 547
547 
Как Apache Spark организует параллельные вычисления, зачем нужны аккумуляторы и каким образом они помогают организовать мониторинг качества данных в аналитических конвейерах их обработки. Смотрим с точки зрения дата-инженера и разработчика распределенных приложений.
Как Apache Spark распараллеливает обработку данных
Параллельная обработка — это метод вычислений, при котором работает более одного ЦП для обработки отдельных частей всей задачи. Предположим, есть 1 ГБ данных, и нужно агрегировать определенный столбец. Чтобы обработать этот огромный объем данных, их можно разделить на несколько блоков/разделов, например, на 4 (каждый по 250 МБ). Далее следует написать код, который будет выполняться параллельно, или преобразовать его в параллельный формат после того, как эта агрегация будет выполнена. 4 разных раздела с данными могут находиться на разных узлах или жестких дисках, что обходится довольно дорого. На помощь приходят технологии параллельной обработки данных, такие как Apache Spark – распределенный вычислительный движок общего назначения. Он обрабатывает огромные объемы данных в оперативной памяти, что ускоряет время выполнения вычислений.
Рассматриваемый 1 ГБ данных следует отправить в Spark, где есть. Фреймворк имеет компонент под названием SparkContext или узел драйвера, который получает данные и помещает их в кластер. SparkContext делит все данные на несколько разделов, количество которых определяется пользователем. Движок сам выполняет задание параллельно, но разработчик может повысить уровень параллелизма, увеличив количество разделов. В Apache Spark память распределяется между ядрами ЦП, которые называются рабочими узлами (worker). Их работа заключается в выполнении задачи и возврате результатов узлу драйвера. Менеджер кластера (менеджер ресурсов) отслеживает узлы, доступные в кластере.
Возвращаясь к рассматриваемому примеру обработки данных 1 ГБ, разделенных на 4 раздела по 250 МБ, отметим, что их можно распределить поровну между 2 ядрами ЦП, по 2 раздела на ядро. И эти разделы будут находиться в памяти, что намного быстрее, чем жесткие диски.
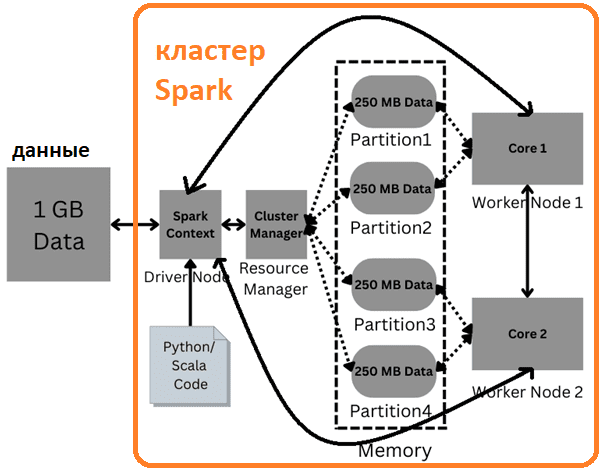
Разделы будут работать параллельно и им нужны структуры данных для хранения в памяти. Такими структурами данных в Apache Spark являются RDD, DataFrame, Dataset. Разделы 1 и 3 будут выполняться параллельно, как и разделы 2 и 4. После выполнения вычислений с каждым разделом они будут агрегированы в рабочих узлах или отправлены обратно на узел драйвера для выполнения агрегации.
При том, что Spark отлично справляется с обработкой огромных объемов информации, реализуя конвейер взаимосвязанных заданий, организовать мониторинг качества данных в этом фреймворке не так-то просто. Однако, дата-инженеру очень важно убедиться, что данные соответствуют определенной схеме, формату и размеру. Далее рассмотрим, как организовать такой мониторинг получать оповещения, когда критерии качества не выполняется.
Аккумуляторы и качество данных
Spark оценивает код до фактической массовой обработки. Но обычно это означает, что если нужно два приемника данных (один для расчетов качества, а другой для хранения преобразованных результатов), то придется дважды прочитать данные, что дорого с точки зрения операций ввода-вывода. Альтернативами будут контрольные точки или сохранения данных на диске или в памяти, что также имеет низкую производительность, особенно заметную при работе в потоковом режиме реального времени.
Вместо этого можно применить альтернативный подход, основанный на аккумуляторах и удаляемом источнике метрик Spark, который позволяет отслеживать качество данных в режиме реального времени, в процессе их обработки, а не в отдельно созданных заданиях. Напомним, аккумуляторы похожи на глобальные переменные в приложении Spark и часто используются как счетчики MapReduce, чтобы отслеживать что-то на уровне приложения. Когда исполнитель кластера отправляет задачу драйвером, каждый узел кластера получает копию общих переменных. Переменные, которые добавляются с помощью связанных операций, являются аккумуляторами. Например, реализация сумм и счетчиков – яркие примеры задач-аккумуляторов, поскольку числовые типы поддерживаются Spark проще других типов данных. Впрочем, разработчик может реализовать поддержку собственных типов данных.
Для обновлений аккумулятора, выполняемых только внутри действий, Spark гарантирует, что обновление аккумулятора каждой задачи будет применено только один раз. Это значит, что перезапущенные задачи не будут обновлять значение. Но обновление каждой задачи может использоваться более одного раза, если задачи или этапы задания выполняются повторно. Аккумуляторы не изменяют модель отложенных вычислений Spark: если они обновляются в рамках операции над распределенной коллекцией данных (RDD), их значение обновляется только после реализации действия, а не преобразования. Об отличиях этих операций в Apche Spark мы писали здесь и здесь.
Возвращаясь к мониторингу качества данных с помощью аккумуляторов, рассмотрим пример отслеживания общей метрики такой как процент отсутствующих значений (NULL). Можно использовать встроенную функцию Spark для наблюдения, чтобы накапливать нужные значения вместе с существующим преобразованием данных:
import org.apache.spark.sql.functions._
spark
.readStream
.format("<input format>")
.options(...)
.load()
.withColumn(...) // Some Data Transformation
.observe("total_null_values", sum(when(col("col1").isNull, lit(1)).otherwise(lit(0))))
.observe("total_non_null_values", sum(when(col("col1").isNull, lit(0)).otherwise(lit(1)))))
.writeStream
.format("<output format>")
.options(...)
.queryName("my_query")
.start()
Вместо этого можно использовать аккумуляторы, обернутые в UDF-функции. Это увеличит накладные расходы на сериализацию и десериализацию записей, а также снизит дополнительную оптимизацию производительности, поскольку пользовательские функции считаются черным ящиком для оптимизатора запросов Spark. Впрочем, если есть необходимость в расширенной логике аккумулятора, создание пользовательских аккумулятор в виде UDF-функций вполне возможно.
Spark имеет настраиваемую систему метрик, которая позволяет пользователям сообщать системные метрики в различные приемники, включая Prometheus, HTTP, Grafite и пр. Можно создать новый пользовательский источник показателей, например:
import org.apache.spark.metrics.source.Source
import org.apache.spark.sql.Row
import com.codahale.metrics.MetricRegistry.MetricSupplier
import com.codahale.metrics.{Gauge, MetricRegistry}
class MyNewAccumulatorSource extends Source {
val sourceName: String = "MyNewAccumulatorSource"
val metricRegistry: MetricRegistry = new MetricRegistry
private[MyNewAccumulatorSource] val ADDITIONAL_METRIC_PREFIX = "accumulator"
@volatile var observedAccumulatorsSnapshot: Map[String, Long] = Map.empty[String, Long]
def updateObservedValues(observedValues: Map[String, Row]): Unit = {
observedAccumulatorsSnapshot ++= observedValues.map { case (name, row) =>
name -> row.getAs[Long](0)
}
observedAccumulatorsSnapshot.foreach { case (name, _) => registerObservedIfNotExists(name) }
}
private class ObservedMetricGauge(accName: String) extends Gauge[Long] {
def getValue: Long = observedAccumulatorsSnapshot.getOrElse(accName, -1)
}
protected def registerObservedIfNotExists(accumulatorName: String): Unit = {
val gaugeInitializer: MetricSupplier[Gauge[_]] = () => new ObservedMetricGauge(accumulatorName)
metricRegistry.gauge(MetricRegistry.name(ADDITIONAL_METRIC_PREFIX, accumulatorName), gaugeInitializer)
}
}
Далее следует зарегистрировать пользовательский источник метрик, чтобы они стали доступны любому зарегистрированному приемнику мониторинга, такому как PrometheusServlet, JmxSink, Graphite или REST API Spark.
val myMetricSource = new MyNewAccumulatorSource spark.sparkContext.env.metricsSystem.registerSource(myMetricSource)
При использовании потоковой передачи Spark рекомендуется экспортировать наблюдаемые значения через StreamingQueryListener, который будет автоматически запускать настроенный код в конце каждого микропакета.
import org.apache.spark.sql.streaming.StreamingQueryListener
import org.apache.spark.sql.streaming.StreamingQueryListener.QueryProgressEvent
import scala.collection.JavaConverters._
class UpdateObservedValuesListener extends StreamingQueryListener {
override def onQueryProgress(event: QueryProgressEvent): Unit = {
if (event.progress.name != "my_query") {
return
}
val valuesMap = event.progress.observedMetrics.asScala.toMap
myMetricSource.updateObservedValues(valuesMap)
}
}
Напомним, самым надежным способом получения фактических значений системных метрик Spark-приложений является API слушателей (Listener), который позволяет разработчикам отслеживать события, которые среда генерирует во время выполнения приложения (запуск и завершение, задания, этапы и пр.). Эти слушатели можно настроить и использовать для сбора собственных показателей. После выполнения каждой операции Spark вызовет Listener и передаст ему эти метаданные, включая время выполнения, чтение/запись строк, байтов и другую подобную информацию. Подробнее об этом мы рассказывали в этой статье. Регистрация слушателя гарантирует, что он сработает:
spark.streams.addListener(new UpdateObservedValuesListener)
Аналогично для пакетных заданий можно использовать QueryExecutionListener. Начиная с Spark 3.3.0, также можно получать наблюдаемые значения через объект наблюдения:
val observation = Observation("my metrics")
df
.observe(observation,
sum(when(col("col1").isNull, lit(1)).otherwise(lit(0))).as("total_null_values"),
sum(when(col("col1").isNull, lit(0)).otherwise(lit(1)))."total_non_null_values"))
.writeStream
.format("<output format>")
.start()
// The observed values can be accessed via:
val valuesMap = observation.get
После того, как наблюдаемые аккумуляторы связаны с источником метрик, можно подключить его к предпочтительной системе мониторинга, например, PrometheusServelt поверх Kubernetes.
Освойте администрирование и эксплуатацию Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

