 917
917 
Мы уже рассказывали, что Apache Flink использует Calcite для оптимизации SQL-запросов. Продолжая разбирать эту тему, важную для обучения разработчиков Flink-приложений и дата-инженеров, сегодня рассмотрим, как отследить происхождение отношения на уровне поля, используя методы класса RelMetadataQuery в Calcite.
Что такое Apache Calcite и при чем здесь Flink SQL
Напомним, Apache Flink предоставляет высокоуровневый декларативный API на основе стандартного языка SQL-запросов. В отличие от API DataStream, чьи примитивы потоковой обработки в низкоуровневом императивном API сразу преобразуются в граф выполнения, программа на Flink SQL проходит ряд сложных преобразований перед выполнением. Для этого Flink использует Apache Calcite — инфраструктуру управления динамическими данными, которая содержит многие элементы СУБД, но не включает такие ключевые функции, как хранение данных, алгоритмы их обработки и репозиторий метаданных. Благодаря тому, что Calcite намеренно не занимается хранением и обработкой данных, он становится отличным посредником между приложениями, местами хранения данных и механизмами их обработки. Кроме того, Calcite может быть основой для создания базы данных, куда их следует просто добавить.
Calcite может работать с любым источником данных и форматом данных. Чтобы добавить источник данных, нужно написать адаптер, который сообщает Calcite, какие коллекции в источнике данных следует рассматривать как таблицы. Также можно написать собственные правила оптимизатора, которые позволяют Calcite получать доступ к данным нового формата, регистрировать новые операторы и оптимизировать преобразование запросов. Calcite объединит пользовательские правила и операторы со своими встроенными, применит оптимизацию на основе затрат и создаст эффективный план выполнения SQL-запроса.
Для этого Calcite включает парсер, валидатор и оптимизатор SQL-запросов, может читать чтения модели данных в формате JSON, имеет множество стандартных и агрегатных функций SQL (SELECT, FROM, JOIN, WHERE, LIMIT, GROUP BY, GROUPING SETS, COUNT, DISTINCT, FILTER, HAVING, ORDER BY, UNION, INTERSECT, MINUS, подзапросы и оконные агрегаты), умеет работать с локальными и удаленными JDBC-драйверами и поддерживает их запросы к бэкендам Linq4j и JDBC.
Таким образом, Apache Calcite — это среда управления динамическими данными с открытым исходным кодом, которая применяет идею SQL-запросов к большим данным, предоставляя унифицированный механизм запросов для различных вычислительных платформ и источников данных без средств их хранения и алгоритмов обработки. Именно этот движок лежит в основе Flink SQL.
Рабочий процесс Calcite обычно разделен на этапы синтаксического анализа (парсинга), валидации, конвертации и оптимизации. При синтаксическом анализе CalciteSQL синтаксическое дерево SqlNode, сгенерированное синтаксическим анализатором, преобразуется в реляционное дерево операторов (RelNode) после проверки валидатором.
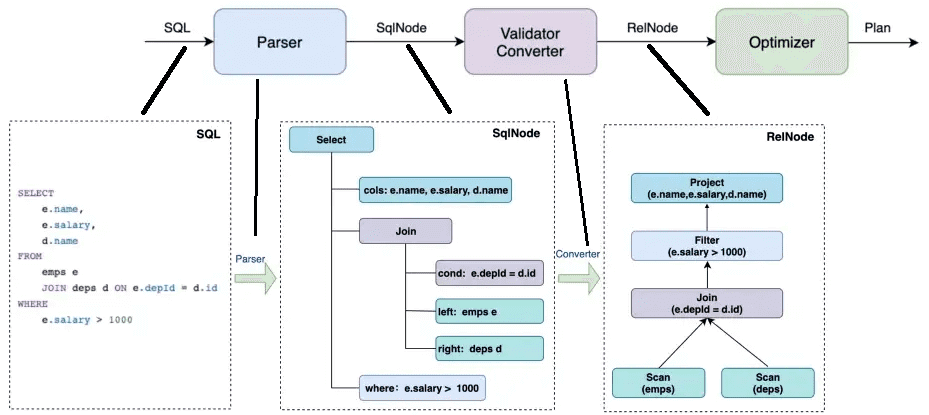
Этапы выполнения SQL-запросов
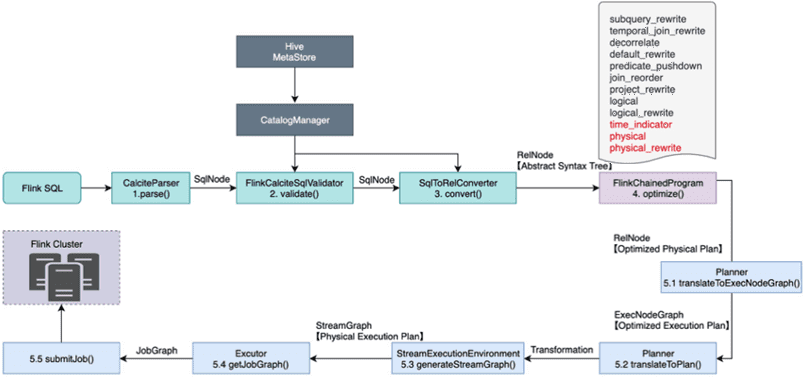
Разобравшись с тем, как работает Calcite, рассмотрим процесс выполнения Flink SQL, который состоит из следующих этапов:
- парсинг – на этапе синтаксического анализа используется JavaCC для преобразования SQL-запроса в абстрактное синтаксическое дерево (AST), которое представлено SqlNode в Calcite;
- валидация — грамматическая проверка метаданных, например о том, существуют ли запрошенная таблица, поле и функция. Также здесь проверяются операторы SQL-запроса: условия WHERE, FROM, GROUP BY, HAVING, ORDER BY и пр. После этой проверки SqlNode преобразуется в AST-дерево.
- преобразование – семантический анализ на основе информации SqlNode и метаданных для построения реляционного дерева выражений RelNode, которое является исходной версией логического плана.
- оптимизация логического плана, когда оптимизатор выполняет эквивалентные преобразования на основе правил, таких как проталкивание предикатов (predicate pushdown – оптимизация, которая применяет условия как можно раньше, предотвращая загрузку ненужных строк), сокращение столбцов и прочие оптимизации, чтобы получить оптимальный план выполнения SQL-запроса.
- выполнение – преобразование логического плана SQL-запроса в план физического выполнения, генерация графов выполнения потоков (StreamGraph) и заданий (JobGraph), которые отправляются в работу.
Таким образом, анализ происхождения поля во Flink SQL включает парсинг, проверку и преобразование исходного SQL-запроса для создания реляционного дерева выражения (RelNode), соответствующего первым 3-м шагам в схеме выполнения Flink SQL. Далее на этапе оптимизации вместо исходного оптимизированного физического плана может быть создан только оптимизированный логический план, что соответствует шагу 4 в схеме выполнения Flink SQL. Наконец, для логического RelNode, сгенерированного оптимизацией на предыдущем шаге, вызывается метод getColumnOrigins(RelNode rel, int column) класса RelMetadataQuery, чтобы запросить информацию об исходном поле.
Класс RelMetadataQuery в Apache Calcite обеспечивает строго типизированный фасад поверх RelMetadataProvider для набора запросов метаданных реляционных выражений, определенных как стандартные в Calcite. Поскольку метаданные реляционных выражений являются расширяемыми, проекты расширения могут определять аналогичные фасады, чтобы указать доступ к пользовательским метаданным. Не рекомендуется добавлять сюда и в RelNode SQL-запросы, которые не имеют значения за пределами пользовательского расширения.
Помимо добавления новых запросов метаданных, проектам расширения может потребоваться добавить настраиваемых поставщиков для стандартных запросов, чтобы обрабатывать дополнительные логические или физические реляционные выражения. В любом случае процесс один и тот же: следует написать отражающий провайдер и привязать его к экземпляру DefaultRelMetadataProvider, предварительно отложив его к провайдерам по умолчанию. Затем надо передать этот экземпляр планировщику через соответствующий механизм плагина.
Про тестирование SQL-кода в приложениях Apache Flink читайте в нашей новой статье.
Освойте тонкости использования Apache Flink и Spark для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

