 1462
1462 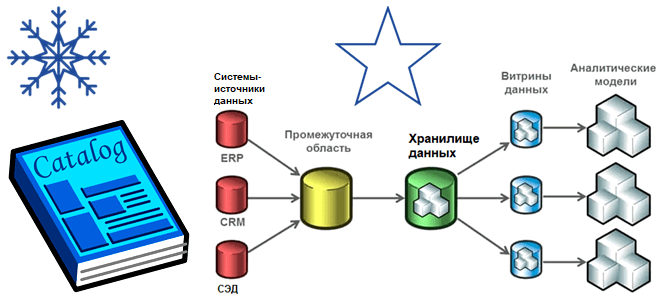
Хотя современная аналитика больших данных чаще базируется на Data Lake, Data Mesh, Delta Lake и DeltaLakeHouse, многие компании до сих пор активно используют классические витрины и хранилища. Разбираем особенности этих архитектур, а также оцениваем их применимость к текущим потребностям бизнеса.
Витрины и хранилища данных
Витрина данных (Data Mart) предоставляет информацию из корпоративного хранилища (DWH) по конкретной теме или доменной области, например, продажи, финансы или маркетинг. Из-за своей сфокусированности витрины получают данные из меньшего количества источников, чем хранилища. Data Mart также может включать содержимое из внешних источников, помимо DWH.
Если рассматривать витрину данных как часть хранилищ, возникает вопрос об их актуальности с учетом тренда на облачные технологии. Современные хранилища данных работают по принципу SaaS, например, AWS Redshift, Google BigQuery, Snowflake и пр. включают функции витрины и устраняют необходимость создания отдельного Data Mart.
Впрочем, даже при использовании облачных решений, возникает необходимость разработки модели корпоративных данных (Enterprise Data Model, EDM) как интегрированного представления данных, производимых и потребляемых во всей организации, независимого от систем и приложений. Эта модель данных состоит из 2 слоев: исходного и интегрированного.
Модель данных исходного слоя – это уровень, куда вносятся данные из всех источников независимо от принадлежности к домену. Это модель очень похожа на реализацию в базе данных исходного приложения с небольшими отличиями, т.к. DWH может быть реализовано не в СУБД, а в распределенных системах хранения типа Hadoop HDFS, AWS S3 и пр. Если к хранилищам данных будет применяться логика SCD, могут не поддерживаться ограничения первичного ключа или внешнего ключа, а для установления уникальности и взаимосвязи между таблицами будет использоваться суррогатный ключ.
Модель данных уровня интеграции содержит данные с наименьшей детализацией, которые объединяются из нескольких источников в унифицированные и согласованные наборы данных. Это устраняет неоднозначность в отношении одних и тех же данных, распределенных по разным приложениям и организационным структурам, таким как клиенты, сотрудники, продукты и пр. Поэтому уровень интеграции DWH часто называют золотым источником данных на предприятии.
Технически такое хранилище может быть реализовано с помощью MPP-СУБД Greenplum и ее отечественного дистрибутива Arenadata DB.
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Витрина данных состоит из наборов, которые являются подмножеством DWH путем получения данных непосредственно из исходных систем или через обогащение их данными из хранилища. Будучи доменно-ориентированной, витрина данных обычно создается для решения конкретной проблемы, характерной для ограниченного количества потребителей или сценариев использования. При построении витрин используются приемы моделирования многомерных данных, реализуя следующие понятия:
- измерения — набор информации, который содержит данные по одному или нескольким бизнес-измерениям;
- факты — набор измерений, метрик, транзакций и пр. из различных бизнес-процессов;
- атрибуты или показатели — элементы таблицы измерений.
Таблицы фактов нужны для хранения бизнес-показателей или транзакций, а таблицы измерений хранят измерения бизнеса и устанавливают контекст для фактов. В моделировании многомерных данных выделяют следующие шаги:
- идентификация бизнес-процесса – определение потребности создания витрины данных, чтобы понять, решаемую бизнес-проблему, а также выявить необходимые измерения и наборы данных;
- идентификация гранулярности, чтобы понять какая нормализация может быть достигнута в данных;
- определение измерений, которые являются ключевыми компонентами процесса моделирования многомерных данных. Они содержат подробную информацию об объектах домена.
- определение фактов, т.е. показателей и операции, которые должны быть связаны с соответствующими измерениями;
После этого выполняется построение схемы данных для материализации идентифицированных измерений и фактов в таблицы. Обычно при этом используется схемы звезды или снежинки, о которых мы писали здесь. В звездообразной схеме таблица фактов окружена таблицами измерений, которые не полностью нормализованы и содержат набор атрибутов, описывающих каждое измерение.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
12 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Схема снежинки является расширением звездообразной схемы и включает в себя больше измерений. В отличие от схемы звезды, в снежинке измерения полностью нормализованы и разделены на дополнительные таблицы. Эта схема использует меньше места на диске благодаря нормализации, а также в нее легко добавить новые измерения.
Эти приемы моделирования многомерных данных являются базовой основой для создания хранилищ и витрин данных. Однако, это является интересом ИТ-архитектора и дата-инженера, а пользователям важно знать, какие данные есть в DWH. Для этого применяются каталоги данных, которые мы рассмотрим далее.
Каталоги данных в DWH
Каталог данных — это набор метаданных вместе с инструментами управления данными и средствами поиска, который помогает пользователям находить нужную информацию. Он предоставляет информацию для оценки пригодности данных в использовании, обеспечивая классификацию информации и быстрый доступ к ней. Каталог данных в DWH помогает искать нужные и просматривать все доступные наборы данных, а также оценивать и анализировать их.
Каталог данных позволяет понять представления данных, хранящихся в источниках данных, с технической и бизнесовой точек зрения. Автоматическое обнаружение наборов данных требуется не только для постоянного обнаружения новых наборов, но и для первоначального построения каталога. Кроме того, каталог данных позволяет узнать, кто является владельцем данных в DWH и кто отвечает за их отправку в хранилище.
Для этого каталог данных должен реализовывать следующие функции:
- представлять собой единый источник достоверной информации обо всех загруженных корпоративных данных;
- быть способным обнаруживать новые источники данных и следить за тем, как они повышают ценность бизнеса;
- вести мониторинг данных и обеспечивать помощь в создании линии их передачи;
- иметь элементы управления для обеспечения доступа и безопасности на основе ролей;
- отмечать проблемы с качеством данных;
- иметь возможность интеграции с внешними инструментами и технологиями;
- предоставлять доступ к данным для анализа и передачи к месту назначения.
Таким образом, каталог данных помогает повысить их эффективность, предоставляя полный контекст, повышая скорость поиска информации и ее надежность. Это позволяет бизнесу принимать прозрачные и комплексные решения, основанные на данных согласно data-driven управлению. Наличие каталога данных улучшает сотрудничество между техническими специалистами и бизнес-группами.
Чтобы реализовать эффективный каталог данных в DWH, следует учитывать, кто является его конечным пользователем, какой должна быть стратегия развертывания, каковы особенности рабочих процессов и сценариев использования корпоративных витрин и хранилищ. Сегодня на рынке есть набор готовых решений, которые можно применить для создания каталога данных в Data Warehouse. Самыми популярными из них считаются следующие:
- Aginity (coginiti) – имеет отличную экосистему и поддерживает SQL, каталогизирует все данные компании и математику для аналитических вычислений;
- Apache Atlas — предоставляет открытые возможности управления метаданными для создания каталога активов данных, классификации и управления ими, а также средства совместной работы;
- world — облачная платформа, которая сочетает наглядный GUI с мощным графом знаний для обеспечения расширенного обнаружения данных и управления ими;
- LinkedIn DataHub — платформа управления метаданными с открытым исходным кодом для современного стека данных, которая обеспечивает обнаружение данных, их наблюдаемость и федеративное управление;
- Alation — корпоративный каталог данных, который повышает производительность и точность аналитики, позволяя быстро находить, понимать и управлять нужными данными;
- Collibra – помогает унифицировать данные отдельных команд, людей, компаний и систем благодаря отличным возможностям каталогизации со настройками управления и конфиденциальности;
- каталог данных AWS Glue – постоянное хранилище технических метаданных от Amazon, управляемый сервис, который можно использовать для хранения, комментирования и обмена метаданными в облаке AWS;
- каталог данных Azure — полностью управляемая облачная служба, которая позволяет пользователям находить нужные им источники данных и анализировать их;
- каталог Google Dataplex —полностью управляемая, масштабируемая служба управления метаданными в рамках GCP.
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

