В этой статье для обучения дата-инженеров и разработчиков распределенных приложений, сегодня разберем опыт ИТ-компании Similarweb, где Apache Spark на платформе Databricks вместо AWS Athena ускорил пакетную обработку данных в 50 раз. Также рассмотрим приемы повышения производительности ODBC-драйвера Databricks для улучшенного взаимодействия с озерами данных.
Постановка задачи и ограничения POC для пакетной аналитики на основе AWS Athena
Британская ИТ-компания Similarweb предоставляет услуги веб-аналитики, глубокого анализа данных и бизнес-аналитики для международных корпораций. Одним из проектов компании был пакетный, ориентированный на клиента API настраиваемых отчетов. Один отчет мог содержать данные о разных доменах в 60 странах за последние 3 года, поддерживая 30 различных показателей. Такой отчет может занимать около 50 ГБ, а отсканированные наборы данных — около 10 ТБ. Чтобы проверить состоятельность концепции продукта, специалисты Similarweb спроектировали и создали быстрый Proof-Of-Concept (POC), использующий AWS Athena в качестве механизма создания отчетов и сохранения их в S3. Его было легко настроить из-за его бессерверной природы, а затраты были очень низкими: $5 за ТБ отсканированных данных с достаточной производительностью запросов малого и среднего размера.
Однако, бессерверная природа AWS Athena не позволяла настроить кластер нужным образом и устанавливала следующие ограничения продукта:
- выполнение только одного запроса одновременно — одновременное выполнение больших запросов блокировало AWS Athena и приводило к ошибке InternalFailure;
- отсутствие соединений между наборами данных — сканирование нескольких наборов данных более 1 ТБ также приводило к ошибке InternalFailure;
- кратковременные тайм-ауты — некоторые запросы были невозможны из-за ограничения сервиса AWS Athena на 30-минутное ожидание отклика, что не позволяло запрашивать множество доменов за 3 года исторических данных.
Поэтому после тестирования POC на базе AWS Athena потребовалось более масштабируемое решение. Чтобы найти его, аналитики Similarweb определили следующие требования к технологиям реализации продукта:
- обработка 50 запросов одновременно;
- среднее время ответа не более нескольких минут;
- возможность поддерживать длительные запросы, которые будут сканировать ТБ данных в нескольких наборах, что может занять более 30 минут;
- запросы с соединением нескольких наборов данных;
- отправка отчета через AWS S3;
- автомасштабирование — движок должен иметь возможность увеличивать и уменьшать масштаб в зависимости от использования.
В Similarweb уже использовались конвейеры обработки данных на основе приложений Apache Spark в Databricks. Поэтому именно эти технологии и были выбраны в качестве инструментов реализации решения, которое позволило добиться 50-кратного параллелизма, повышения производительности и быстрого времени отклика. Как это было сделано, рассмотрим далее.
Использование Apache Spark в Databricks
Напомним, вычислительная платформа Databricks основана на аналитическом движке с открытым исходным кодом для крупномасштабной распределенной обработки данных Apache Spark. Databricks специализируется на управлении выделенными кластерами Spark, предоставляя автоматическое масштабирование, планирование, мониторинг, историю, интерактивные среды ноутбуки с визуализацией данных и Databricks-Connect, который позволяет запускать программный код в удаленном кластере.
Чтобы эффективно сканировать данные, сперва следует решить, как они будут организованы, структурированы и сохранены. Similarweb использует сервисы AWS: S3 для хранения данных и Glue Catalog в качестве хранилища метаданных. При выборе стратегии сканирования данных надо учитывать следующие аспекты:
- формат файла – колоночные форматы типа Parquet лучше подходят для анализа данных благодаря оптимизации для агрегации, соединения, распределения и сложных стратегий сжатия. Поддержка Spark функции predicate pushdown в формате Parquet позволяет снизить объем сканируемых данных, ускорив процесс чтения.
- разделы Apache Hive и размеры файлов. Благодаря наличию хранилища метаданных Apache Hive часто используется в проектах Data Lake и отлично совмещается со Spark. Этот инструмент SQL-on-Hadoop включает механизм партиционирования, который применяется для повышения производительности запросов к большим таблицам, позволяя хранить данные в подкаталогах корневой таблицы. Выбор правильного ключа раздела зависит от согласованности размера файла: нужен столбец с низкой кардинальностью, а данные должны быть разделены равномерно, без перекосов. Раздел работает эффективно, если он включен в фильтры предполагаемого SQL-запроса.
- параллелизм — количество задач, которые задание обрабатывает одновременно. Каждая задача обрабатывает по одному разделу за раз, поэтому для настройки параллелизма следует определить конфигурации Spark-приложения: sql.files.maxPartitionBytes и spark.sql.shuffle.partitions.
Например, для набора данных с 60 ГБ по умолчанию количество разделов равно 200, т.е. в одном разделе должно храниться 300 МБ (60 ГБ/200 = 300 МБ). Но размер раздела по умолчанию составляет 128 МБ. Чтобы исправить это, можно изменить значение конфигурации spark.sql.shuffle.partitions на 467 (60 ГБ/128 МБ) или задать параметр spark.sql.files.maxPartitionBytes равным 300 МБ (60 ГБ/200).
Используя S3 в качестве хранилища данных вместе с вычислительной мощью Apache Spark, следует понимать распределенную природу этого фреймворка. В частности, запись всех выходных данных в один файл, если они занимают много ГБ, будет неэффективной из-за shuffle-операций и использования только одного рабочего процесса (worker). Вместо этого лучше разделить выходной файл на несколько разделов, чтобы распараллелить операции записи. Также рекомендуется писать данные сразу в нужные разделы без повторного их перераспределения. В этом поможет пример кластеризации разделов до выполнения вычислений.
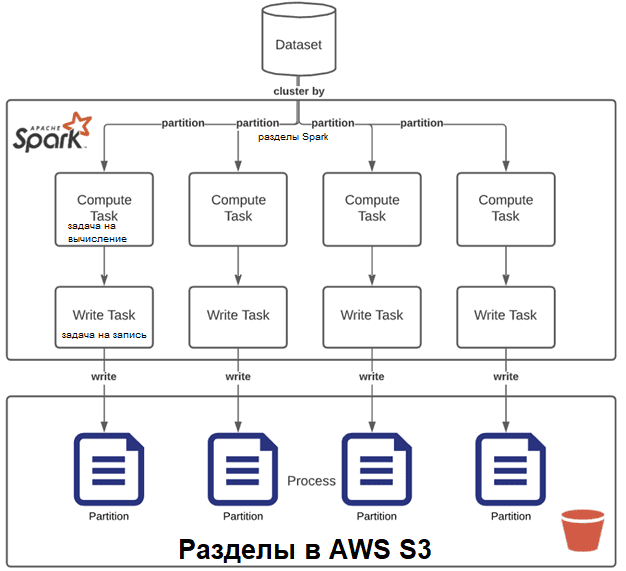
Уменьшить количество разделов в DataFrame поможет функция coalesce() вместо repartition(). Это позволит избежать полной перетасовки данных благодаря использованию существующих разделов, чтобы свести к минимуму объем перераспределяемых данных, о чем мы писали здесь.
Кластерная стратегия также оказывает большое влияние на время отклика, параллелизм и стоимость выполнения операций. Слишком большое количество узлов будет дорого стоит, а слишком малое – вызовет медленное время отклика и низкий уровень параллелизма. Неправильная конфигурация может привести к низкой загрузке. Для реализации требований Similarweb рассматривались следующие кластерные стратегии:
- разделить выполнение каждого задания, что упрощает настройку масштабирования и параллелизма при прогнозируемых рабочих нагрузках. Дополнительным преимуществом являются низкие затраты: оплата идет только за использование. Однако, эта стратегия может стать дорогостоящей, поскольку каждое задание будет создавать новый кластер. Впрочем, функция пулов Databricks дополняет эту стратегию и позволяет повторно использовать ресурсы из отключенных кластеров для экономии времени.
- стратегия долгосрочного кластера, когда драйвер всегда доступен для обработки новых заданий в режиме реального времени. Функция автоматического масштабирования Databricks оптимизирует количество worker’ов в соответствии с текущим объемом заданий, который необходимо выполнить. По затратам получается, что кластер стоит меньше, когда сервис не используется. Для Databricks эта стратегия полезна до определенного масштаба, поскольку максимальное количество узлов составляет 500. При этой стратегии придется управлять несколькими долгоживущими кластерами в некотором масштабе, что мы рассмотрим далее.
В случае долгоживущих кластеров не рекомендуется устанавливать свой узел драйвера в качестве спотового экземпляра: как только спот будет изменен, весь кластер выйдет из строя. Драйверы всегда должны быть экземплярами по требованию. Также следует держать несколько worker’ов по запросу, что выходит дороже, но дает стабильность даже при проблемах с облачными провайдерами. Минимальное количество worker’ов определяет, насколько быстро кластер начнет работать над новыми заданиями, а максимальное задает максимальное количество одновременных заданий, которые кластер будет поддерживать в часы пик.
Обеспечить эффективное обслуживание нескольких пользователей поможет функция Fair Scheduler Pools Spark, которая позволяет группировать задания в пулы и устанавливать разные параметры планирования для каждого из них. Это гарантирует, что ни одно задание не останется без worker’а, и при правильной настройке может обеспечить более стабильное время отклика. Далее рассмотрим, как повысить эффективность использования ODBC-драйвера Databricks, взаимодействуя с таблицами озера данных.
Повышение производительности драйвера Databricks ODBC
Databricks, как и другие платформы распределенной обработки больших данных, сокращает время отклика на запросы, но технологии взаимодействия клиентских приложений с ними по-прежнему используют стандарты более чем 25-летней давности, такие как JDBC или ODBC. Они изначально были разработаны без учета распределенных систем, хранилища объектов или колоночных форматов хранения данных. Поэтому JDBC и ODBC изначально требуют дорогостоящих процессов преобразования/сериализации данных путем экспорта из колоночных форматов в формат строк JDBC/ODBC, а затем обратного преобразования в формат клиента.
