1255
1255 
Содержание
Чем схема, применяемая к данным, при чтении отличается от схемы при записи, почему она вызывает GIGO-проблему в Data Lake, и как применить принципы функциональной дата-инженерии к архитектуре данных, управляемой событиями.
Схема при чтении или при записи: главное отличие NoSQL-решений от реляционных СУБД
NoSQL-решения и Apache Hadoop реализуют стратегию «схема при чтении», которая отличается от классических методов моделирования данных, когда данные могли попасть в хранилище только в случае соответствия заранее определенной схеме. Это обеспечивало согласованность данных, однако, снижало гибкость системы. В схеме при чтении к данным применяется схема по мере их извлечения из сохраненного местоположения, а не по мере поступления. Это увеличивает объем работы при вычислениях с данными за счет упрощения процессов их загрузки в хранилище.
Схема при записи лучше подходит для получения чистых и непротиворечивых наборов данных, поэтому именно эта схема исторически использовалась при проектировании хранилищ данных (Data Warehouse, DWH), которые в упрощенном виде можно рассматривать как огромные реляционные СУБД. Схема при чтении обеспечивает более гибкую организацию данных, упрощая работу с ними через создание различных представлений. Схема при чтении характерна для озер данных (Data Lake), которые хранят данные с различной структурой для поддержки всех видов бизнес-процессов предприятия.
Однако, по мере роста объема данных, хранящихся в озерах, схема при чтении приводит к проблеме GIGO (Garbage In, Garbage Out), когда в Data Lake собирается слишком много разрозненных и противоречивых друг другу данных. При этом растет сложность управления этими данными, а само поддержка DWH превращается в технический долг вместо того, чтобы быть стратегическим преимуществом data-driven организации. Поэтому современная дата-инженерия отходит от классического моделирования данных для DWH, стремясь разделять хранилище и вычислительные ресурсы, чтобы масштабировать их независимо друг от друга, сохраняя воспроизводимость задач в конвейере данных и возможность повторного вычисления.
Для этого в DWH и Data Lake необходим переход от концепции статичных сущностей к архитектуре данных, управляемой событиями (EDA, Event-Driven Architecture), некоторые принципы которой схожи с EDA-архитектурой программных систем, активно используемой в микросервисном подходе, о чем мы недавно писали здесь. Что это означает, и как реализуется, мы рассмотрим далее.
EDA-архитектура данных
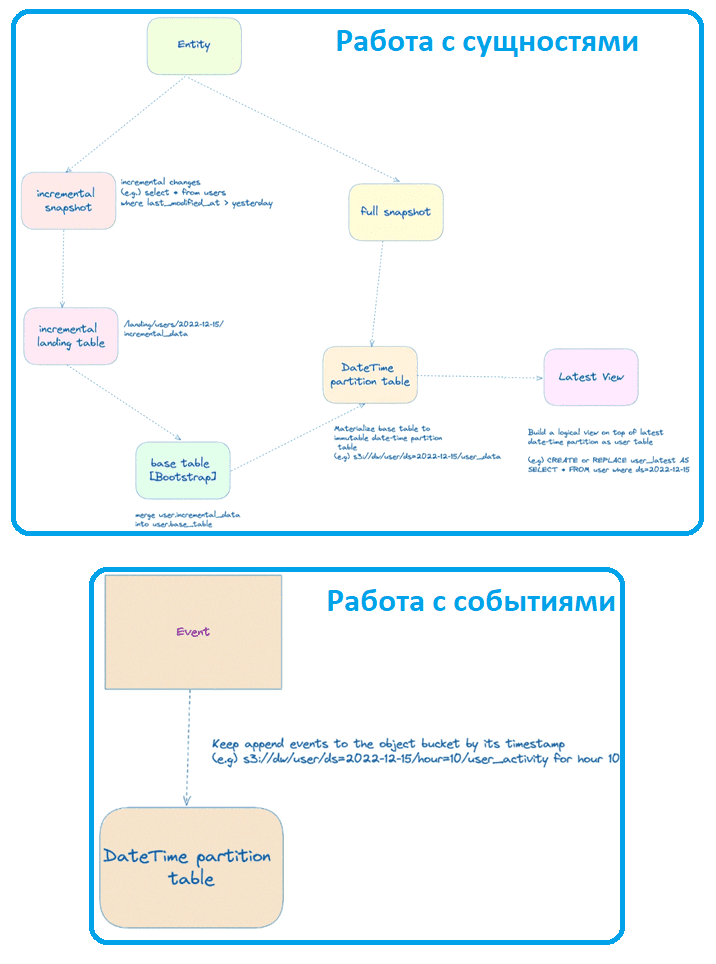
В архитектуре данных, управляемой событиями, по-прежнему присутствует понятие сущности (Entity), которое описывает объекты домена как изменяемые данные с первичным ключом: пользователь, продукт и пр. Также появляется понятие события (event), которое представляет собой случившийся факт, а потому является неизменяемыми данными с отметкой времени. Обычно событие описывает какую-то активность, произошедшую в домене, например, пользователь А добавил продукт X в корзину в момент Z. Для связи сущностей с событиями используются таблицы временных разделов, которые поддерживают полную копию текущего состояния объекта для каждого временного раздела. Поскольку сегодня большинство организаций используют облачные объектные хранилища в качестве озера данных, далее также будем придерживаться этого подхода.
