагружать весь датасет. Это долго и требует много усилий, поэтому дата-инженеры Airbnb решили обновить инфраструктуру хранилища данных до нового стека на основе Apache Iceberg и Spark 3, чтобы решить эти проблемы, а также повысить удобство сопровождения и использования своего Data Lake. Как это было реализовано, мы рассмотрим далее.
Переход на Apache Spark и Iceberg
Apache Iceberg — это открытый формат таблиц, предназначенный для устранения некоторых недостатков традиционных форматов хранения данных на основе файловой системы, таких как Hive. Iceberg предназначен для высокопроизводительного чтения огромных аналитических таблиц с такими функциями, как сериализуемая изоляция, перемещение во времени на основе моментальных снимков и предсказуемая эволюция схемы. Некоторые важные функции Iceberg помогают решить некоторые из вышеупомянутых проблем:
- информация о разделах уже не хранится в хранилище метаданных Hive, что устраняет большую нагрузку на него;
- таблицы Iceberg не требуют списков S3, что устраняет требование согласованности списка после записи и не требует дополнительного задания distcp, позволяя полностью избежать задержки операции списка;
- согласованная схема таблицы определена в спецификации Iceberg, что гарантирует согласованное поведение всех вычислительных механизмов, избегая неожиданного поведения при изменении столбцов.
Подробнее про сравнение Apache Hive и Iceberg читайте в нашей новой статье. Благодаря адаптивной оптимизации запросов (Adaptive Query Execution, AQE) в Apache Spark 3 выполнение SQL-запросов стало намного быстрее. Напомним, AQE использует статистику времени выполнения для оптимизации плана выполнения запросов Spark SQL. Это решает одну из самых больших проблем CBO-оптимизации (на основе затрат), связанную с неточной статистикой, собранной до начала запроса, что часто приводит к неоптимальным планам их выполнения. AQE определяет характеристики данных и улучшает планы запросов по мере их выполнения, повышая производительность. Примечательно, что Spark 3 является необходимым условием для внедрения Iceberg, поскольку поддержка записи и чтения таблиц Iceberg с использованием Spark SQL доступна только с 3-ей версии этого вычислительного фреймворка.
В Airbnb платформа приема данных на основе Hive обрабатывала более 35 миллиардов сообщений о событиях Kafka и более 1000 таблиц в день, размещая наборы данных размером от килобайт до терабайт в почасовые и дневные разделы. Объем и охват наборов данных разного размера, а также требования к временной детализации позволяют рассматривать эту платформу в качестве реального кандидата на совместное использование Spark и Iceberg.
Чтобы перейти на этот стек технологий, сперва нужно переместить запросы Hive в Spark. Но, в отличие от Hive, который опирается на статистику объема данных, Apache Spark использует предустановленные значения разделов в случайном порядке для определения размеров разделения задач. Поэтому выбор правильного количества разделов в случайном порядке стал проблемой при настройке среды приема данных о событиях в Spark. Объем данных разных событий сильно различается, и размер данных одного события также меняется со временем.
Нет универсального значения количества разделов в случайном порядке, которые бы хорошо работали для всех событий при загрузке данных: если выбрать фиксированное число для всех заданий приема, оно может быть слишком большим для одних заданий и слишком маленьким для других, что приведет к низкой производительности. Впрочем, эту проблему решает AQE.
В Spark 3.0 инфраструктура AQE поставляется с несколькими ключевыми функциями, включая динамическое переключение стратегий соединения и динамическую оптимизацию перекосов, т.е. операций с неравномерно распределенными данными. Для Airbnb наиболее важной функцией стало динамическое соединение разделов в случайном порядке, которое гарантирует, что каждая задача Spark работает примерно с одним и тем же объемом данных. Это достигается путем соединения соседних небольших разделов в более крупные во время выполнения. Поскольку данные в случайном порядке могут динамически увеличиваться или уменьшаться между различными этапами задания, AQE постоянно повторно оптимизирует размер каждого раздела путем соединения на протяжении всего жизненного цикла задания. Это дает наибольшой прирост производительности.
В случае Airbnb оптимизатор AQE хорошо обрабатывал все сценарии в структуре приема данных, включая крайние случаи новых событий. Выравнивание вложенных столбцов и сжатие формата хранения файлов, в т.ч. Parquet GZIP, могут генерировать очень маленькие выходные файлы для небольших разделений задач. Однако, Apache Spark, как и Hadoop, не очень эффективно работает с большим количеством мелких файлов, о чем мы писали здесь и здесь. Чтобы размеры выходных файлов были достаточно большими для эффективного доступа, можно увеличить размер раздела рекомендуемого перемешивания AQE.
