Как организовать эффективное планирование заданий Apache Spark в микросервисной архитектуре, управляемой событиями, с помощью паттернов Idempotent Consumer и Transactional Outbox.
Проблемы оркестрации Spark-заданий shell-скриптами и переход к EDA-архитектуре
При большом количестве приложений Apache Spark, которые взаимодействуют друг с другом как самостоятельные микросервисы, растет сложность управления ими. В частности, shell-скрипты позволяют быстро отправить задание в кластер Spark, что отлично работает на маленьких масштабах. Но со временем скрипт начал управлять другими задачами, включая обработку зависимостей заданий, обновление состояния сущностей в базе данных и выполнение проверок достоверности данных после завершения вычислений. Это реализует синхронный принцип работы, что плохо масштабируется и не подходит для управления множеством сервисов.
Кроме того, управление транзакциями в shell-скриптах довольно затруднительно, особенно когда обновления базы данных комбинируются с вызовами сторонних API, которые могут не идемпотентными. Это чревато плохой обработкой ошибок и отказов, т.к. скрипт порождает новые сущности, которые должны иметь согласованные состояния в базе данных перед повторным запуском скрипта.
С точки зрения эксплуатации и сопровождения скрипт может вносить дополнительную путаницу в журналы логов, в т.ч. из-за задержки возврата идентификатор приложения Spark. В частности, если задание отправлено в кластер Spark с помощью команды spark-submit, менеджер YARN не сразу возвращает идентификатор этого приложения Spark. Если скрипт отправляет 20–40 заданий Spark за один раз, DevOps-инженеру приходится вручную связывать идентификатор задания Spark с пакетным заданием. Ситуация становится еще более сложной, когда один и тот же скрипт запуска заданий Spark вызывается несколько раз для разных стран или бизнес-сегментов.
Наконец, сами скрипты подвержены ошибкам, т.к. логика их работы обычно не тестируется так тщательно, как сами Spark-приложения, для управления которыми написаны скрипты. Поэтому вместо оркестрации Spark-приложений с помощью shell-скриптов можно перейти к хореографии с помощью EDA-архитектуры, управляемой событиями (Event Driven Architecture).
EDA-архитектура повышает устойчивость микросервисной системы за счет слабой связи компонентов и асинхронного характера их взаимодействия. Кроме того, хореография микросервисов с EDA хорошо подходит для случаев, если количество заданий и конфигурация каждого из них часто меняются, и оркестрировать их с помощью того же Apache Airflow не очень удобно.
Заменить shell-скрипты управления Spark-заданиями можно следующими компонентами микросервисной EDA-архитектуры:
- Apache Kafka для публикации и потребления событий;
- Apache Livy как REST API для отправки заданий в кластер Spark;
- микросервисы планирования заданий Spark, проверки качества данных, сгенерированных заданием Spark после его завершения, и проверки состояния заданий.
- контейнерная платформа для размещения микросервисов, которая обеспечивает централизованное ведение журналов, автоматическую масштабируемость и отказоустойчивость. Например, это может быть Pivotal Cloud Foundry (PCF).
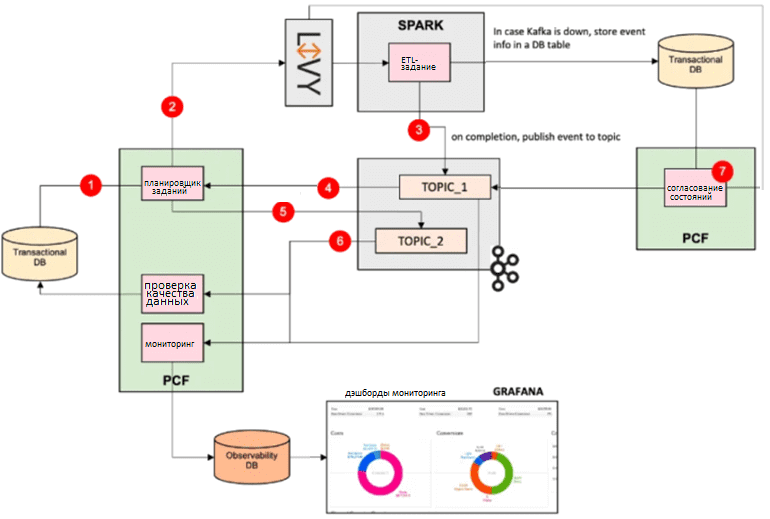
Представленная EDA-архитектура работает следующим образом:
- микросервис планировщика заданий оценивает, какое задание должно быть отправлено в кластер. Информация о метаданных всех заданий хранится в базе данных транзакций.
- микросервис Job Scheduler отправляет задание Spark через Livy и обновляет состояния сущностей, которые необходимо отслеживать, в транзакционной базе данных.
- задание Spark завершается и публикует событие в топике Kafka под названием TOPIC Если событие не может быть опубликовано в Kafka, информация о нем записывается в базу данных транзакций.
- микросервис планировщика заданий получает событие из TOPIC_1, обновляет состояние сущностей в базе данных транзакций и отправляет следующие подходящие задания Spark в удаленный кластер через Livy.
- микросервис планировщика заданий публикует новое событие в TOPIC_2, которое включает обновленное состояние задания, ранее полученного из TOPIC
- микросервис проверки качества данных использует событие из TOPIC_2, обновляя таблицы в базе данных транзакций.
- микросервис State Reconciler периодически проверяет состояния в базе данных транзакций. Если какое-либо событие сохраняется в базе данных из-за недоступности Kafka, то служба согласования повторит попытки публикации.
При реализации этих шагов возникает проблема обновления состояния сущностей в базе данных, создания нового события для публикации в топике Kafka и вызова службы Livy для отправки задания. Это связано со сквозным характером транзакции. Например, если микросервис планировщика заданий может обновить состояния сущностей в базе данных, но не может опубликовать новое событие Kafka в TOPIC_2, то обновления необходимо отменить. Если новое событие успешно создается в Kafka, то обновления базы данных должны быть зафиксированы. Потребители событий должны быть идемпотентными, т.е. достаточно надежными, если событие доставляется повторно из-за задержек обработки события. Справиться с этими проблемами помогут паттерны микросервисной архитектуры под названием Idempotent Consumer и Transactional Outbox. Что они собой представляют, рассмотрим далее.
Подходящие паттерны микросервисной архитектуры для EDA
В EDA-архитектуре рекомендуется использовать брокер сообщений, гарантирующий хотя бы однократную доставку (at least once). Это означает, что брокер сообщений доставит сообщение потребителю хотя бы 1 раз, даже если возникнут ошибки. Побочным эффектом этой гарантии является риск дублирования данных: потребитель может вызываться повторно для одного и того же сообщения. Избежать этого поможет идемпотентность потребителя, чтобы результат многократной обработки одного и того же сообщения был таким же, как и при однократной обработке. Если потребитель не является идемпотентным, множественные вызовы могут вызвать ошибки, например, некорректные вычисления.
Реализовать шаблон Idempotent Consumer можно, записав в базу данных идентификаторы сообщений, которые потребитель уже успешно обработало. При обработке сообщения потребитель может обнаруживать и удалять дубликаты, запрашивая базу данных. Для этого потребитель может использовать отдельную таблицу PROCESSED_MESSAGES или сохранять идентификаторы в бизнес-сущностях, которые он меняет, т.е. создает или обновляет.
Паттерн Transactional Outbox, также известный под названием Application events используется, когда нужно обновить базу данных и отправить сообщения об этом. Например, сервис публикует события и атомарно обновляет данные в базе, чтобы избежать несоответствий и ошибок. Из-за недостатков протокола двухфазной фиксации, о которых мы писали здесь, приходится искать другие механизмы реализации распределенной транзакции. При этом отправка сообщения в середине транзакции ненадежна и нет никакой гарантии, что транзакция будет совершена. Аналогично, если сервис отправляет сообщение после фиксации транзакции, нет гарантии, что он не выйдет из строя до отправки сообщения.
Поскольку события должны отправляться брокеру сообщений в том порядке, в котором они произошли и были отправлены сервисом-продюсером, возникает задача надежного и атомарного обновления базы данных и отправки сообщений о событии. Для этого сервис, использующий реляционную базу данных, может записывать туда события в таблицу исходящих сообщений как часть локальной транзакции. А сервис, использующий NoSQL-СУБД, добавляет сообщения к атрибуту обновляемой записи. Отдельный процесс ретрансляции сообщений публикует события, вставленные в базу данных, в брокер сообщений. Подробнее об этом мы писали здесь.
Таким образом, сообщения гарантированно отправляются тогда и только тогда, когда транзакция базы данных фиксируется, и в том порядке, в котором они были отправлены приложением. Но этот шаблон требует обязательной публикации сообщения после обновления базы данных. Также нужна идемпотентность приложения-потребителя, поскольку брокер сообщений может доставлять сообщения более одного раза.
Возвращаясь к управлению Spark-приложений по принципам EDA-архитектуры, отметим, что в этом случае микросервис планировщика заданий (Job Scheduler) должен обрабатывать несколько вызовов и обновлений, включая обновление состояния сущностей в базе данных, публикацию события в Kafka и планирование других заданий через вызов службы Livy. Поскольку сбои могут произойти в любой момент времени, нужно поддерживать согласованность в конечном итоге. Для этого создания сообщения через вызов API-методов продюсера Kafka, можно сделать запись базы данных методом insertNewEventDetails() в исходящей таблице и использовать границы транзакций базы данных для фиксации транзакции вместе с другими обновлениями. Для асинхронного создания события в топике Kafka подойдет прием сбора измененных данных (CDC, Change Data Capture).
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники