 1121
1121 
Чем метод applyInPandas() в Spark отличается от apply() в pandas и насколько он быстрее обрабатывает данные: сравнительный тест на датафрейме из 5 миллионов строк.
Методы применения пользовательских функций к датафреймам в Spark и pandas
Мы уже отмечали здесь и здесь, что Apache Spark позволяет работать с популярной Python-библиотекой pandas, поддерживая работу с датафреймами в PySpark. С 2023 года эта, изначально локальная, библиотека стала лучше поддерживаться в распределенной среде Spark благодаря колоночному формату PyArrow, отложенным вычислениям и другим нововведениям. При этом ее функции похожи на аналогичные реализации Apache Spark, однако отличаются от них контекстом использования. Например, applyInPandas() в Spark и apply() в pandas выполняют схожие действия, но предназначены для работы в разных контекстах и с разными типами данных.
В частности, apply() — это метод библиотеки pandas, который применяется к датафреймам pandas или индексируемым одномерным массивам (Series) для выполнения пользовательской функции. Он удобен для работы с небольшими наборами данных, которые могут поместиться в памяти. Аналогичные выполнять пользовательские функции над датафреймами pandas в Spark позволяет выполнять метод applyInPandas(), который используется для работы с большими наборами данных, распределёнными между узлами кластера. Apply() в pandas работает в однопоточном режиме и ограничен памятью одного компьютера, тогда как applyInPandas() в Spark позволяет обрабатывать данные параллельно, распределяя их между узлами, обеспечивая эффективную обработку больших объёмов данных.Apply() в pandas применяется к датафрейму или объектам Series и вызывает функцию, которая принимает строку или столбец в виде ряда. Метод applyInPandas() в Spark принимает датафрейм pandas и возвращает структуру данных того же типа.
Покажем различия между применением этих функций на примере довольно большого датафрейма.
В качестве примера сгенерируем датафрейм Spark из 5 миллионов строк, который включает данные о 100 пользователях, каждый из которых делает 1000 событий пользовательского поведения.
# Установка необходимых библиотек
!pip install pyspark
!pip install faker
# Импорт необходимых модулей из pyspark
import pyspark
from pyspark.sql import SparkSession
import random
import pandas as pd
from pyspark.sql.functions import rand
from datetime import datetime, timedelta #для работы с датами и временем
import numpy as np
import time
# Импорт модуля faker
from faker import Faker
from faker.providers.address.ru_RU import Provider
# Импорт модуля faker
from faker import Faker
from faker.providers.address.ru_RU import Provider
# Создание объекта SparkSession
spark = SparkSession.builder.appName("GenerateDataFrame").getOrCreate()
# Создание объекта Faker с локализацией для России
fake = Faker('ru_RU')
# Виды событий
events = ['click', 'download', 'scroll', 'submit']
# Задаем стартовую и конечную даты
start_date = pd.Timestamp(year=2020, month=1, day=1)
end_date = pd.Timestamp.now()
# Генерация случайной даты в заданном диапазоне
def random_date(start_date, end_date):
delta = (end_date - start_date).days
random_days = np.random.randint(0, delta + 1)
return (start_date + timedelta(days=random_days)).date()
# Генерация датафрейма
def generate_initial_df(num_users, num_events_per_user):
data = []
for _ in range(num_users):
user_email = fake.free_email()
for _ in range(num_events_per_user):
event = random.choice(events)
event_date = random_date(start_date, end_date)
data.append((user_email, event, event_date))
# Создание Spark DataFrame
columns = ['user', 'event', 'event_date']
df = spark.createDataFrame(data, columns)
return df
# Количество пользователей и событий на пользователя
num_users = 100
num_events_per_user = 5000
# Генерация датафрейма
df = generate_initial_df(num_users, num_events_per_user)
df.show()
В этом коде внутри цикла для каждого пользователя генерируется заданное количество событий, и они добавляются в список data, который затем преобразуется в датафрейм Spark.