Если фактическое используемое перемешивание разделов равно заданному начальному номеру раздела, следует увеличить начальный номер раздела, чтобы больше разделить первоначальные задачи и добиться их соединения. Если средний размер выходного файла слишком мал, можно увеличить рекомендуемый размер раздела, чтобы создать более крупные разделы в случайном порядке и иметь более крупные выходные файлы. После проверки данных перемешивания каждой задачи можно уменьшить память исполнителя и максимальное количество исполнителей.
Эксперименты дата-инженеров Airbnb с настроенными параметрами задания на наборах данных разного размера показали, что после настройки AQE одинаково хорошо работает с наборами данных размером от 0 байтов до ТБ, с любыми параметрами Spark-задания.
Таким образом, AQE может регулировать размер разделения в случайном порядке близко к предопределенному значению на этапе Reduce и, таким образом, генерировать выходные данные целевого размера файла. Кроме того, поскольку каждое разбиение в случайном порядке близко к предопределенному значению, можно уменьшить объем памяти исполнителя по сравнению со значениями по умолчанию, чтобы обеспечить эффективное распределение ресурсов. А благодаря возможностям Apache Spark дата-инженерам не нужно дополнительно выполнять какую-либо специальную обработку, чтобы добавить новые наборы данных.
Кроме того, можно воспользоваться преимуществами гибкости Iceberg для определения нескольких спецификаций разделов для консолидации полученных данных с течением времени. Каждый файл данных, записанный в многораздельной таблице Iceberg, принадлежит ровно одному разделу, но можно контролировать степень детализации значений раздела с течением времени. Принятые таблицы записывают новые данные с почасовой детализацией (ds/hr), а ежедневный автоматизированный процесс сжимает файлы в ежедневном разделе (ds) без потери почасовой гранулярности, которую позже можно применить к запросам в качестве остаточного фильтра.
Процесс сжатия определяет, требуется ли перезапись данных для достижения оптимального размера файла, или достаточно просто перезаписать метаданные для назначения уже существующих файлов данных ежедневному разделу. Это упрощает процесс приема данных о событиях и предоставляет пользователю консолидированное представление данных в одной таблице. В консолидированной таблице Iceberg спецификация раздела переключается с ds/hr на ds в конце дня. Писать пользовательские запросы стало проще, а также можно получить доступ к более свежим данным с полной историей. Хранение только одной копии данных также помогает повысить эффективность вычислений и обеспечивает согласованность данных.
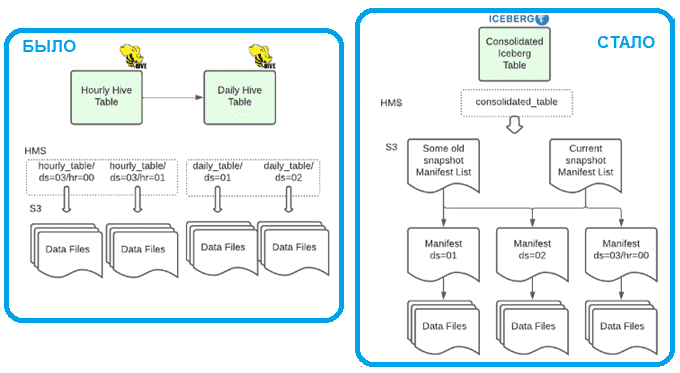
Консолидация почасовых и ежедневных данных в одну таблицу Iceberg требует изменений как в пути записи, так и в пути чтения. Для пути записи, чтобы смягчить проблемы, вызванные маленькими файлами, дата-инженеры Airbnb принудительно запускают сжатие во время переключения спецификации раздела. Отдельные таблицы Iceberg сравнивают статистику интеллектуальных заданий уплотнения со стоимостью полной перезаписи всех файлов данных, связанных с ежедневным разделом. Благодаря способности Iceberg избегать копирования данных во время сжатия для некоторых больших таблиц экономия ресурсов составляет более 90%.
Для пути чтения, поскольку большинство потребителей данных используют сенсоры разделов Airflow , обновлена реализация распознавания разделов. Напомним, сенсоры или датчики в Apache AirFlow – это особый тип операторов, которые предназначены для выполнения ровно одной задачи — ожидания, когда что-то произойдет, например, загрузится файл, будет получен ответ от внешней системы и пр. Подробно об этом мы рассказывали здесь. Дата-инженеры Airbnb внедрили систему сигналов для обнаружения пустых разделов в таблицах Iceberg. Изменив ранее используемый метод поиска каждого раздела Hive как фактической строки в хранилище метаданных.
Сравнив использование Hive с новым стеком на Spark 3 и Iceberg, дата-инженеры Airbnb пришли к выводу, что экономия вычислительных ресурсов составила более 50%, а выполнение заданий ускорилось на 40 % в новой структуре приема данных. Дополнительным преимуществом стало повышение удобства использования хранимых данных благодаря возможностям Iceberg для эволюции собственной схемы и разделов таблиц.
Больше подробностей про администрирование и эксплуатацию Apache Hive и других компонентов экосистемы Hadoop для хранения и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

