 684
684 
Содержание
Что такое Observability и чем ClickHouse хорош для обеспечения наблюдаемости, как хранить журналы и трассировки в этой колоночной базе данных и для чего реализована интеграция с OpenTelemetry.
Что такое Observability и чем ClickHouse хорош для обеспечения наблюдаемости
Будучи колоночной базой данных, ClickHouse отлично подходит для мониторинга и анализа системных метрик, обеспечивая основу для наблюдаемости микросервисов и информационных систем. Тем не менее, сам по себе ClickHouse не является готовым решением для мониторинга, хотя его можно использовать как высокоэффективный механизм хранения данных об изменении системных метрик. Для этого нужен пользовательский интерфейс и фреймворк сбора данных. Наиболее распространенными примерами этих компонентов Observability сегодня считаются Grafana и OpenTelemetry. ClickHouse имеет официально поддерживаемые интеграции с обоими этими системами.

ClickHouse идеально подходит для хранения данных о наблюдаемости по следующим причинам:
- Высокий коэффициент сжатия данных. Данные Observability обычно содержат поля, значения для которых берутся из отдельного набора, например, кодов HTTP-ответов или названий сервисов. Колоночный характер ClickHouse, где значения хранятся отсортированными, означает, что эти данные сжимаются очень хорошо — особенно в сочетании с рядом специализированных кодеков для данных временных рядов. ClickHouse отлично сжимает логи и трассировки. Это не только экономит место в хранилище, но и ускоряет выполнение запросов, поскольку с диска нужно считывать меньше данных.
- Быстрые агрегации. Решения по наблюдению обычно включают визуализацию данных с помощью различных диаграмм, агрегируя и фильтруя данные по определенным признакам. Колоночный формат ClickHouse вместе с векторизованным механизмом выполнения запросов идеально подходит для быстрых агрегаций, а разреженная индексация позволяет быстро фильтровать данные.
- Быстрое линейное сканирование. Обычно инвертированные индексы для быстрого запроса журналов приводят к высокому потреблению ресурсов. В ClickHouse инвертированные индексы используются как дополнительный механизм, а основным является линейное параллельное сканирование данных, которое использует все доступные ядра ЦП, если не настроено иное. Это потенциально высокооптимизированным операторам сопоставления текста позволяет сканировать 10 ГБ в секунду.
- Поддержка SQL, который знаком каждому инженеру данных и отлично подходит для запросов данных о мониторинге системных метрик.
- Наличие аналитических функций. ClickHouse расширяет ANSI SQL аналитическими функциями. Например, так можно разбить данные наблюдаемости на срезы и кубы для многомерного анализа.
- Вторичные индексы. ClickHouse поддерживает вторичные индексы, такие как фильтры Блума, для ускорения определенных профилей запросов. Их можно опционально включить на уровне столбцов, увеличивая контроль за аналитической обработкой данных.
- Открытый исходный код и открытые стандарты. Будучи проектом с открытым исходным кодом, ClickHouse принимает открытые стандарты, такие как Open Telemetry.
В настоящее время рекомендуется использовать ClickHouse для хранения следующих типов данных Observability:
- Журналы — это записи событий, происходящих в системе, с отметкой времени, которые содержат подробную информацию о различных аспектах работы системы. Данные в таких логах обычно неструктурированы и могут включать сообщения об ошибках, действиях пользователей, системные изменения и другие события. Журналы очень важны для устранения неполадок, обнаружения аномалий и понимания событий, приводящих к проблемам.
- Трассировки, которые фиксируют путь запросов, проходящих через различные службы в распределенной системе, детализируя их путь и производительность. Данные в трассировках имеют высокую степень структурированности, состоят из интервалов и трассировок, которые отображают каждый шаг запроса, включая информацию о времени. Каждая трассировка состоит из нескольких интервалов, при этом начальный интервал, связанный с запросом, называется корневым интервалом. Этот корневой интервал охватывает весь запрос от начала до конца. Последующие интервалы под корнем предоставляют подробную информацию о различных шагах или операциях, которые происходят во время запроса. Трассировки предоставляют информацию о производительности системы, помогая выявлять узкие места и проблемы с задержкой обработки данных, чтобы оптимизировать эффективность микросервисов. Распределенная трассировка отображает путь запроса от конечного пользователя или приложения по всей системе, что обычно приводит к потоку действий между микросервисами. Регистрация этой последовательности и сопостовление событий позволяет SRE-инженеру диагностировать проблемы даже в сложных событийно-ориентированных архитектурах.
