Чем полезна поддержка gRPC в Clickhouse и как ее реализовать: разбираем интерфейс удаленного вызова процедур на примере потоковой вставки событий пользовательского поведения из Kafka в таблицу колоночной базы данных со стриминговым выводом. Поддержка gRPC в ClickHouse ClickHouse поддерживает gRPC – фреймворк от Google и система удаленного вызова процедур с открытым...
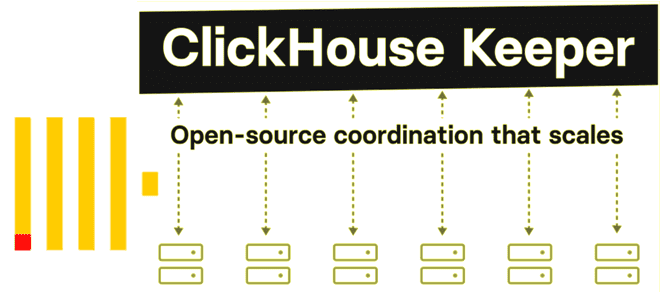
Что не так с Apache Zookeeper и почему разработчики ClickHouse решили заменить его на встроенный сервис синхронизации метаданных на базе RAFT-протокола с линеаризацией записи и чтения. Как работает ClickHouse Keeper и где его настроить. Что не так с Apache Zookeeper Многие распределенные системы, которые состоят из нескольких узлов, для обеспечения...
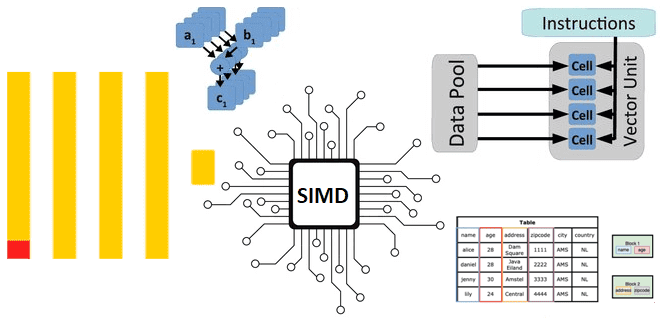
Как ClickHouse реализует параллельные векторные вычисления над большим объемом данных на любых аппаратных платформах: диспетчеризация ЦП для выполнения SIMD-инструкций в сложных функциях. Реализация векторных вычислений в ЦП Как мы уже отмечали здесь, ClickHouse имеет встроенную поддержку векторных вычислений, когда при выполнении одной инструкции процессора производится не одна операция, а одновременно...

Что такое Observability и чем ClickHouse хорош для обеспечения наблюдаемости, как хранить журналы и трассировки в этой колоночной базе данных и для чего реализована интеграция с OpenTelemetry. Что такое Observability и чем ClickHouse хорош для обеспечения наблюдаемости Будучи колоночной базой данных, ClickHouse отлично подходит для мониторинга и анализа системных метрик,...
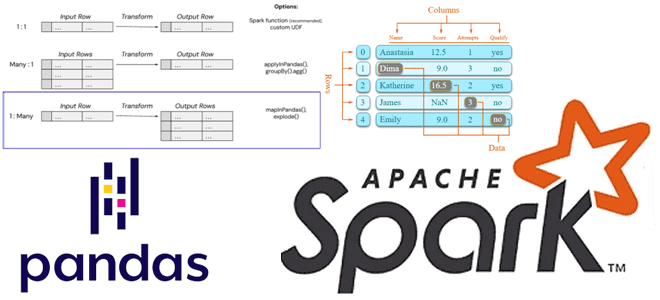
Как применить пользовательскую функцию Python к объектам pandas в распределенной среде Apache Spark. Варианты использования Pandas UDF, applyInPandas() и mapInPandas() на практических примерах. Разница между Pandas UDF, applyInPandas и mapInPandas в Apache Spark Недавно я показывала пример сравнения быстродействия метода applyInPandas() с функцией apply() библиотеки pandas. Однако, помимо applyInPandas() в...
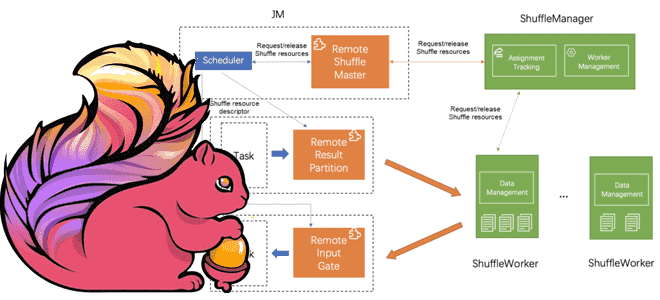
Что такое Remote Shuffle Service в Apache Flink, зачем это нужно и как служба удаленного перемешивания позволяет создавать масштабируемые и надежные приложения для унифицированной потоковой и пакетной обработки больших объемов данных. Что такое Remote Shuffle Service в Apache Flink Apache Flink рассматривает пакетную обработку как частный случай потоковых вычислений. Однако,...