Чтобы применить операции pandas к группам датафрейма Spark, можно использовать функцию applyInPandas(), которая сопоставляет каждую группу текущего значения датафрейма с помощью udf-функции pandas и возвращает результат в виде датафрейма. Cхему возвращаемого датафрейма надо определить заранее, чтобы PyArrow мог эффективно сериализовать ее. Функция applyInPandas() используется для операций, которые надо выполнять в отдельных группах параллельно. Это может быть полезно, когда надо обрабатывать данные по некоторым определенным ключам, например, по группам пользователей и событий.
Функция applyInPandas() принимает датафрейм pandas и возвращать в ответ другой датафрейм pandas согласно описанной схеме. Метки столбцов возвращаемого датафрейма pandas должны соответствовать именам полей в схеме, если они указаны как строки, или типам данных полей по положению, если они не являются строками, например, целочисленные индексы. Эта функция требует полной перетасовки. Все данные группы загружаются в память, что потенциально опасно возникновением OOM-ошибки, если данные распределены слишком неравномерно, а некоторые группы чересчур велики для размещения в памяти.
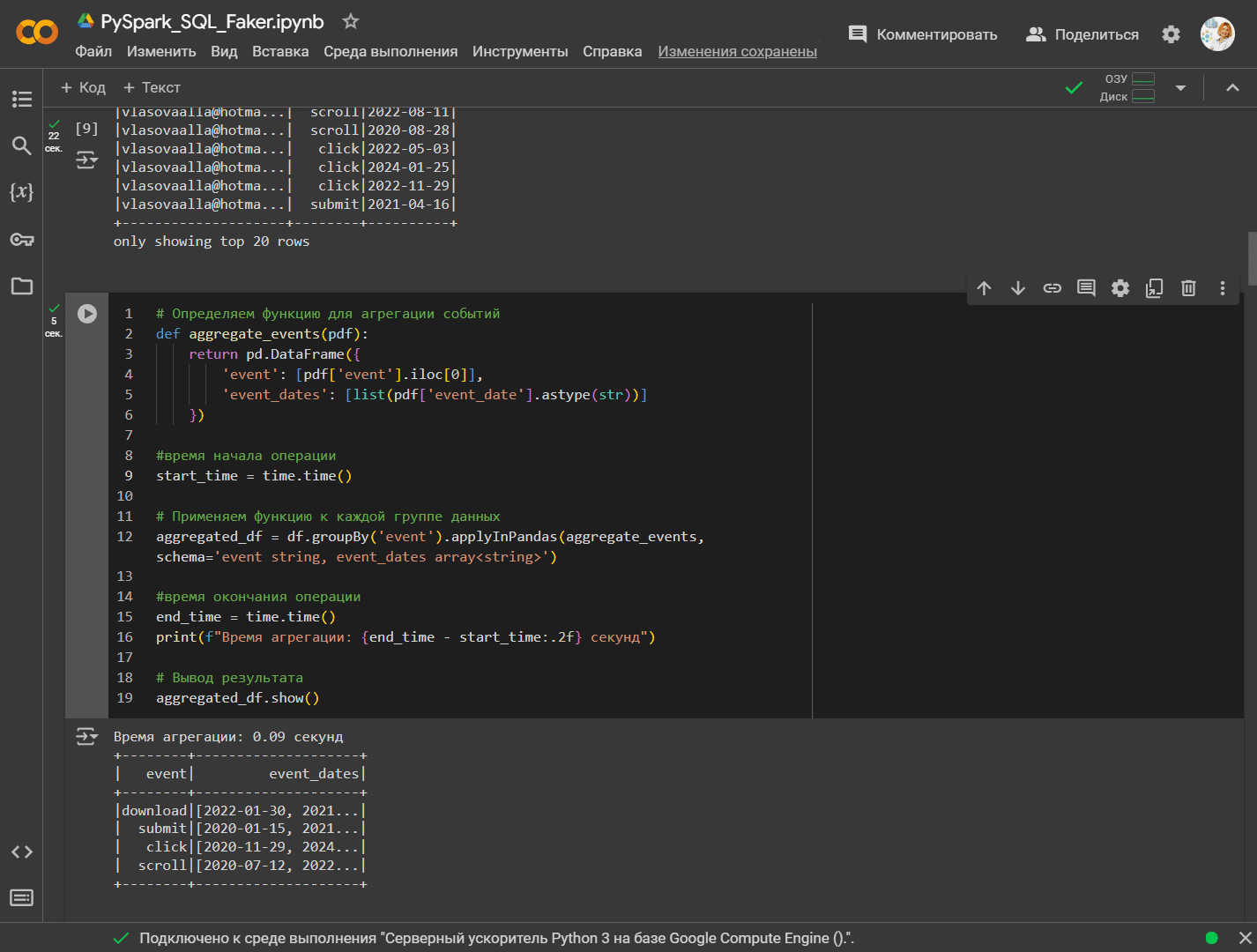
В нашем примере запустим пользовательскую агрегацию в pandas, которая уменьшает гранулярность датафрейма до столбца event. Столбец event_time будет преобразован в список значений по event. Выходными данными будет одна строка по event. Чтобы выполнить пользовательскую агрегацию в Pandas , которая уменьшает гранулярность датафрейма до столбца event, и преобразует столбец event_date в список значений по каждому событию, необходимо сначала преобразовать датафрейм Spark в аналогичную структуру данных pandas. После этого можно использовать методы агрегации pandas для выполнения задачи. Следующий код агрегирует события, группируя их по типу события, и создает массивы дат для каждого события:
# Определяем функцию для агрегации событий
def aggregate_events(pdf):
return pd.DataFrame({
'event': [pdf['event'].iloc[0]],
'event_dates': [list(pdf['event_date'].astype(str))]
})
#время начала операции
start_time = time.time()
# Применяем функцию к каждой группе данных
aggregated_df = df.groupBy('event').applyInPandas(aggregate_events, schema='event string, event_dates array<string>')
#время окончания операции
end_time = time.time()
print(f"Время агрегации: {end_time - start_time:.2f} секунд")
# Вывод результата
aggregated_df.show()
Функция aggregate_events() преобразует даты в строки, поскольку в Spark массивы состоят из простых типов данных, таких как строки. Метод astype(str) используется, чтобы гарантировать, что даты преобразуются в строки, прежде чем помещаться в массив. Чтобы сравнить быстродействие метода applyInPandas() в Spark с apply() в pandas, в код добавлены расчеты времени выполнения операции.
Выполним аналогичную агрегацию, используя метод apply() библиотеки pandas, чтобы сравнить, насколько applyInPandas() работает быстрее. Для этого надо преобразовать исходный Spark-датафрейм в аналогичную структуру данных pandas, а затем выполнить над ней агрегацию.
# Преобразование Spark DataFrame в Pandas DataFrame
start_time = time.time() #время начала преобразования
pdf = df.toPandas()
end_time = time.time() #время окончания преобразования
print(f"Время преобразования в Pandas DataFrame: {end_time - start_time:.2f} секунд")
