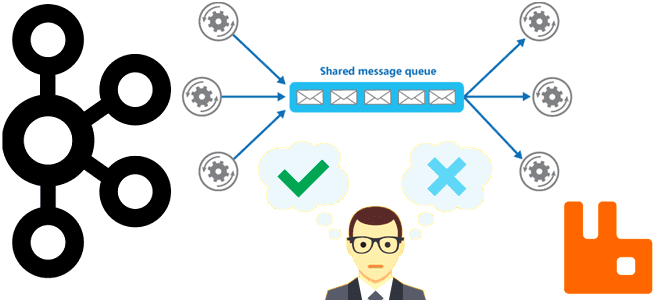
Какие проблемы характерны для распределенных очередей сообщений, почему они случаются и как с ними справиться. Разбираемся со сбоями, ошибками и перегрузками на примере Apache Kafka и RabbitMQ. Проблемы с распределенными очередями и главные причины их появления Хотя Apache Kafka — это целая экосистема со множеством компонентов для потоковой передачи событий,...
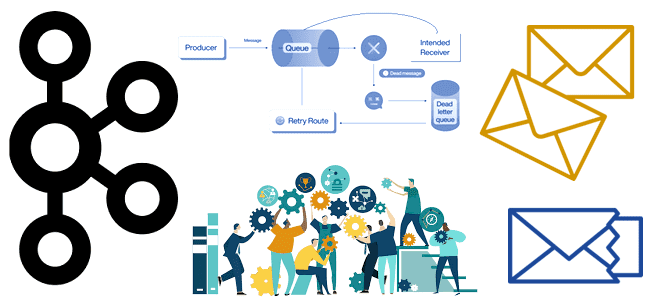
Недавно мы писали про очереди недоставленных сообщений в Apache Kafka и RabbitMQ. Сегодня поговорим про стратегии обработки ошибок, связанные с DLQ-очередями в Kafka, а также рассмотрим, какие сообщения НЕ надо помещать в Dead Letter Queue. 4 стратегии работы с DLQ-топиками в Apache Kafka Напомним, в Apache Kafka в очереди недоставленных...
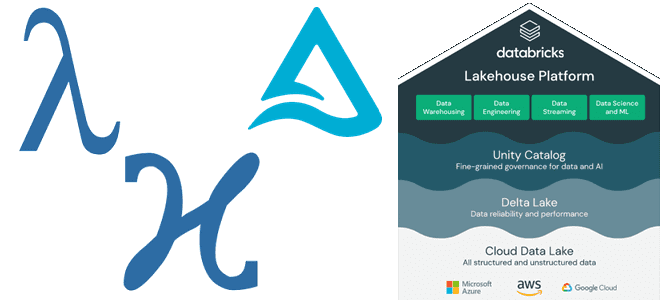
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming. Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности,...
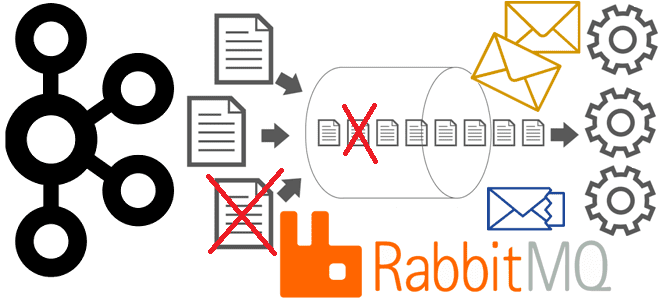
Сегодня рассмотрим, зачем в системах асинхронного обмена данными нужны очереди недоставленных сообщений, как их организовать и обработать. Разбираемся с Dead Letter Queue на примере Apache Kafka и RabbitMQ. Обработка недоставленных сообщений в Apache Kafka Хотя Apache Kafka и RabbitMQ не являются взаимозаменяемыми альтернативами, именно эти системы чаще всего используются для...
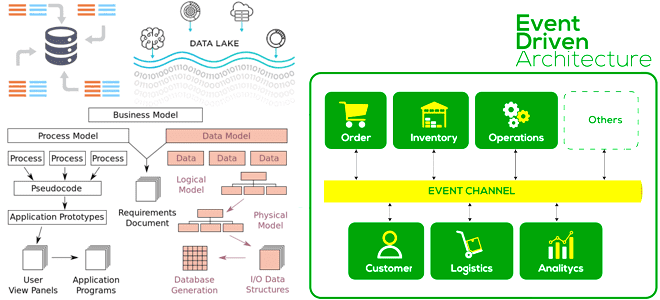
Чем схема, применяемая к данным, при чтении отличается от схемы при записи, почему она вызывает GIGO-проблему в Data Lake, и как применить принципы функциональной дата-инженерии к архитектуре данных, управляемой событиями. Схема при чтении или при записи: главное отличие NoSQL-решений от реляционных СУБД NoSQL-решения и Apache Hadoop реализуют стратегию «схема при...

Как организовать эффективное планирование заданий Apache Spark в микросервисной архитектуре, управляемой событиями, с помощью паттернов Idempotent Consumer и Transactional Outbox. Проблемы оркестрации Spark-заданий shell-скриптами и переход к EDA-архитектуре При большом количестве приложений Apache Spark, которые взаимодействуют друг с другом как самостоятельные микросервисы, растет сложность управления ими. В частности, shell-скрипты позволяют...

Зачем биотехнологической платформе Polly от Elucidata понадобился API SQL-запросов в облачном сервисе Elasticsearch и как дата-инженеры реализовали его, развернув Delta Lake с AWS Atnena и S3. Что не так с SQL-запросами в облачном Elasticsearch на AWS Ежедневно биотехнологическая платформа Polly от Elucidata обрабатывает гигабайты биомолекулярных данных для биологов по всему...
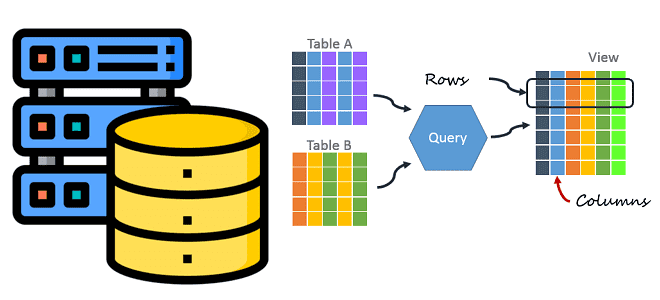
Как данные хранятся на диске при разной ориентации хранилища в СУБД: чем отличаются колоночные базы от строковых с точки зрения практического использования в дата-инженерии. Сравнительная таблица с примерами и выводами. Как данные хранятся на диске и при чем здесь ориентация СУБД Способы хранения данных в СУБД можно разделить на 2...

Что такое Delta Sharing, зачем нужен и как устроен этот открытый стандарт, а также как его использовать для централизованного управления доступом к данным в архитектуре Data Mesh. Что такое Delta Sharing и при чем здесь Data Lake Чтобы упростить обмен большими данными между разными компаниями в режиме реального времени и...

Продолжая разговор про языки запросов к графовым базам данных, сегодня познакомимся с GSQL, который поддерживается в MPP-СУБД TigerGraph. Как работает эта распределенная NoSQL-база данных и каким образом реализует ACID-требования к транзакциям в операциях с графами. Архитектура и принципы работы графовой MPP-СУБД TigerGraph — это распределенное графоориентированное хранилище данных с массивно-параллельной...