4 октября 2024 года вышел очередной релиз ClickHouse. Знакомимся с его самыми интересными особенностями: добавление строк в обновляемые материализованные представления, агрегатные функции для типов данных JSON и Dynamic, поддержка заголовков HTTP-ответов, автозамена строк с overlay-командами и другие новинки выпуска 24.9. Обновляемые материализованные представления Начнем с наиболее значимой новой функции ClickHouse...

Чем метод applyInPandas() в Spark отличается от apply() в pandas и насколько он быстрее обрабатывает данные: сравнительный тест на датафрейме из 5 миллионов строк. Методы применения пользовательских функций к датафреймам в Spark и pandas Мы уже отмечали здесь и здесь, что Apache Spark позволяет работать с популярной Python-библиотекой pandas, поддерживая...
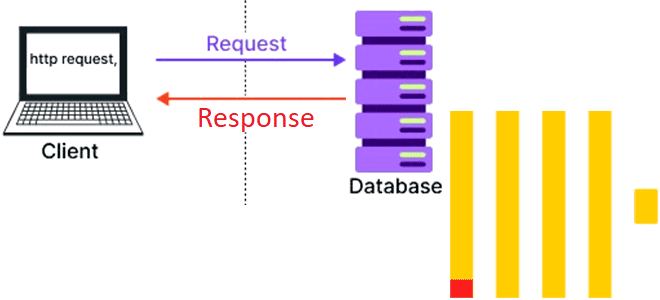
Как реализовать систему с двухзвенной архитектурой на ClickHouse и браузере. Возможности колоночной СУБД для создания одностраничных веб-приложений. Возможности ClickHouse для одностраничных веб-приложений Хотя трехзвенная архитектура (клиент -> бэк-> база данных) уже давно стала стандартом де-факто в разработке веб-приложений, двухзвенная архитектура, когда бизнес-логика переносится в базу данных, до сих пор встречается....
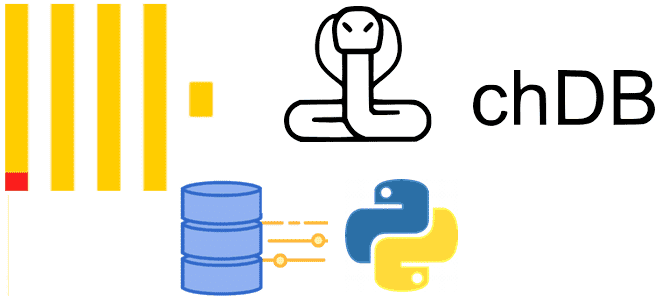
Что такое Chdb, зачем нужна эта библиотека и как ее использовать в коде Python-приложения для анализа больших данных в ClickHouse без разворачивания полноценного сервера этой колоночной СУБД. Как и зачем работать с ClickHouse без сервера СУБД ClickHouse является мощным инструментом аналитики больших данных, который требует соответствующей инфраструктуры. Однако, иногда нужно...