 949
949 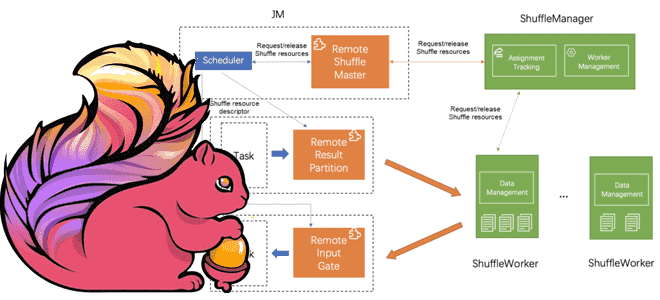
Что такое Remote Shuffle Service в Apache Flink, зачем это нужно и как служба удаленного перемешивания позволяет создавать масштабируемые и надежные приложения для унифицированной потоковой и пакетной обработки больших объемов данных.
Что такое Remote Shuffle Service в Apache Flink
Apache Flink рассматривает пакетную обработку как частный случай потоковых вычислений. Однако, перемешивание, т.е. процесс обмена данными между узлами распределенной системы для потоковых заданий Flink отличается от перемешивания для пакетных заданий. В потоковых заданиях используется конвейерное перемешивание. Хотя данные не хранятся на дисках, все операторы должны быть запущены при запуске потокового задания. Это не соответствует общим требованиям планирования пакетных заданий. Поэтому для пакетных заданий обычно используется блокирующее перемешивание. Таким образом, задача восходящего потока записывает данные перемешивания в файл, а затем потребляет их после запуска задачи нисходящего потока.
По умолчанию Flink использует внутреннюю перетасовку. Данные вышестоящего вычислительного узла записываются на локальный диск диспетчера задач (TaskManager), к которому подключается нижестоящий узел для чтения файла перетасовки. В результате TaskManager не может немедленно выйти после завершения вычислительной задачи, т.е. освободить файл перетасовки, пока он не будет использован нижестоящим узлом. Это приводит к потере ресурсов и увеличивает стоимость аварийного переключения. Поэтому еще в 2022 году в Apache Flink была разработана служба удаленного перемешивания (Remote Shuffle Service, RSS) как подключаемый настраиваемый сервис. RSS использует отдельный кластер, чтобы повысить эффективность утилизации ресурсов и снизить накладные расходы на отказоустойчивость диспетчеров задач. В качестве RSS-службы можно использовать, например, Apache Celeborn.
Также есть гибридное перемешивание, которое объединяет преимущества конвейерного и блокирующего, позволяя записывать данные в память для прямого потребления или на диски для последующего, когда памяти недостаточно, а нижестоящий узел не потребляет данные своевременно. Это позволяет нижестоящему узлу потреблять данные в любое время, как во время, так и после производства данных вышестоящим узлом, устраняя фрагментацию ресурсов. Подробнее об этом мы писали здесь.
Flink Remote Shuffle поддерживает следующие функции:
- разделение хранения и вычислений, чтобы масштабироваться независимо. Вычислительные ресурсы могут быть освобождены после завершения вычислений, стабильность или нестабильность которых не влияет на операции shuffle-операции.
- несколько режимов развертывания, в т.ч. в средах Kubernetes, YARN и Standalone;
- механизм управления трафиком для реализации передачи данных с нулевым копированием. Управляемая память используется в максимальной степени, чтобы избежать ошибок нехватки памяти (Out of Memory, OOM) и улучшить стабильность и производительность системы.
- оптимизации для высокой производительности и стабильности, включая балансировку нагрузки, оптимизацию дискового ввода-вывода, сжатие данных, повторное использование соединений и слияние небольших пакетов.
- проверка корректности shuffle-данных, перезапуски процессов перемешивания и физических узлов;
- динамическая оптимизация выполнения, включая динамическое определение параллелизма операторов.
