
Зачем включать ротацию лог-файлов потоковых приложений Apache Spark, какие конфигурации помогут ее настроить и для чего сжимать файлы журналов в длительных заданиях. Чем полезна ротация лог-файлов Spark-приложений и как ее настроить Об общих принципах логирования системных событий в приложениях Apache Spark мы уже рассказывали здесь. В этой статье подробнее разберем...

Чем объектное хранилище данных отличается от классической файловой системы POSIX, как это влияет на разработку Spark-приложений, почему операция переименования снижает производительность облачных вычислений и что поможет ее избежать. Еще раз об отличиях объектных и файловых хранилищ и как это влияет на приложения Spark Будучи компонентом экосистемы Apache Hadoop, фреймворк Spark...
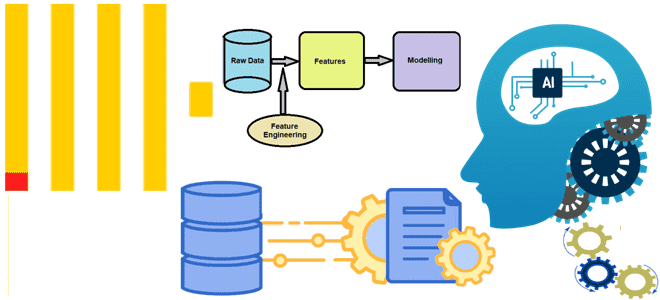
Что такое хранилище признаков, зачем это нужно в машинном обучении, каковы его главные компоненты и как использовать ClickHouse в качестве Feature Store для ML-задач. Хранилище признаков для машинного обучения: архитектура и принципы работы Feature Store Будучи колоночной базой данных, ClickHouse отлично подходит на роль хранилища фичей (Feature Store) для задач...

24 сентября вышел очередной релиз Apache Spark. Он не содержит новых фичей, но зато в нем есть несколько полезных оптимизаций и исправлений безопасности. Читайте далее о самом главном из них, связанном с утечкой токена делегирования Hadoop. Зачем нужны токены делегирования Hadoop в Spark и как они работают В выпуске Apache...
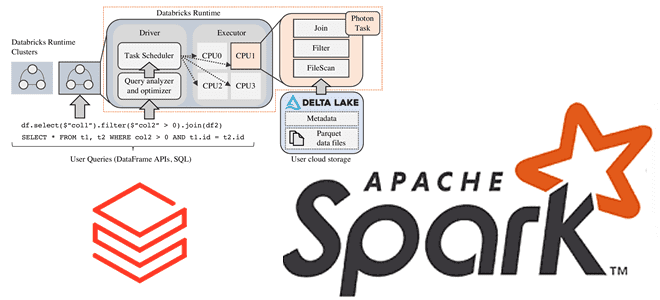
Зачем Databricks выпустила новый движок выполнения запросов Spark SQL для ML-приложений, как он работает и где его настроить: возможности и ограничения Photon Engine. Преимущества Photon Engine для ML-нагрузок Spark-приложений Чтобы сделать Apache Apark еще быстрее, разработчики Databricks выпустили новый движок выполнения запросов - Photon Engine. Это высокопроизводительный механизм запросов, который...

Зачем хранить данные в Apache Kafka постоянно и как это сделать: варианты использования и пример архитектурного решения Infinite Storage от Confluent Cloud, который лег в основу Tiered Storage. Infinite Storage от Confluent Cloud для бесконечного хранения данных в Apache Kafka Изначально Apache Kafka, как и любой другой брокер сообщений, не...

Разработчики ClickHouse с завидной регулярностью радуют новыми релизами. Не прошло и месяца, как опубликован очередной выпуск этой колоночной СУБД, версия 24.8 LTS от 20 августа 2024. О ее главных новинках читайте далее. Несовместимые изменения Начнем с самых важных и несовместимых изменений. В релизе ClickHouse 24.8 LTS для clickhouse-client и clickhouse-local...
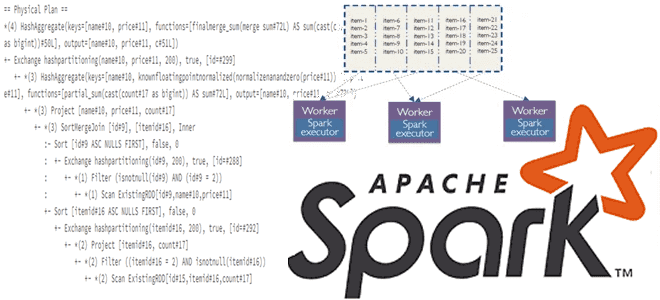
Что такое Dynamic Partition Pruning в Spark SQL, как работает этот метод оптимизации пакетных запросов, зачем его использовать в задачах аналитики больших данных, и каким образом повысить эффективность его практического применения. Что такое Dynamic Partition Pruning и зачем это нужно в Spark SQL Параллельная обработка данных в Apache Spark обеспечивается...
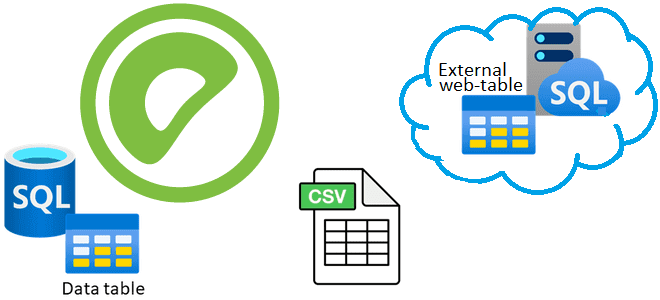
Что такое внешние веб-таблицы, зачем они нужны, чем отличаются от обычных external tables и как создать такую таблицу в Greenplum на основе команд и на основе URL. Зачем нужны внешние веб-таблицы в Greenplum О том, что в Greenplum есть внешние (external) и сторонние (foreign) таблицы, которые обеспечивают доступ к данным,...

2 августа 2024 года вышел свежий релиз Apache Flink. Знакомимся с главными новинками выпуска 1.20 для упрощения потоковой обработки данных в мощных управляемых конвейерах: новые материализованные таблицы, единый механизм слияния файлов для контрольных точек, улучшения DataStream API и пакетных операций. Улучшения Flink SQL Начнем с новинок Flink SQL, одной из...