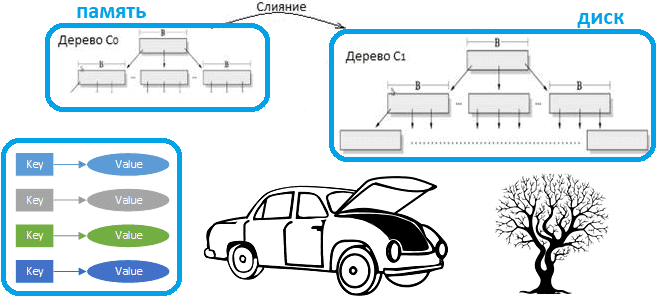
Что такое LSM-дерево и как эта структура данных, лежащая в основе многих NoSQL-баз с распределенным типом ключ-значение, позволяет им обеспечивать высокую скорость записи и чтения. Смотрим на примере Apache HBase. Зачем нужны LSM-деревья Типичная СУБД состоит из нескольких компонентов, каждый из которых отвечает за обработку различных аспектов хранения, поиска и...

Как Apache Spark организует параллельные вычисления, зачем нужны аккумуляторы и каким образом они помогают организовать мониторинг качества данных в аналитических конвейерах их обработки. Смотрим с точки зрения дата-инженера и разработчика распределенных приложений. Как Apache Spark распараллеливает обработку данных Параллельная обработка — это метод вычислений, при котором работает более одного ЦП...

Продолжая разбираться с новинками Greenplum версии 7, выпущенной в середине декабря 2022 года, сегодня рассмотрим, как теперь работает SQL-команда с DML-запросов изменения таблиц ALTER TABLE. Как динамически менять структуру и характеристики таблицы даже тех, что предназначены только для добавления с новыми методами доступа. Модели таблиц в Greenplum: Append Only и...

Хотя Apache Pig сегодня не самый актуальный инструмент для аналитики больших данных в экосистеме Hadoop, дата-инженеру полезно знать его основные принципы работы и ключевые отличия от Hive. Также рассмотрим, чем Hive отличается от Pig в качестве средства SQL-on-Hadoop. Что такое Apache Pig Apache Pig – это высокоуровневый процедурный язык для...
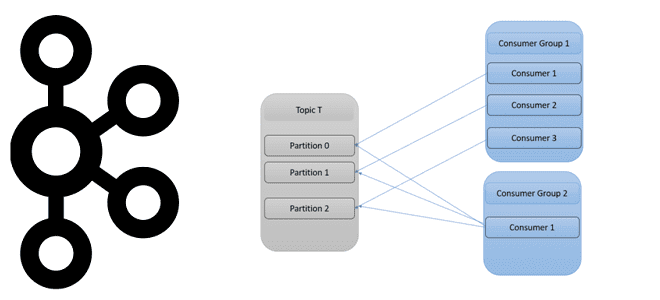
Как количество разделов топика Apache Kafka влияет на потребителей и продюсеров, зачем нужны группы потребителей и как этот механизм реализует идею микросервисной архитектуры Big Data систем. Как работают группы потребителей в Apache Kafka Будучи распределенной платформой потоковой передачи событий, Apache Kafka выполняет роль средства обмена сообщениями между приложениями-продюсерами и приложениями-потребителями...

Как оптимизатор Calcite в Apache Flink переводит SQL-команды в задания потоковой и пакетной обработки и какие приемы могут ускорить их выполнение. Разбираемся, чем полезны интерфейсы пользовательских коннекторов источника и подсказки запросов. Flink SQL в пакетной и потоковой обработке данных Apache Flink позволяет разрабатывать распределенные приложения потоковой обработки больших данных, предоставляя...

В рамках продвижения нашего нового курса по графовой аналитики больших данных, сегодня рассмотрим, как создать граф социальных связей в веб-консоли Neo4j и сделать запросы к нему на Cypher - внутреннем SQL-подобном языке этой NoSQL-СУБД. Как построить граф социальных связей в Neo4j Возьмем в качестве примера набор деловых и личных взаимоотношений...
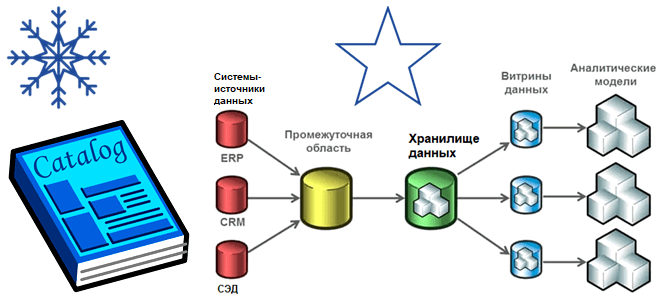
Хотя современная аналитика больших данных чаще базируется на Data Lake, Data Mesh, Delta Lake и DeltaLakeHouse, многие компании до сих пор активно используют классические витрины и хранилища. Разбираем особенности этих архитектур, а также оцениваем их применимость к текущим потребностям бизнеса. Витрины и хранилища данных Витрина данных (Data Mart) предоставляет информацию...

В этой статье для обучения дата-инженеров и разработчиков распределенных приложений, сегодня разберем опыт ИТ-компании Similarweb, где Apache Spark на платформе Databricks вместо AWS Athena ускорил пакетную обработку данных в 50 раз. Также рассмотрим приемы повышения производительности ODBC-драйвера Databricks для улучшенного взаимодействия с озерами данных. Постановка задачи и ограничения POC для...

Сегодня рассмотрим, что такое воронки, шаблоны, порты и группы процессоров в Apache NiFi и как эти элементы помогают дата-инженеру эффективно проектировать потоковые конвейеры обработки данных. Из чего состоит конвейер обработки данных в Apache NiFi: обзор элементов Благодаря веб-GUI Apache NiFi позволяет дата-инженеру быстро создавать конвейеры потоковой обработки данных, просто располагая...