
Сегодня рассмотрим, что такое воронки, шаблоны, порты и группы процессоров в Apache NiFi и как эти элементы помогают дата-инженеру эффективно проектировать потоковые конвейеры обработки данных.
Из чего состоит конвейер обработки данных в Apache NiFi: обзор элементов
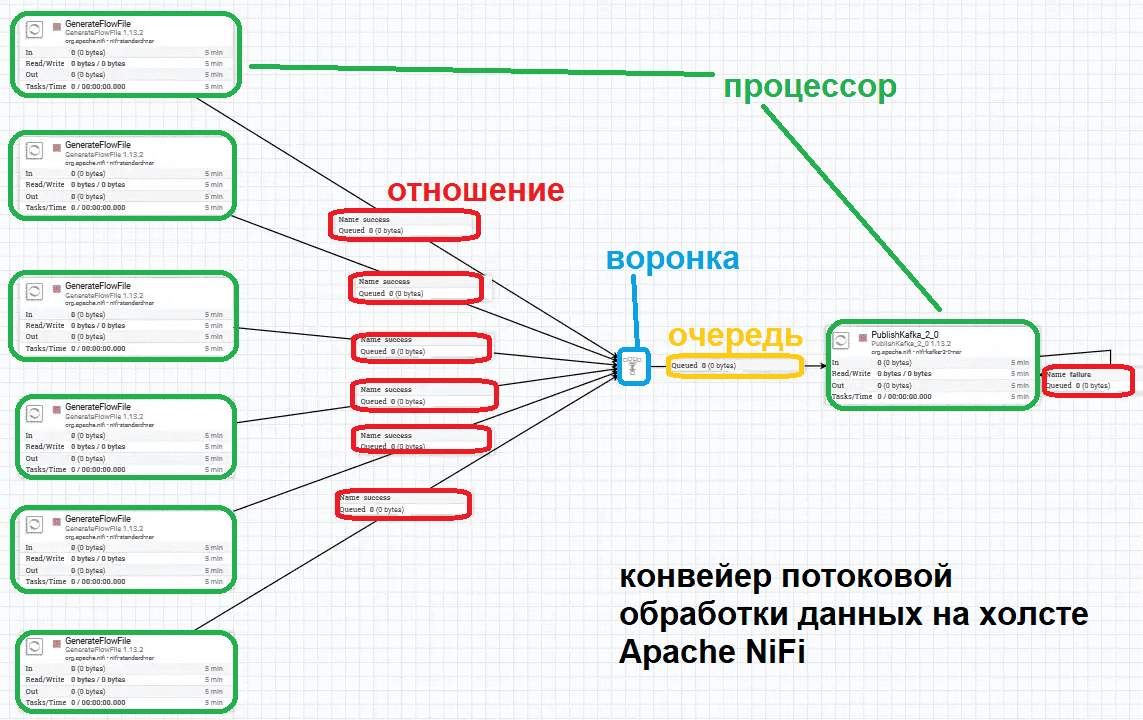
Благодаря веб-GUI Apache NiFi позволяет дата-инженеру быстро создавать конвейеры потоковой обработки данных, просто располагая элементы на холсте без погружения в дебри парадигмы программирования потоков данных. Помимо процессоров, которые непосредственно выполняют ETL-операции, Apache NiFi также предоставляет другие полезные элементы, такие как отношения, подключения, воронки и шаблоны.
Процессор (Processor) используется для прослушивания входящих данных, извлечения их из внешних источников и публикации в места назначения. Также эти обработчики позволяют маршрутизировать, преобразовывать или извлекать информацию из потоковых файлов. Дата-инженер может написать свой собственный процессор NiFi, используя наиболее распространенные паттерны проектирования, о которых мы рассказываем здесь.
Для каждого процессора определяются 0 или более отношений, которые указывают результат обработки потокового файла. Завершив обработку FlowFile, процессор направляет его в одно из отношений (Relationship). Затем диспетчер потока данных (DFM, DataFlowManager), пользователь NiFi, у которого есть разрешения на добавление, удаление и изменение компонентов потока данных, может связать каждое из этих отношений с другими компонентами, чтобы указать, куда потоковый файл должен идти дальше при каждом потенциальном результате обработки.
DFM создает автоматизированный поток данных, перетаскивая компоненты панели инструментов NiFi на холст, а затем соединяя их через соединения (connection). Каждое соединение состоит из одного или нескольких отношений. Для каждого соединения DFM может определить, какие для него использовать отношения, чтобы маршрутизировать данные по-разному в зависимости от результатов их обработки. Каждое соединение содержит очередь потоковых файлов. Когда потоковый файл передается определенному отношению, он добавляется в очередь, принадлежащую связанному соединению.
Воронка (funnel) используется для объединения данных из нескольких соединений. Это позволяет улучшить визуализацию конвейера обработки данных, когда на холсте расположено много подключений с одним и тем же пунктом назначения. Также воронка позволяет приоритизировать соединения с помощью FlowFile Prioritizers: данные из нескольких соединений могут быть направлены в одно. По сути, воронка просто отправляет потоковые файлы сразу после их получения, что полезно в случае нескольких процессоров, которые переходят к одному и тому же месту назначения.
Каждый из процессоров передает свои потоковые файлы в воронку, а затем в следующий процессор. Предположим, необходимо добавить общий атрибут ко всем из них. В отсутствии воронки придется последовательно заменять назначение всех этих очередей на UpdateAttribute. А с воронкой можно просто изменить ее пункт назначения.
DFM могут создавать очень большие и сложные потоки данных за счет использования процессоров, воронок и портов ввода/вывода. Эти элементы можно рассматривать как основные строительные блоки построения потокового конвейера обработки. Чтобы упростить их повторное использование, NiFi предлагает концепцию шаблона (template) как способа объединения этих основных компонентов в более крупные строительные блоки. После того, как поток данных создан, его части могут быть сформированы в шаблон. Затем дата-инженер может перетащить этот шаблон можно на холст или экспортировать его в виде XML-файла и поделиться с командой. Также можно импортировать внешние шаблоны в свой экземпляр NiFi, чтобы перетащить на холст и использовать.
Говоря про оптимизацию проектирования конвейеров обработки данных в Apache NiFi, следует упомянуть про группы процессов (Process Group). NiFi позволяет объединять несколько процессоров в группу, чтобы использовать ее на холсте. Пользовательский интерфейс NiFi позволяет DFM соединять несколько групп процессов в логический поток данных, а видеть и управлять всеми входящими в группу процессов элементами.
Потоки данных, созданные с использованием одной или нескольких групп процессов, нужно подключить к другим компонентам потока данных. Это делается с помощью портов (port). DFM может добавить любое количество входных и выходных портов в группу процессов и присвоить им соответствующие имена.
Подобно тому, как данные передаются в группу процессов и из нее, иногда необходимо передавать данные из одного экземпляра NiFi в другой. Хотя NiFi предоставляет множество различных механизмов для межсистемной передачи данных, самым простым способом сделать это является удаленная группа процессов (Remote Process Group).
Узнайте больше подробностей по администрированию и эксплуатации Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

