
Сегодня заглянем под капот Apache NiFi, чтобы понять, какие данные хранит этот потоковый ETL-маршрутизатор, зачем и где. Репозитории Apache NiFi для администратора, дата-инженера и проектировщика конвейеров обработки данных: как они устроены и какие практики улучшают их работу. Репозитории Apache NiFi: что это такое и зачем они нужны В Apache NiFi...

Риски и возможности отечественного рынка труда с точки зрения профессиональной сертификации по технологиям больших данных. Как и зачем Школа Больших Данных разрабатывает профессиональную вендор-независимую сертификацию по продуктам и технологиям Big Data для еще лучшей подготовки и оценки ИТ-специалистов на российском рынке, опустевшем после ухода западных вендоров. Как изменился рынок профессиональных...

Зачем корпорации Confluent, которая продвигает Apache Kafka, понадобился Flink-стартап, чего ожидать от очередного слияния поглощения крупным игроком более мелкого предприятия, и какую пользу это принесет экосистеме потоковой передачи событий. Что Immerok и зачем это Confluent Год только начался, а в мире Big Data уже появились интересные новости. 6 января в...
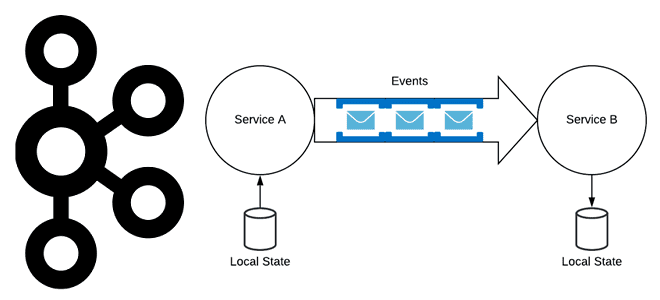
Хотя Apache Kafka часто используется в качестве шины обмена данными в микросервисной архитектуре, о чем мы писали здесь, не стоит воспринимать эту платформу как хранилище событий. В чем разница между событием и сообщением, а также другие тонкости построения микросервисной архитектуры, управляемой событиями. События vs сообщения Событие — это сообщение программной...

Использование СУБД вместо очереди сообщений считается антипаттерном, однако, команда разработки облачной системы организации конвейеров обработки данных Dagster Cloud выбрала PostgreSQL вместо Apache Kafka для регистрации событий. Разбираемся, почему плохой шаблон принес хорошие результаты и что нужно учитывать при выборе технологии. Почему не стоит использовать СУБД вместо очереди сообщений Dagster Cloud...

Специально для обучения дата-инженеров и разработчиков распределенных программ, сегодня рассмотрим подходы к организации модульного тестирования Spark-приложений через классы тестовых данных. Зачем и как генерировать эти классы, где их хранить и при чем здесь система автоматической сборки приложений Gradle. Сборка и тестирование Spark-приложений Модульное тестирование лежит в основе проверки работоспособности программного...

Мы уже рассказывали, что Apache Flink использует Calcite для оптимизации SQL-запросов. Продолжая разбирать эту тему, важную для обучения разработчиков Flink-приложений и дата-инженеров, сегодня рассмотрим, как отследить происхождение отношения на уровне поля, используя методы класса RelMetadataQuery в Calcite. Что такое Apache Calcite и при чем здесь Flink SQL Напомним, Apache Flink...
Недавно мы писали про сравнения технологий потоковой аналитики больших данных и аналитических баз данных реального времени на примере сравнения ksqlDB и Rockset. Продолжая этот разговор про архитектуру данных и приложений, сегодня рассмотрим сходства и отличия потоковых баз данных со stateful-приложениями обработки событий в реальном времени. 2 технологии потоковой обработки: stateful-приложения...
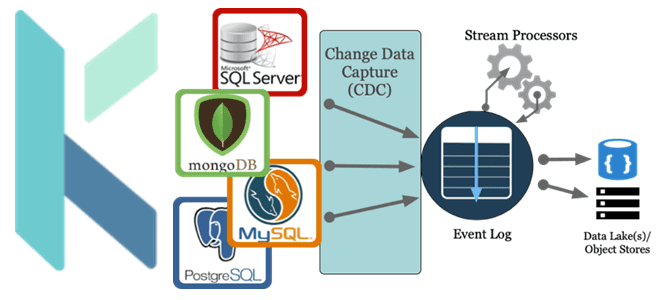
Как реализовать CDC-сценарий, используя платформу оркестрации Kestra вместо Debezium с Kafka Connect для планирования и управления конвейером обработки данных. За счет чего Kestra работает эффективнее Debezium с коннекторами Kafka Connect и при чем здесь Apache AirFlow с NiFi. Что не так с реализацией CDC на Debezium с Kafka Connect Мы...
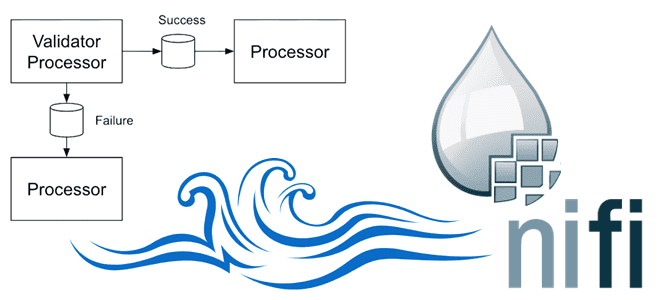
Зачем нужны средства записи и чтения в процессорах Apache NiFi и как они работают: разбираемся на примере QueryRecord, PartitionRecord и RouteText. Сходства и отличия этих процессоров, а также тонкости их использования в задачах дата-инженерии. Процессор QueryRecord в Apache NiFi Напомним, в потоковом ETL-маршрутизаторе Apache NiFi процессоры используются для прослушивания входящих...