В 2024 году разработчики ClickHouse начали официально поддерживать экспортер OpenTelemetry для логирования и трассировки. Что это такое и как устроена интеграция OpenTelemetry и ClickHouse, рассмотрим далее.
Интеграция OpenTelemetry с ClickHouse
OpenTelemetry (OTel) — это фреймворк с открытым исходным кодом от Cloud Native Computing Foundation (CNCF), который обеспечивает стандартизированный сбор, обработку и экспорт телеметрических данных. OTel обеспечивает унифицированный подход, позволяющий разработчикам и SRE-инженерам получать информацию о состоянии сервисов и диагностировать проблемы в распределенных системах. OTel также предоставляет библиотеки инструментов для нескольких языков, которые автоматизируют сбор данных с минимальными изменениями кода. OTel Collector управляет этим потоком данных, выступая в качестве шлюза для экспорта данных телеметрии на различные внутренние платформы. Предлагая единый стандарт наблюдаемости, OTel помогает эффективно собирать данные телеметрии и получать информацию о сложных системах. Открытый характер OpenTelemetry избавляет от привязки к какому-либо одному инструменту мониторинга, позволяя использовать различные средства. Стандартизированный формат данных телеметрии упрощает интеграцию между системами, даже в многооблачных и гибридных средах.
Ключевым компонентом стека Observability на основе SQL является сборщик OpenTelemetry (Collector). Сборщик OTel собирает данные телеметрии из SDK или других источников и пересылает их на поддерживаемый бэкэнд, действуя как централизованный хаб для получения, обработки и экспорта системных метрик. Сборщик OTel может функционировать как локальный сборщик для одного приложения (агент) или как централизованный сборщик для нескольких приложений (шлюз).
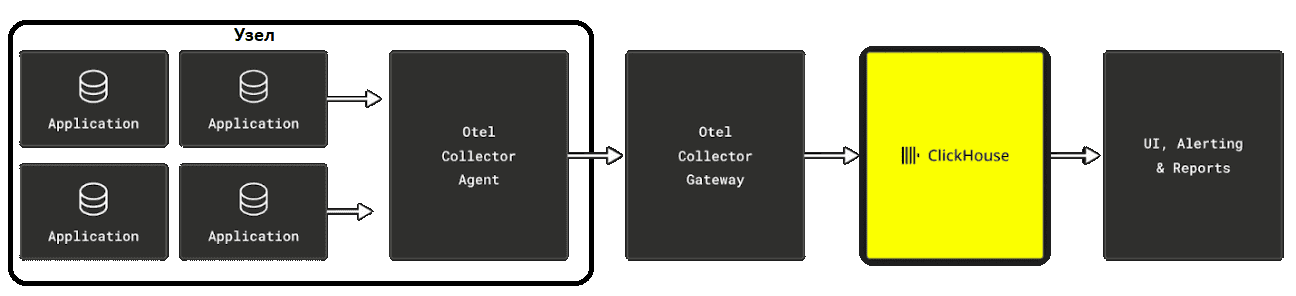
Сборщик OTel включает ряд экспортеров, которые поддерживают различные форматы данных. Экспортеры отправляют данные на выбранный бэкэнд или платформу наблюдения, например ClickHouse. Можно настроить несколько экспортеров для маршрутизации данных телеметрии в различные пункты назначения. OTel Exporter для ClickHouse уже используется в производстве, позволяя унифицировать подход к ханению и поиску журналов и трассировок благодаря единой схеме. Схема по умолчанию подходит для сценариев телеметрии и может быть кастомизирована под какой-то конкретный случай. Для этого надо понять, как данные хранятся в ClickHouse, и выбрать соответствующий первичный ключ. Например, команда разработки ClickHouse сделала это для своего внутреннего решения журналирования, которое хранит более 43 петабайт данных OTel (по состоянию на октябрь 2024 г.).
Экспортер создаст необходимые таблицы по умолчанию, но это не рекомендуется для производственных рабочих нагрузок. Если надо заменить схему таблицы, не изменяя код экспортера, можно просто создать таблицы самостоятельно. Файл конфигурации просто определяет имена таблиц, в которые будут отправляться данные. Для этого имена столбцов должны соответствовать тем, что вставляет экспортер, а типы — быть совместимыми с базовыми данными.
Пример события журнала, созданного OpenTelemetry, выглядит так:
{
"Timestamp":"2024-06-15 21:48:06.207795400",
"TraceId":"10c0fcd202c978d6400aaa24f3810514",
"SpanId":"60e8560ae018fc6e",
"TraceFlags":1,
"SeverityText":"Information",
"SeverityNumber":9,
"ServiceName":"cartservice",
"Body":"GetCartAsync called with userId={userId}",
"ResourceAttributes":{
"container.id":"4ef56d8f15da5f46f3828283af8507ee8dc782e0bd971ae38892a2133a3f3318",
"docker.cli.cobra.command_path":"docker%20compose",
"host.arch":"",
"host.name":"4ef56d8f15da",
"telemetry.sdk.language":"dotnet",
"telemetry.sdk.name":"opentelemetry",
"telemetry.sdk.version":"1.8.0"
},
"ScopeName":"cartservice.cartstore.RedisCartStore",
"ScopeAttributes":{
},
"LogAttributes":{
"userId":"71155994-7b72-428a-9d51-43962a82ae43"
}
}
Если нужная схема данных сильно отличается от той, что предоставляется по умолчанию, можно использовать материализованное представление ClickHouse. При моделировании своей схемы таблицы можно включить или исключить определенные столбцы или даже изменить их тип. Например, чтобы извлечь столбцы, связанные с Kubernetes, такие как имена подов, это надо поместить в первичный ключ таблицы, чтобы оптимизировать производительность запросов. Для производственных развертываний рекомендуется отключить создание таблиц по умолчанию, поскольку они могут конфликтовать, если запущено несколько процессов экспортера.
Например, схема таблицы OTel для LogHouse, облачного решения для логирования ClickHouse, выглядит так:
CREATE TABLE otel.server_text_log_0
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`EventDate` Date,
`EventTime` DateTime,
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`Namespace` LowCardinality(String),
`Cell` LowCardinality(String),
`CloudProvider` LowCardinality(String),
`Region` LowCardinality(String),
`ContainerName` LowCardinality(String),
`PodName` LowCardinality(String),
`query_id` String CODEC(ZSTD(1)),
`logger_name` LowCardinality(String),
`source_file` LowCardinality(String),
`source_line` LowCardinality(String),
`level` LowCardinality(String),
`thread_name` LowCardinality(String),
`thread_id` LowCardinality(String),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_thread_id thread_id TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_thread_name thread_name TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_Namespace Namespace TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_source_file source_file TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_scope_attr_key mapKeys(ScopeAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_scope_attr_value mapValues(ScopeAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_log_attr_key mapKeys(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_log_attr_value mapValues(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_body Body TYPE tokenbf_v1(32768, 3, 0) GRANULARITY 1
)
ENGINE = SharedMergeTree
PARTITION BY EventDate
ORDER BY (PodName, Timestamp)
TTL EventTime + toIntervalDay(180)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1;
В этом примере используется составной ключ упорядочивания (PodName, Timestamp). Он оптимизирован для запросов фильтрации данных по этим столбцам. Для всех строковых столбцов с низкой кардинальностью (менее 10 000 уникальных значений) используется тип LowCardinality(String). Этот словарь кодирует строковые значения, обеспечивая эффективное сжатие данных и повышая производительность чтения. Команда ClickHouse использует кодек сжатия по умолчанию для всех столбцов ZSTD на уровне 1, поскольку данные хранятся в AWS S3. Хотя ZSTD может быть медленнее LZ4, его коэффициент сжатия выше и он примерно на 20% быстрее распаковывает данные. Вторичный индекс по ключам и значениям сопоставлений на основе фильтра Блума позволяет быстро оценивать, содержат ли гранулы на диске определенный ключ или значение сопоставления. Этот сокращает время выполнения запросов в ClickHouse. Также недавно введенная поддержка нового типа данных JSON, о чем мы писали здесь, упрощает хранение атрибутов, поиск журналов и трассировок, что очень важно для обеспечения наблюдаемости.
Научиться работать с ClickHouse вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