Исправить это позволяют новые стандартные интерфейсы, таких как Apache Arrow Flight SQL, а также изменения существующих технологий. Например, Databricks вокруг интерфейса ODBC, предоставляемого сервером Spark Thrift, ускоряет извлечение больших объемов данных.
Для Databricks ODBC важна конфигурация драйвера. Например, при работе с длинными столбцами типа STRING, обязательно нужно следить за параметром DefaultStringColumnLength, т.к. возможно усечение строки и падение производительности. Рекомендуется вообще избегать столбцов с длинными строками. Также следует поработать с конфигурацией MaxBytesPerFetchRequest, которая указывает максимальное количество байтов, извлекаемых с сервера для каждого вызова FetchResults при использовании Apache Arrow для сериализации. В частности, следующие значения используются по умолчанию для параметров конфигурации подключения BI-системы Power BI к Databricks через ODBC:
Driver = “Simba Spark ODBC Driver”, Host = ValidatedHost, HTTPPath = httpPath, Port = 443, ThriftTransport = 2, SparkServerType = 3, SSL = 1, UseNativeQuery = 0, UserAgentEntry = “PowerBI”, UseSystemTrustStore = 1, RowsFetchedPerBlock = 200000, LCaseSspKeyName = 0, ApplySSPWithQueries = 0, DefaultStringColumnLength=65535, DecimalColumnScale = 10, UseUnicodeSqlCharacterTypes = 1
Как уже упоминалось, извлечение/выборка результатов — самая затратная часть при запросе больших объемов данных, т.к. обслуживание данных происходит в однопоточном режиме вместе с процессами их сериализации/десериализации с использованием ODBC. Cloud Fetch и Apache Arrow могут повысить эффективность этих процессов, параллельно извлекая данные через HTTP непосредственно из облачного хранилища через набор URL-адресов, предоставляемых конечной точкой Databricks. Таким образом, можно использовать параллелизм для обслуживания данных, а также Apache Arrow для предоставления данных в оптимизированном формате сериализации, что ускоряет обмен данными с очень низкими накладными расходами. Чтобы интерфейс ODBC мог использовать его, нужно установить драйвер ODBC не ниже версии 2.6.17 и использовать среду выполнения Databricks 8.3 или выше. Стоит убедиться, что отметить, что Apache Arrow поддерживает работу со сложными типами данных, такими как MapType, ArrayType или StructType.
Чтобы проверить использование Cloud Fetch, можно посмотреть последний элемент mapPartitionsInternal в DAG выполнения запроса соответствующего задания: он должен содержать CloudStoreCollector. Также можно проверить вывод библиотеки логирования Log4j в журнале драйвера Databricks на наличие таких событий, как HybridCloudStoreResultHandler и ArrowResultHandler. Cloud Fetch используется только для результатов запроса размером более 1 МБ, а вышеотмеченный DAG по-прежнему будет сообщать о CloudStoreCollector, даже если запрос просто возвращает 5248 байт с 10 строками.
Еще один простой способ ускорить выполнение запросов без изменения кода — выбрать типы экземпляров, поддерживающие новый исполнительный механизм Spark Photon, написанный на C++, вместе с ускоренным дисковым кэшированием. Хотя это не связано напрямую с драйвером ODBC, эти проприетарные функции Databricks сильно увеличивают производительность, особенно когда данные уже кэшированы на локальных томах SSD-дисков вычислительных узлов с использованием быстрого промежуточного формата данных.
Если этот механизм кэширования активирован, он автоматически создает локальную копию каждый раз, когда удаленный Parquet-файл данных (включая таблицы Delta Lake) должен быть извлечен из удаленного хранилища. Если активно разогревать кэш с помощью команды CACHE SELECT, все файлы данных будут загружены на локальные машины, а любые предстоящие изменения будут автоматически синхронизированы. Для его активации необходимо настроить следующие параметры:
spark.databricks.io.cache.enabled true spark.databricks.io.cache.maxDiskUsage 50g spark.databricks.io.cache.maxMetaDataCache 1g spark.databricks.io.cache.compression.enabled false
Наиболее важным параметром здесь является maxDiskUsage, указывающий дисковое пространство, зарезервированное для каждого узла для кэширования. Текущее значение использования этого ресурса можно посмотреть в веб-интерфейсе ApacheSpark. Также есть множество других методов оптимизации Databricks и Delta Lake, причем некоторые из них выполняются автоматически. Но, независимо оптимизации физического уровня данных в Databricks, клиентскому приложению все равно необходимо извлекать результаты через какой-либо интерфейс, что является узким местом всей Big Data системы. Отмеченные аспекты позволят свести эту проблему к минимуму.
Освойте администрирование и эксплуатацию Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark