 647
647 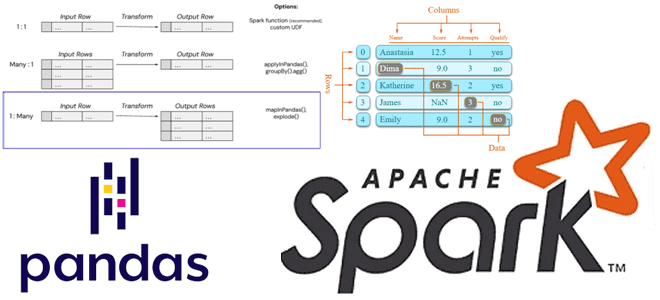
Содержание
Как применить пользовательскую функцию Python к объектам pandas в распределенной среде Apache Spark. Варианты использования Pandas UDF, applyInPandas() и mapInPandas() на практических примерах.
Разница между Pandas UDF, applyInPandas и mapInPandas в Apache Spark
Недавно я показывала пример сравнения быстродействия метода applyInPandas() с функцией apply() библиотеки pandas. Однако, помимо applyInPandas() в версии 3.0 появился еще метод mapInPandas(), который позволяет эффективно выполнять произвольные действия с каждой строкой датафрейма Spark. Он также применяет пользовательские функции Python к датафрейму и возвращает более одной строки.
На первый взгляд может показаться, что функции pandas, applyInPandas() и mapInPandas() очень похожи. Каждый из этих методов позволяет применять пользовательские функции Python к стандартным объектам pandas (датафреймы и индексируемые одномерные массивы, т.е. Series). Выбор между тремя подходами во многом зависит от ввода и вывода пользовательской функции. Если ожидается одна выходная строка для каждой входной строки, можно использовать pandas UDF. Для агрегатной обработки входных данных в какой-то определенной группировке подойдет applyInPandas(). Когда надо получить много выходных строк для каждой входной строки, с этим отлично справится mapInPandas().
| Вход | Выход | Метод |
| Один ряд | Один ряд | Pandas UDF |
| Много рядов | Один ряд | applyInPandas |
| Один ряд | Много рядов | mapInPandas |
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
16 марта, 2026
Продолжительность
16 ак.часов
Стоимость обучения
48 000
Пример использования mapInPandas
Рассмотрим работу mapInPandas(). В качестве примера возьмем датфрейм Spark из прошлой статьи, сгенерированный следующим образом:
# Установка необходимых библиотек
!pip install pyspark
!pip install faker
# Импорт необходимых модулей из pyspark
import pyspark
from pyspark.sql import SparkSession
import random
import pandas as pd
from pyspark.sql.functions import rand
from datetime import datetime, timedelta #для работы с датами и временем
import numpy as np
import time
# Импорт модуля faker
from faker import Faker
from faker.providers.address.ru_RU import Provider
# Импорт модуля faker
from faker import Faker
from faker.providers.address.ru_RU import Provider
# Создание объекта SparkSession
spark = SparkSession.builder.appName("GenerateDataFrame").getOrCreate()
# Создание объекта Faker с локализацией для России
fake = Faker('ru_RU')
# Виды событий
events = ['click', 'download', 'scroll', 'submit']
# Задаем стартовую и конечную даты
start_date = pd.Timestamp(year=2020, month=1, day=1)
end_date = pd.Timestamp.now()
# Генерация случайной даты в заданном диапазоне
def random_date(start_date, end_date):
delta = (end_date - start_date).days
random_days = np.random.randint(0, delta + 1)
return (start_date + timedelta(days=random_days)).date()
# Генерация датафрейма
def generate_initial_df(num_users, num_events_per_user):
data = []
for _ in range(num_users):
user_email = fake.free_email()
for _ in range(num_events_per_user):
event = random.choice(events)
event_date = random_date(start_date, end_date)
data.append((user_email, event, event_date))
# Создание Spark DataFrame
columns = ['user', 'event', 'event_date']
df = spark.createDataFrame(data, columns)
return df
# Количество пользователей и событий на пользователя
num_users = 100
num_events_per_user = 5000
# Генерация датафрейма
df = generate_initial_df(num_users, num_events_per_user)
df.show()
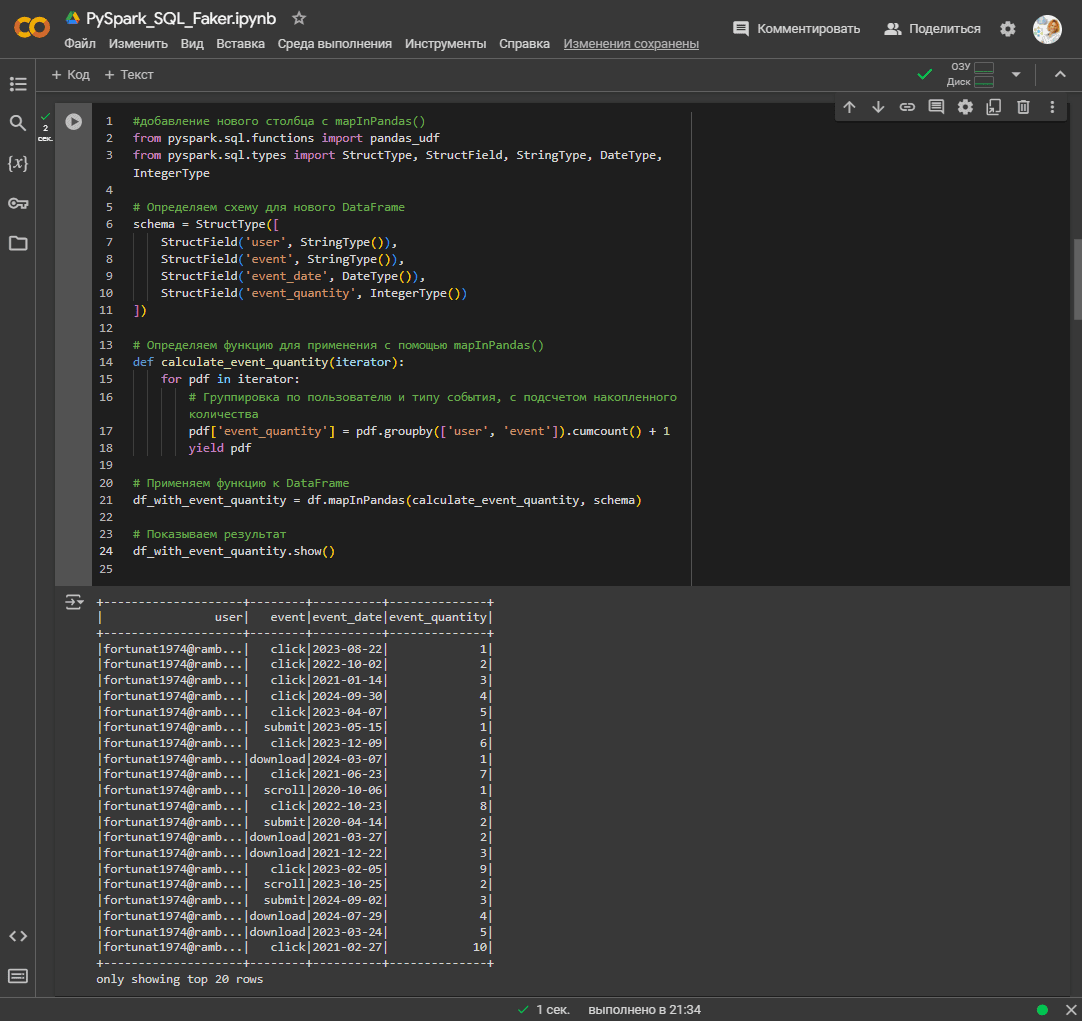
Функция mapInPandas() в PySpark позволяет применять произвольную функцию на уровне строк с использованием датафрейма Pandas. Это полезно для операций, которые проще или удобнее реализовать в pandas, и которые не могут быть выполнены средствами самого Spark. Например, надо добавить в датафрейм новый столбец, который для каждого пользователя и типа события подсчитывает их сумму. Для этого можно использовать mapInPandas():
#добавление нового столбца с mapInPandas()
from pyspark.sql.functions import pandas_udf
from pyspark.sql.types import StructType, StructField, StringType, DateType, IntegerType
# Определяем схему для нового DataFrame
schema = StructType([
StructField('user', StringType()),
StructField('event', StringType()),
StructField('event_date', DateType()),
StructField('event_quantity', IntegerType())
])
# Определяем функцию для применения с помощью mapInPandas()
def calculate_event_quantity(iterator):
for pdf in iterator:
# Группировка по пользователю и типу события, с подсчетом накопленного количества
pdf['event_quantity'] = pdf.groupby(['user', 'event']).cumcount() + 1
yield pdf
# Применяем функцию к DataFrame
df_with_event_quantity = df.mapInPandas(calculate_event_quantity, schema)
# Показываем результат
df_with_event_quantity.show()
Этот код добавляет новый столбец в датафрейм с использованием функции mapInPandas() в Apache Spark. Поскольку схема исходного датафрейма меняется, надо определить новую схему с учетом добавленных столбцов. Функция calculate_event_quantity() применяется к каждой группе данных из исходного датафрейма. Она принимает итератор iterator, который содержит группы данных в виде датафреймов pandas. Данные группируются по пользователям и типам событий, количество которых итеративно увеличивается с помощью метода накопления суммы cumcount(). Метод mapInPandas() применяется к исходному датафрейму df, применяя функцию calculate_event_quantity и новую данных schema. Результат сохраняется в новом датафрейме df_with_event_quantity и выводится с помощью метода show().
Таким образом, код добавляет столбец, в котором для каждого пользователя и типа события подсчитывается накопительное количество таких событий. Функция mapInPandas() возвращает много строк для каждой входной строки, то есть, по сравнению с applyInPandas(), она работает наоборот. В заключение перечислим достоинства и недостатки функции mapInPandas().
Эта функция позволяет использовать мощные возможности и удобства популярной библиотеки pandas для обработки данных в Spark. Она может работать быстрее, чем использование чисто Spark API для сложных вычислений или манипуляций с группами данных.
Однако, поскольку pandas загружает данные в память, это может привести к проблемам с производительностью, особенно при работе с большими наборами данных. Поэтому возникают ограничения на размер данных, с которым можно эффективно работать, по сравнению с нативным Spark API. Кроме того, передача данных между Spark и pandas добавляет накладных расходов на сериализацию и десериализацию данных. Таким образом, mapInPandas()подходит для случаев, когда нужно быстро применить сложную логику на уровне pandas к данным, но важно учитывать ограничения и потенциальные проблемы с производительностью и памятью.
Узнайте больше про использование Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://community.databricks.com/t5/technical-blog/understanding-pandas-udf-applyinpandas-and-mapinpandas/ba-p/75717
- https://www.databricks.com/blog/processing-uncommon-file-formats-scale-mapinpandas-and-delta-live-tables
- https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/api/pyspark.sql.DataFrame.mapInPandas/
- https://docs.databricks.com/en/udf/pandas/