# Определяем функцию для агрегации событий
def aggregate_events(group):
return pd.Series({
'event': group['event'].iloc[0],
'event_dates': list(group['event_date'].astype(str))
})
# Применяем функцию к каждой группе данных
start_time = time.time() #время начала агрегации
aggregated_pdf = pdf.groupby('event', group_keys=False).apply(aggregate_events).reset_index(drop=True)
end_time = time.time() #время окончания агрегации
print(f"Время агрегации: {end_time - start_time:.2f} секунд")
# Вывод результата
aggregated_df.show()
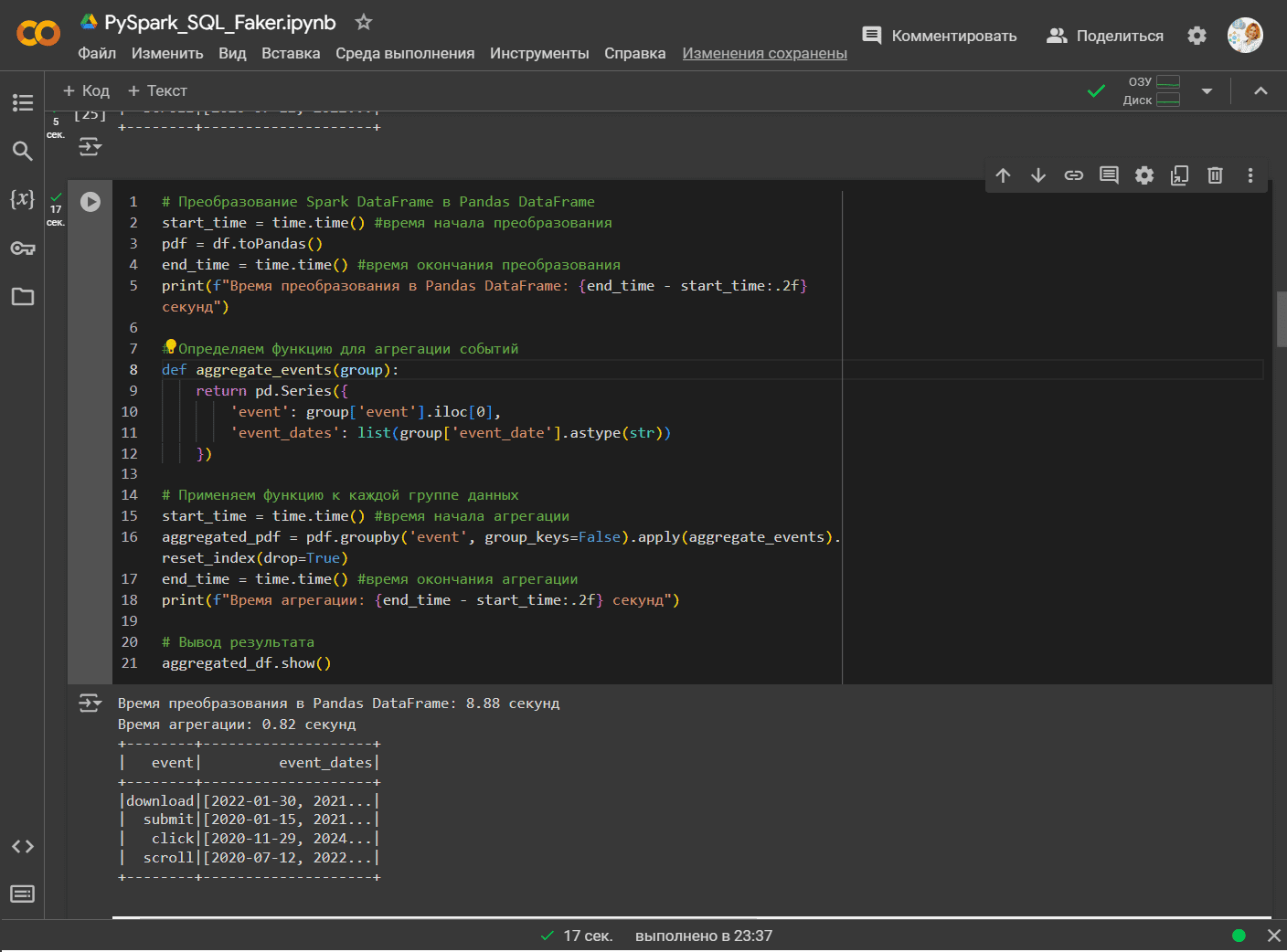
Эксперимент показал, что applyInPandas() в Spark работает почти в 10 раз быстрее, чем apply() библиотеки pandas: 0,09 секунд против 0.82. Такая разница обусловлена тем, что в фоновом режиме Spark использует PyArrow для сериализации каждой группы в датафрейм pandas и параллельного выполнения вычислений, которые определены для каждой группы. Когда группировки слишком велики для того, чтобы поместиться в памяти для обработки традиционной Python-библиотекой pandas, функция applyInPandas() позволяет распределить групп данных по кластеру. Набор данных из 5 миллионов строк является довольно большим, поэтому его обработка с помощью applyInPandas() выполняется быстрее.
Таким образом, apply() в pandas, отлично подходит для работы с небольшими наборами данных, которые можно обработать в памяти одного компьютера, а applyInPandas() в Spark хороша для параллельной обработки больших датафреймов, распределёнными между узлами кластера. Читайте в нашей новой статье, чем функция отличается applyInPandas() от mapInPandas().
Узнайте больше про использование Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