В основе RSS лежит унифицированный подключаемый интерфейс Shuffle Flink. Как фреймворк обработки данных, который объединяет потоковую и пакетную обработку, Flink может адаптироваться к различным политикам перемешивания в различных сценариях, от конвейерного до блокирующего перемешивания и удаленного обмена на основе удаленных служб. Политики Shuffle различаются по методам передачи и носителям данных, но имеют общие требования к жизненному циклу набора данных, управлению метаданными, уведомлению о задачах нижестоящего уровня и политикам распределения данных. Архитектура плагина Shuffle во Flink выглядит так:
- мастер перемешивания (ShuffleMaster) отвечает за применение и освобождение ресурсов на стороне мастера заданий (JobMaster);
- InputGate и ResultPartition отвечают за чтение и запись данных на стороне TaskManager;
- Планировщик использует ShuffleMaster для подачи заявки на ресурсы и передачи ресурсов в трекер разделов (PartitionTracker). Когда запускаются задачи восходящего и нисходящего потоков, планировщик переносит дескрипторы ресурсов Shuffle для описания расположения вывода и чтения данных.
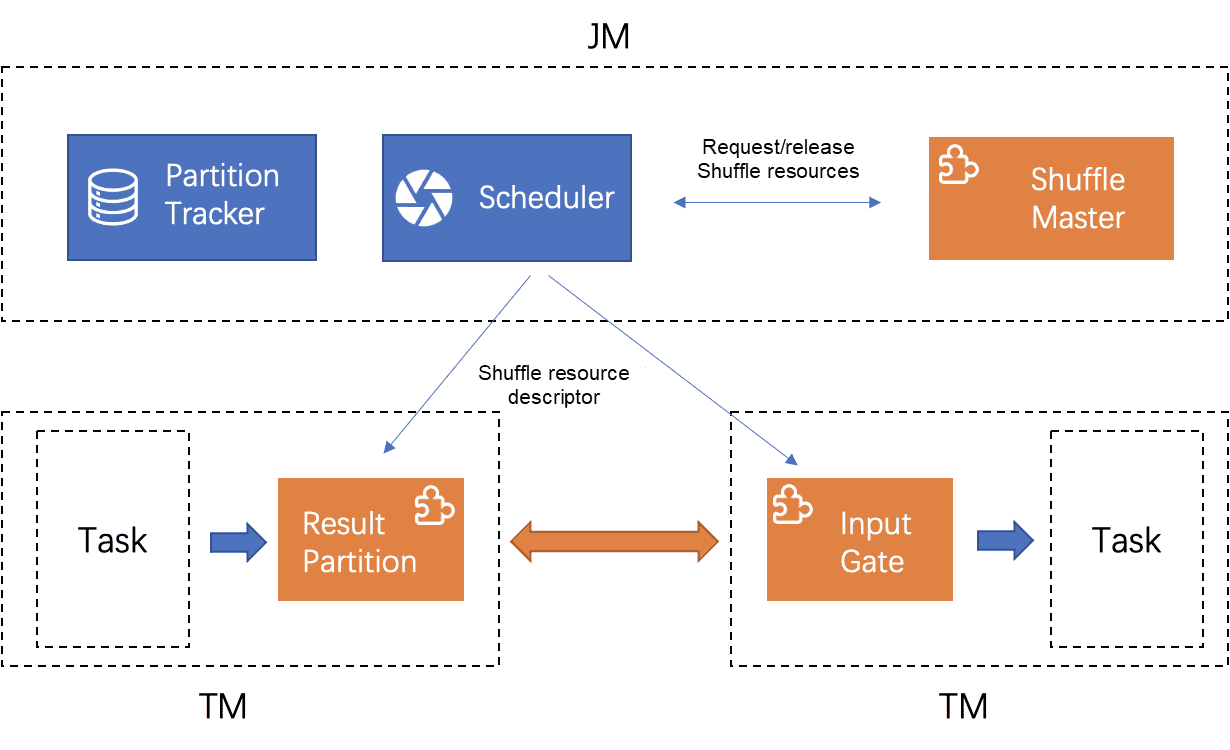
На основе унифицированного подключаемого интерфейса Shuffle Flink, RSS предоставляет сервис перемешивания данных через отдельный кластер архитектуры master-slave. RSS Flink имеет клиент-серверную архитектуру: сервер работает как независимый кластер, а клиент работает в кластере Flink как агент для заданий для доступа к удаленной службе перемешивания. С точки зрения режима развертывания пользователи могут получать доступ к одному и тому же набору служб Shuffle через разные кластеры Flink.
ShuffleManager выступает в качестве главного узла всего кластера, управляет рабочими узлами, а также выделяет и управляет наборами данных Shuffle. ShuffleWorkers выступают в качестве подчиненных узлов кластера и отвечают за чтение, запись и очистку наборов данных.
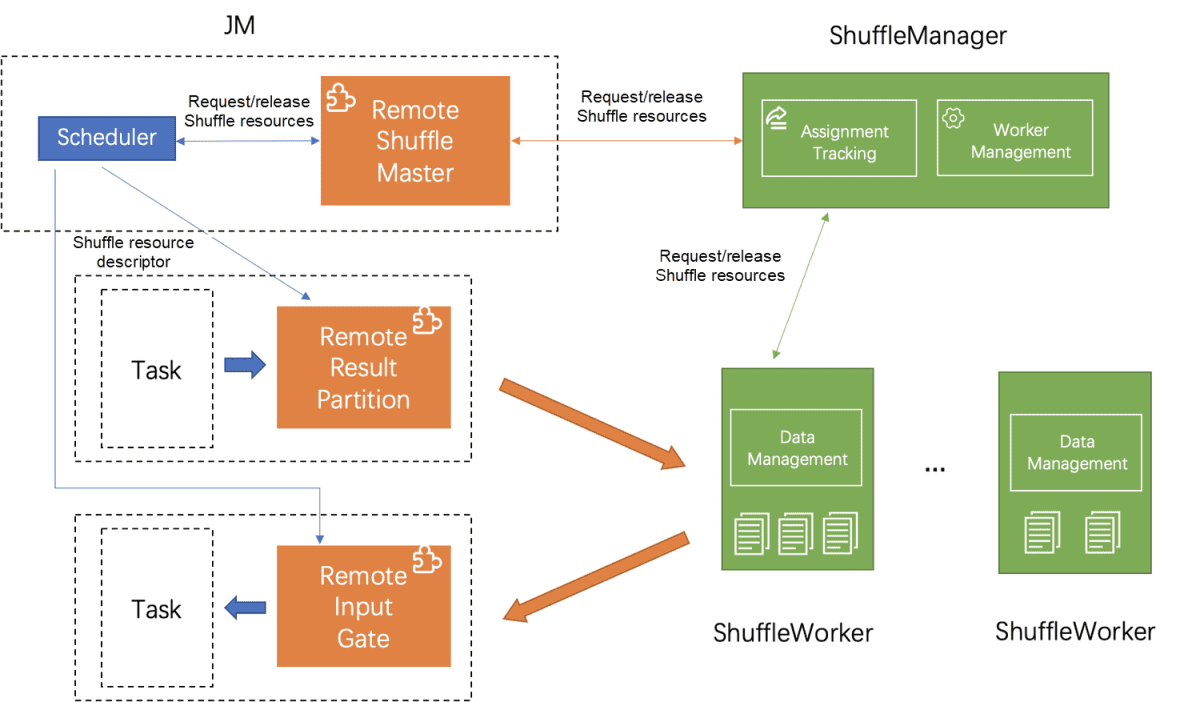
Когда запускается задача вышестоящего потока, планировщик Flink применяет ресурсы из ShuffleManager через подключаемый модуль RemoteShuffleMaster. ShuffleManager выбирает соответствующий ShuffleWorker для предоставления услуг на основе типа набора данных и нагрузки рабочих процессов. Когда планировщик получает дескриптор ресурса Shuffle, он переносит его при запуске задачи вышестоящего потока, которая отправляет данные в соответствующий ShuffleWorker для постоянного хранения в соответствии с адресом в дескрипторе. Соответственно, когда запускается задача нижестоящего потока, она считывает данные из ShuffleWorker в соответствии с адресом, записанным в дескрипторе.
Как работает RSS
Flink RSS отслеживает ShuffleWorker и ShuffleMaster с помощью тактового сигнала (heartbeat) и других механизмов. Он поддерживает согласованность состояния всего кластера, удаляя и синхронизируя состояние набора данных при возникновении исключений, таких как тайм-аут heartbeat-сигнала и сбой ввода-вывода.
Удаленная перетасовка данных включает чтение и запись. На этапе записи данных выходные данные задачи вычислений восходящего потока записываются на удаленный ShuffleWorker. На этапе чтения данных задача вычислений нисходящего потока считывает и обрабатывает выходные данные задач вычислений восходящего потока с удаленного ShuffleWorker. Протокол перетасовки данных определяет тип данных, гранулярность, ограничения и процедуру в этом процессе.
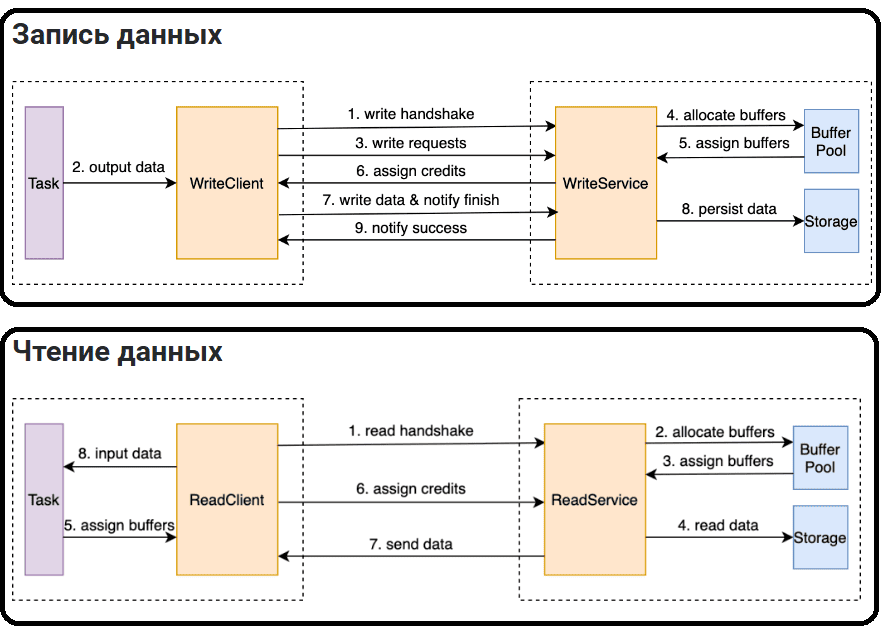
В процессе чтения и записи данных используются множественные методы оптимизации: сжатие данных, управление трафиком, сокращение копирования данных и управляемое использование памяти.
Файловый ввод-вывод является узким местом для записи shuffle-данных, особенно на жестких дисках. Для его оптимизации используется сжатие данных, а также небольшие файлы или небольшие блоки данных. Это обеспечивает последовательное чтение и запись файлов, сокращая случайные чтения и записи. После того, как выходные данные вычислительной задачи заполняют буфер памяти, они сортируются и выгружаются в файл. Данные добавляются в тот же файл, чтобы избежать создания нескольких файлов. Добавляется планирование запросов на чтение данных, и данные считываются последовательно в порядке смещения файла для выполнения запроса на чтение.
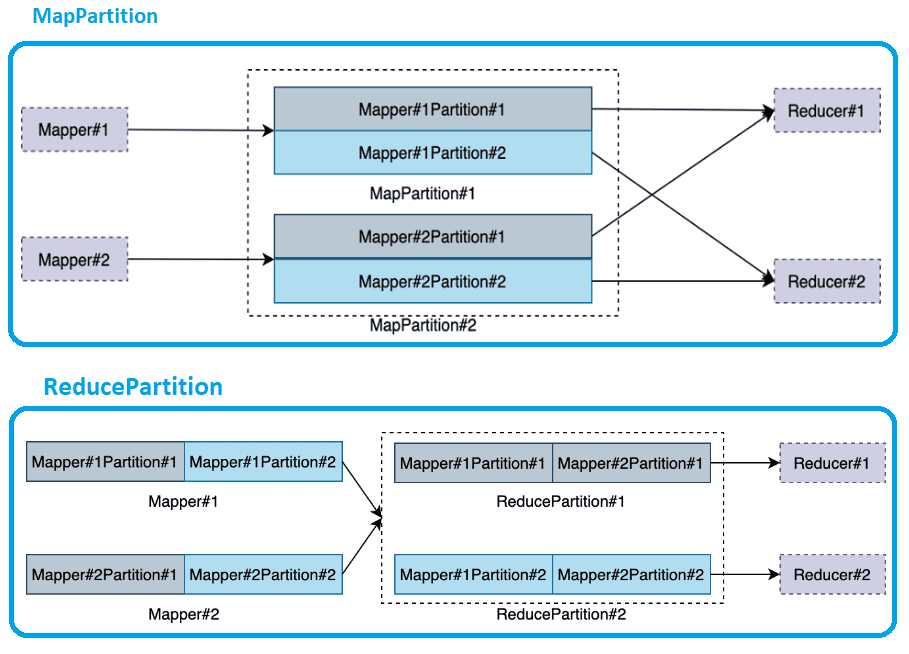
Абстракция Flink Remote Shuffle не отвергает никакую стратегию оптимизации. RSS можно рассматривать как промежуточную службу хранения данных с поддержкой Map-Reduce. Базовой единицей хранения данных является раздел данных (DataPartition), который имеет два типа: MapPartition и ReducePartition. Данные в MapPartition генерируются вычислительной задачей восходящего потока и могут потребляться несколькими вычислительными задачами нисходящего потока. Данные в ReducePartition генерируются объединенными выходами нескольких вычислительных задач восходящего потока. Они потребляются одной вычислительной задачей нисходящего потока.
Подводя итог описанию RSS в Apache Flink, еще раз подчеркнем, что эта служба позволяет создавать более масштабируемые и надежные потоковые приложения, которые могут эффективно обрабатывать большие объемы данных в реальном времени. Вместо того, чтобы хранить shuffle-данные на том же узле, где выполняется задача, Remote Shuffle Service сохраняет их в отдельном удаленном хранилище, освобождая локальные ресурсы узлов для выполнения других задач. Данные, необходимые для передачи между задачами, буферизуются и передаются через сеть с учетом оптимальной нагрузки, сокращая задержки и увеличивая пропускную способность. Поскольку shuffle-данные хранятся удаленно, Flink может более эффективно управлять оперативной памятью и ресурсами процессора, что особенно важно для длительных потоковых приложений.
Освойте возможности Apache Flink для пакетной и потоковой аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.alibabacloud.com/blog/flink-remote-shuffle-open-source-shuffle-service-for-cloud-native-and-unified-batch-and-stream-processing_598645
- https://www.alibabacloud.com/blog/introduction-to-unified-batch-and-stream-processing-of-apache-flink_601407?spm=a2c65.11461478.0.0.23355355JyUt3m
- https://github.com/flink-extended/flink-remote-shuffle

