
Сегодня заглянем под капот Apache NiFi, чтобы понять, какие данные хранит этот потоковый ETL-маршрутизатор, зачем и где. Репозитории Apache NiFi для администратора, дата-инженера и проектировщика конвейеров обработки данных: как они устроены и какие практики улучшают их работу.
Репозитории Apache NiFi: что это такое и зачем они нужны
В Apache NiFi есть 3 репозитория, каждый из которых существует в файловой системе хоста и предоставляет определенные функции. Все они представляют собой каталоги в локальном хранилище, которые NiFi использует для хранения данных. Репозиторий FlowFile содержит метаданные для всех текущих потоковых файлов, репозиторий контента хранит содержимое для текущих и прошлых потоковых файлов, и их история хранится в репозитории происхождения (Provenance).
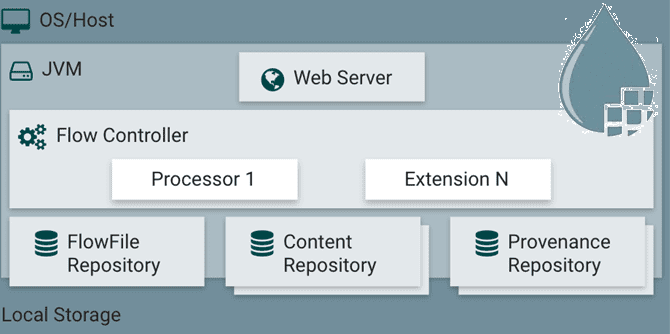
Чтобы понять, для чего нужен каждый из упомянутых репозиториев, рассмотрим их более подробно.
Репозиторий FlowFile
Потоковые файлы, которые активно обрабатываются, хранятся в виде хэш-карты в памяти виртуальной машины Java, что эффективно для обработки. Но из-за локального характера такого хранения данных нужен механизм обеспечения отказоустойчивости при перезапусках процессов из-за потери питания, сбоя ядра, обновления системы и прочих причин. Репозиторий FlowFile – это журнал опережающей записи (WAL, Write Ahead Log) метаданных каждого потокового файла, который в текущий момент существует в системе. Эти метаданные включают в себя все атрибуты FlowFile, в т.ч. указатель на его фактическое содержимое, хранящееся в репозитории контента, и состояние потокового файла, например, к какому соединению или очереди он принадлежит сейчас. WAL обеспечивает отказоустойчивость NiFi.
Поскольку репозиторий FlowFile действует как журнал упреждающей записи NiFi, в нем транзакционно регистрируется любое будущее изменение, когда потоковые файлы проходят через систему. Это позволяет системе точно знать, на каком этапе находится узел при обработке фрагмента данных. Если узел вышел из строя во время обработки данных, он может легко возобновить работу с того места, на котором остановился, после перезапуска. Запись потокового файла в WAL-журнале представляет собой серию изменений, которые произошли с ним по пути. NiFi восстановит потоковый файл, используя моментальный снимок контрольной точки репозитория, а затем воспроизводит каждое из записанный в WAL-журнале изменений.
Система периодически автоматически делает моментальный снимок, который создает новый снимок для каждого FlowFile и вычисляет новую базовую контрольную точку, сериализуя каждый FlowFile в хэш-карте и записывая его на диск в виде файла с расширением .partial. Туда же записываются новые базовые показатели потокового файла. После создания контрольной точки старый файл моментального снимка удаляется, а файл .partial переименовывается в snapshot. Период между системными контрольными точками настраивается в файле nifi.properties и по умолчанию равен 2 минуты.
Как уже было отмечено, этот механизм обеспечивает отказоустойчивость NiFi: если узел был в процессе записи контента во время сбоя, данные не повредятся благодаря копированию при записи и неизменяемости. Поскольку транзакции FlowFile никогда не изменяют исходное содержимое, на которое указывает указатель контента, оригинал является безопасным. При сбое NiFi-приложения запрос на запись для изменения теряется, а затем очищается фоновой сборкой мусора JVM, обеспечивая откат к последнему известному стабильному состоянию. Затем узел восстанавливает свое состояние из потокового файла. Такой транзакционный механизм обеспечивает устойчивость NiFi и возможность восстановления без потери данных.
Справедливости ради стоит отметить, что термин потоковый файл (FlowFile) может привести к мысли, что каждый FlowFile соответствует файлу на диске, но это не совсем так. Есть два основных места, где существуют атрибуты FlowFile: WAL-журнал и хэш-карта в рабочей памяти, которая содержит ссылку на все файлы FlowFiles, активно используемые в потоке. Объект, на который ссылается эта карта, используется процессорами и хранится в очередях соединений. Поскольку объект FlowFile хранится в памяти, то процессору для его обработки следует запросить ProcessSession получить его из очереди.
При изменении FlowFile, дельта записывается в WAL-журнал, и объект в памяти модифицируется. Это позволяет системе быстро работать с потоковыми файлами, а также отслеживать, что произошло и что произойдет, когда сеанс будет зафиксирован. Если количество потоковых файлов в очереди подключения превышает значение, установленное в свойстве nifi.queue.swap.threshold, то объекты с самым низким приоритетом в очереди соединений сериализуются и записываются на диск в виде файла подкачки партиями по 10 000. Затем эти FlowFiles удаляются из хэш-карты оперативной памяти, а очередь соединений определяет, когда нужно выгрузить их обратно в память. При замене потоковых файлов репозиторий FlowFile уведомляется и сохраняет список файлов подкачки. Когда система находится в контрольной точке, моментальный снимок включает раздел для выгруженных файлов. При возвращении потоковых файлов обратно, объекты снова добавляются в хэш-карту памяти. Этот метод очень похож на подкачку, выполняемую большинством операционных систем (swap). Он позволяет NiFi обеспечивать очень быстрый доступ к множеству потоковых файлов, которые активно обрабатываются, позволяя огромному количеству объектов существовать в потоковом конвейере, не истощая системную память.
Репозиторий контента
Репозиторий содержимого — это место в локальном хранилище, где хранится контент всех потоковых файлов. Этот репозиторий является самым большим из всех трех репозиториев NiFi. Он использует парадигмы неизменяемости и копирования при записи, чтобы повысить скорость и потокобезопасность. Содержимое потоковых файлов хранится на диске и считывается в память JVM только при необходимости. Это позволяет NiFi обрабатывать крошечные и массивные объекты, не требуя, чтобы процессоры продюсеров и потребителей хранили их в памяти. Подобно тому, как в куче JVM есть процесс сборки мусора для восстановления недоступных объектов, в NiFi есть выделенный поток для анализа репозитория контента на наличие неиспользуемого содержимого, чтобы очистить место в памяти и на диске.
Если содержимое потокового файла определено как неиспользуемое, оно удаляется или архивируется при включенной настройке в nifi.properties. Содержимое FlowFile хранится в репозитории контента, пока он не устареет, а удаляется через определенное время или когда это хранилище занимает слишком много места. Условия архивации и удаления настраиваются в файле nifi.properties через конфигурации nifi.content.repository.archive.max.retention.period, nifi.content.repository.archive.max.usage.percentage.
Справедливости ради стоит отметить, что хотя ссылка на содержимое потокового файла называется указателем контента, ее базовая реализация имеет несколько уровней сложности. Репозиторий контента состоит из набора файлов на диске, которые объединены в контейнеры и разделы (подкаталоги) контейнера. Контейнер можно рассматривать как корневой каталог для репозитория контента. Контейнеров может быть много, чтобы NiFi мог параллельно использовать несколько физических разделов, читая и записывая на диски параллельно для высокой пропускной способности диска порядка гигабайт в секунду на одном узле. Java-объекты Resource Claim указывают на определенные файлы на диске путем отслеживания их идентификаторов, а также идентификаторов раздела и контейнера.
Чтобы отслеживать содержимое потокового файла, используется объект Content Claim со ссылкой ресурс, который содержит контент, его смещение в файле и длину. Чтобы получить доступ к содержимому, репозиторий контенту переходит к конкретному файлу на диске, используя свойства Resource Claim, а затем ищет указанное смещение перед потоковой передачей содержимого из файла.
Resource Claim был создан для того, чтобы на диске не было файла для содержимого каждого FlowFile. Поскольку само содержимое потокового файла не изменяется после его записи, а внесение изменений реализуется через создание копий, при изменении содержимого FlowFile не происходит фрагментации памяти или перемещения данных. Используя один физический файл на диске для хранения содержимого нескольких FlowFile, NiFi обеспечивает высокую пропускную способность, приближающуюся к максимальной скорости передачи данных, обеспечиваемой дисками.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
10 сентября, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Репозиторий происхождения
Репозиторий происхождения хранит история каждого FlowFile, что нужно для цепочки хранения каждой части данных. Каждый раз, когда с потоковым файлом происходит событие создания, разделения, модификации и пр., создается новое событие происхождения – моментальный снимок FlowFile в том виде, в каком он выглядел и вписывался в поток, существовавший на тот момент времени. Когда создается событие происхождения, оно копирует все атрибуты FlowFile и указатель на содержимое FlowFile и объединяет их с состоянием FlowFile, например, его отношениями с другими событиями происхождения в одно место в репозитории Provenance. Этот моментальный снимок не изменится, пока срок действия данных не истек, т.е. не прошел период времени, указанный в файле nifi.properties.
Поскольку все атрибуты FlowFile и указатель на содержимое хранятся в репозитории происхождения, диспетчер потоков данных может видеть историю обработки этого фрагмента данных, а также просматривать и воспроизводить эти данные из любой точки потока. Это полезно, когда нижестоящая система не получила данные. Происхождение данных может точно показать, когда данные были доставлены в нижестоящую систему из-за сбоя при их приеме, хотя фактически они были отправлены. Событие отправки можно быстро воспроизвести в GUI или HTTP-вызовом к конечной точке, чтобы повторно отправить данные в конкретную систему. Если же данные не были обработаны корректно, поток можно исправить и повторно воспроизвести для правильной обработки.
Однако, поскольку репозиторий Provenance не копирует содержимое в репозиторий контента, а просто копирует указатель FlowFile на содержимое, контент может быть удален до фактического удаления события, которое на него ссылается. Это значит, что пользователь не сможет видеть контент или воспроизводить FlowFile позже. Но дата-инженер по-прежнему сможет просматривать происхождение потокового файла и понимать, что произошло с данными, включая их уникальный идентификатор, время и способ получения, операции изменения, время и место отправки и пр. Благодаря доступности атрибутов FlowFile диспетчер потока данных может понять, почему данные обработаны именно так, что важно при отладке конвейера.
Поскольку события происхождения являются моментальными снимками FlowFile в том виде, в каком он существует в текущем потоке, изменения в потоке могут повлиять на возможность последующего воспроизведения этих событий. Например, если соединение удалено из потока, данные не могут быть воспроизведены из этой точки потока, т.к. их некуда поставить в очередь для обработки.
Каждое событие происхождения имеет две карты: одну для атрибутов до события и одну для обновленных значений атрибутов. Как правило, события происхождения сохраняют не обновленные значения атрибутов в том виде, в каком они существовали на момент создания события, а вместо этого значения атрибутов при фиксации сеанса. События кэшируются и сохраняются до тех пор, пока сеанс не будет зафиксирован. После фиксации сеанса, события генерируются с атрибутами FlowFile, кроме события SEND, которое содержит атрибуты, существовавшие на момент создания события, чтобы сами атрибуты также были отправлены вместе с полезной информацией.
Во время работы NiFi существует скользящая группа из 16 файлов журнала происхождения, в один из которых записываются события для увеличения пропускной способности. Эти файлы периодически обновляются, по умолчанию каждые 30 секунд, т.е. вновь созданные события пишутся в новую группу, а исходные обрабатываются для долгосрочного хранения, объединяясь в один файл. Затем этот файл дополнительно сжимается согласно значению свойства nifi.provenance.repository.compress.on.rollover. Наконец, события индексируются с помощью Lucene и становятся доступными для запросов. Такой пакетный подход к индексированию не позволяет сделать события происхождения доступными для запроса немедленно, но значительно повышает производительность.
Отдельный поток обрабатывает удаление журналов происхождения. Администратор Apache NiFi может установить 2 условия для управления удалением журналов происхождения: максимальный объем дискового пространства, который он может занимать, и максимальный срок хранения журналов. Поток сортирует репозиторий по дате последнего изменения и удаляет самый старый файл при превышении одного из условий.
Репозиторий Provenance — это индекс Lucene, разбитый на несколько сегментов, т.к. Lucene использует 32-битное целое число для идентификатора документа, поэтому максимальное количество документов, поддерживаемых движком без сегментирования, ограничено. Знание временного диапазона для каждого сегмента упрощает поиск с использованием нескольких потоков. А сегментирование позволяет более эффективно удалять: NiFi ждет, пока все события в сегменте не будут запланированы для удаления, прежде чем удалить весь сегмент с диска. Таким образом, не нужно обновлять индекс Lucene при удалении.
Для репозиториев Provenance и Content есть возможность распределить информацию по нескольким физическим разделам, если нужно объединить операции чтения и записи на нескольких дисках. Репозиторий по-прежнему является одним логическим хранилищем, но записи будут автоматически распределяться системой по нескольким томам/разделам, каталоги которых задаются в файле nifi.properties.
Считается хорошей практикой анализировать содержимое FlowFile как можно меньше, вместо этого извлекая ключевую информацию из содержимого в атрибуты FlowFile, чтобы читать или записывать информацию из них. Например, именно так работает процессор ExtractText, который извлекает текст из содержимого FlowFile и помещает его в качестве атрибута, чтобы его могли использовать другие процессоры. Это обеспечивает более высокую производительность, чем непрерывная обработка всего содержимого FlowFile, поскольку атрибуты хранятся в памяти, а обновление репозитория FlowFile происходит быстрее, чем репозитория контента, учитывая объем данных, хранящихся в каждом из них.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
10 сентября, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Узнайте больше подробностей по администрированию и эксплуатации Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