Например, в классическом моделировании данных создание сущности пользователь можно представить следующим SQL-запросом:
CREATE TABLE dw.user ( user_id BIGINT, user_name STRING, created_at DATE ) PARTITION BY (ds STRING) # ds = date timestamp of the snapshot
Типичная файловая структура объектного хранилища на примере AWS S3 будет выглядеть так:
s3://dw/user/2023-12-20/<all users data at the time of snapshot> s3://dw/user/2023-12-21/<all users data at the time of snapshot>
Создание таблицы с событиями пользовательской активности (user_activity) можно представить так:
CREATE TABLE dw.user ( user_id BIGINT, activity_type STRING, event_timestamp LONG ) PARTITION BY (ds STRING, hour STRING) # ds = date timestamp of the event # hour = hour of the event [Assume the events are hourly pipeline]
Типичная файловая структура объектного хранилища также на примере AWS S3 выглядит так:
s3://dw/user_activity/2022-12-20/10/<all users activity data for the hour 10 on 2022-12-20> s3://dw/user/2022-12-20/11/<all users activity data for the hour 11 on 2022-12-20>
Конвейеры обработки данных сущностей, которые изменяются, могут работать в двух режимах: инкрементальный (incremental snapshot) и полный моментальный снимок (full snapshot).
Подход инкрементального снимка используется в CDC-технологиях (Change Data Capture) и сохраняет представление объекта по мере его изменения. Инкрементный snapshot проходит несколько дополнительных предварительных шагов, прежде чем взять разделы таблицы отметки времени:
- Загрузка добавочных данных в целевую область с разделом отметки времени;
- Объединение инкрементного снимка с базовой таблицей, которая является начальной загрузкой полной моментальной копии таблицы.
Полный моментальный снимок является относительно более простым подходом, когда берется глубокий клон исходных данных и записывается с таблицей версии отметки времени в хранилище данных. Таблица разделов отметки времени оптимизирует процесс конвейера данных, но текущее состояние объекта требует специальных аналитических запросов. В частности, добавление раздела ds в фильтр запроса усложняет его. Упростить такой SQL-запрос помогает логическое представление поверх последнего раздела:
CREATE OR REPLACE VIEW dw.user_latest AS SELECT user_id, user_name, created_at, ds FROM dw.user WHERE ds=<current DateTime partition>;
С событиями ситуация проще, т.к. они только добавляются. Это устраняет сложность слияния или создания полных моментальных снимков измерений из источника.
Реализовать такой EDA-подход к данным можно в MPP-СУБД Greenplum, которая часто используется в качестве основы для DWH. В частности, события можно хранить в AO-таблицах, оптимизированных для добавления данных, а сущности в хранилище кучи. Подробнее о лучших практиках хранения данных в Greenplum мы писали здесь.
В заключение отметим еще пару преимуществ парадигмы функциональной инженерии данных с EDA-подходом: возможность перемещения во времени как для сущностей, так и для событий, а также сокращение объема работы по предварительному моделированию данных. А благодаря разделению хранения и вычислений отладка конвейеров данных и исправление ошибок выполняются намного быстрее. Однако, принципы функциональной инженерии данных не заменяют ни один из методов моделирования данных. В частности, при проектировании витрин и хранилищ данных имеет смысл использовать подходы Кимбалла и Инмона или Data Vault. А исправить ошибки, сделанные при этом моделировании данных позволяют принципы функциональной дата-инженерии.
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники