
Продолжая разговор про языки запросов к графовым базам данных, сегодня познакомимся с GSQL, который поддерживается в MPP-СУБД TigerGraph. Как работает эта распределенная NoSQL-база данных и каким образом реализует ACID-требования к транзакциям в операциях с графами.
Архитектура и принципы работы графовой MPP-СУБД
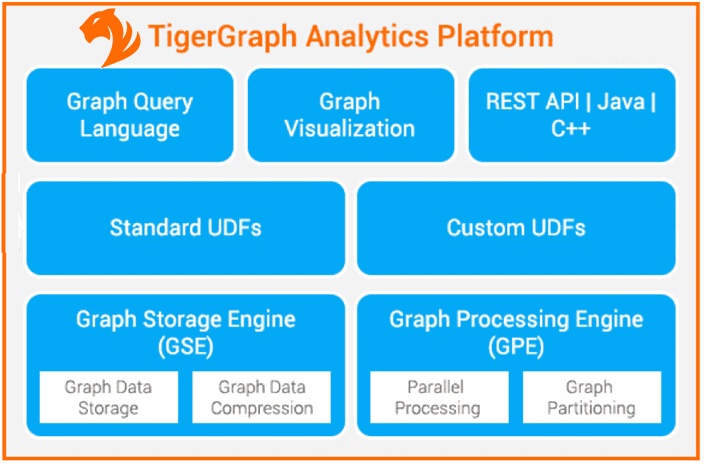
TigerGraph — это распределенное графоориентированное хранилище данных с массивно-параллельной обработкой запросов. Оно отличается от других NoSQL-баз горизонтально масштабируемой архитектурой, которая позволяет поддерживать выполнение рабочих нагрузок на больших графах до сотен миллиардов сущностей и 1 триллиона отношений. TigerGraph поддерживает встроенное параллельное выполнение запросов, повзволяя быстрее исследовать данные, хранящиеся в этой графовой СУБД. Внутренний язык запросов этой MPP-СУБД, GSQL, является декларативным SQL-подобным языком запросов с невысоким порогом входа. Он является полным по Тьюрингу, что означает, что любой запрос может быть выражен с помощью GSQL, в отличие от других подобных языков.
Архитектура TigerGraph включает механизм хранения графов (GSE, Graph Storage Engine), отвечающий за физическое хранение и сжатие данных графа, и механизм обработки графов (GPE, Graph Processing Engine), который предлагает возможности параллельной обработки и разделения графа, что важно для масштабируемости системы.
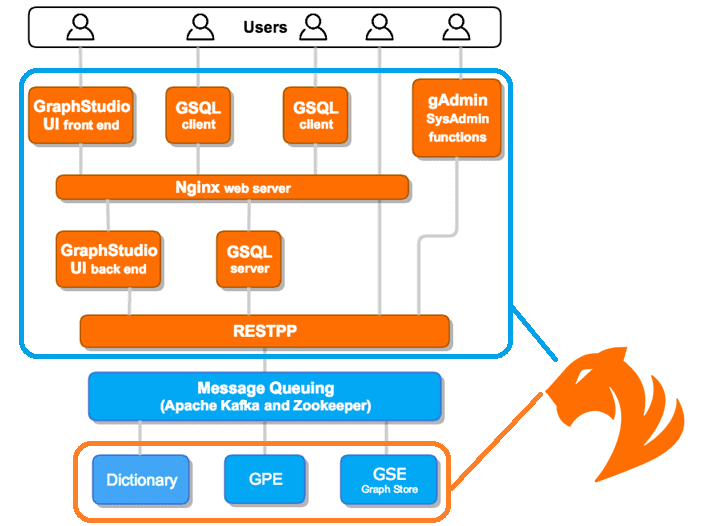
Как и во многих распределенных системах, для координации различных компонентов и синхронизации метаданных в TigerGraph используется Apache Zookeeper, чтобы гарантировать последовательную репликацию данных на серверах. TigerGraph также использует Apache Kafka для распределенной передачи сообщений и создания очередей. Kafka передает сообщения, содержащие данные графа, результаты запросов и другую информацию, между механизмом хранения графов (GSE) и различными экземплярами механизма обработки графов (GPE), обеспечивая высокую скорость надежной и масштабируемой обработки графовых данных.
TigerGraph может быть развернут в облаке, локально или в гибридной инфраструктуре и может интегрировать различные источники данных, например, из экосистемы Hadoop или реляционных СУБД. Для координации действий компонентов используется REST-подход передачи сообщений. В частности, центральное место в управлении задачами занимает RESTPP, усовершенствованный сервер RESTful. Впрочем, пользователи могут взаимодействовать с TigerGraph и другими способами:
- с помощью клиента GSQL – один экземпляр TigerGraph может поддерживать несколько клиентов GSQL на удаленных узлах;
- через GraphStudio – графический пользовательский интерфейс, обеспечивающий большинство основных функций GSQL;
- по RESTPP в рамках интеграционного взаимодействия приложений по REST API;
- утилита gAdmin для системного администрирования.
Модель данных TigerGraph и ACID-транзакции
Как следует из названия, модель данных в TigerGraph ориентирована на ориентированные, неориентированные и взвешенные графы, позволяя моделировать сложные отношения между различными объектами реального мира, представленными в виде узлов, связанных ребрами. Ребра — это ссылки, которые представляют отношения между узлами. В TigerGraph эти структуры данных имеют атрибуты, которые могут быть атомарными, структурированными (имеющими тип кортежа или тип контейнера) или аккумуляторами. Аккумуляторы — это тип атрибута, который хранит количество или сумму определенного значения, что полезно для расчета метрик или статистики по графу или для хранения промежуточных результатов в запросе. Например, аккумуляторы используются для подсчета вхождений значения, сравнения атрибутов со значениями, вычисление среднего значения и других агрегатных функций.
Важным аспектом в оценки любой СУБД является поддержка ACID-транзакций, о чем мы недавно писали здесь. В TigerGraph транзакция представляет собой последовательность операций, которая действует как единая логическая единица работы. Операция только для чтения в TigerGraph не добавляет и не удаляет вершины или ребра, а также не изменяет значения каких-либо атрибутов вершин или ребер, а операция обновления изменяет их, добавляет новые или удаляет существующую вершину/ребро.
TigerGraph обеспечивает полные ACID-транзакции с последовательной согласованностью, определяя их следующим образом:
- каждый GSQL-запрос является транзакцией, в которую может входить несколько операций чтения или записи;
- каждая операция HTTP-запроса REST (GET, POST или DELETE), которая может содержать несколько операций обновления, является транзакцией.
ACID-требования к транзакциям в TigerGraph реализуются так:
- атомарность – транзакция с операциями обновления может вставлять, удалять несколько вершин/ребер или обновлять значения их атрибутов. Такие запросы на обновление выполняются атомарно, применяя либо все изменения успешно, либо не применяя совсем.
- согласованность – TigerGraph обеспечивает традиционную согласованность ACID, когда транзакция может включать правила проверки данных, которые могут гарантировать, что любая транзакция переведет систему из одного допустимого состояния в другое. TigerGraph также обеспечивает последовательную согласованность распределенной системы, когда каждая реплика данных выполняет одни и те же операции в одном и том же порядке. Это одна из самых сильных доступных форм согласованности, более сильная, чем, например, причинная согласованность.
- изоляция – TigerGraph поддерживает уровень изоляции Serializable, самую сильную форму изоляции. Внутри TigerGraph использует MVCC-подход (Multi-Version Concurrency Control) для реализации изоляции. MVCC использует несколько моментальных снимков частей состояния базы данных для поддержки изолированных одновременных операций. В принципе, может быть один моментальный снимок для каждой операции чтения или записи. Транзакция только для чтения R1 не увидит никаких изменений, сделанных незафиксированной транзакцией обновления, независимо от того, была ли эта транзакция обновления отправлена до или после отправки R1 в систему. Несколько одинаковых чтений в одной транзакции T1 дадут одинаковые результаты, даже если есть транзакции обновления, которые изменяют значения атрибутов вершин или ребер, считанные T1 в течение продолжительности T1. Множественные чтения в одной транзакции T1 только для чтения дадут одинаковые результаты, даже если есть транзакции обновления, которые удалили/вставили вершины или ребра, прочитанные T1 в течение продолжительности T1.
- Долговечность – совершенные транзакции записываются на диск SSD или HDD с логированием в журнале опережающей записи (WAL, Write Ahead Log) для обеспечения надежности.
Практическое применение в Data Science и аналитике больших данных
С практической точки зрения графовые алгоритмы часто используются для таких бизнес-задач, как поиск пути, центрирование или ранжирование, кластеризация, обнаружение сообществ, сходство и классификация точек данных. TigerGraph может поддерживать все эти бизнес-приложения аналитики больших данных благодаря своей распределенной природе и массивно-параллельному механизму обработки запросов. Говоря про прикладную Data Science, стоит отметить библиотеку TigerGraph под названием In-Database Graph Data Science (GDS), которая включает более 50 оптимизированных и готовых к использованию GSQL-запросов, каждый из которых реализует стандартный граф или алгоритм машинного обучения, которые могут быть модифицированы пользователем в соответствии с его потребностями.
В заключение отметим некоторые особенно интересные проекты, в которых используется TigerGraph:
- Автомобильный концерн Ford использует Интернет вещей для удаленного управления своим производственным оборудованием по всему миру, которое выполняет множество задач, включая сварку, покраску, сборку и пр. Ранее Ford хранил все эти данные в реляционных СУБД, но рост их объема привел к неоднозначности данных, что чревато простоями производства. Для консолидации данных компания решила использовать TigerGraph. Устранив неоднозначности, корпорация применила алгоритмы сопоставления подобия, чтобы увеличить время безотказной работы своего оборудования, прогнозируя, какие части робота могут выйти из строя, чтобы оперативно заменить их.
- Jaguar Land Rover сократил планирование цепочки поставок с трех недель до 45 минут, с помощью TigerGraph объединяв источники данных и устанавливать связи между ними. Граф, объединяющий 12 отдельных источников данных, эквивалентен 23 реляционным таблицам, охватывающим детали, поставляемые сотнями поставщиков, через спецификацию материалов конкретной модели и конфигурации к последовательности производственной сборки и прогнозу заказов для этих легковые автомобили. Гибкость TigerGraph позволяет автомобильному гиганту быстро отражать изменения в своих непосредственных требованиях к графам, а также обеспечивает возможность расширения в будущем. Запросы по модели цепочки поставок теперь занимают около 45 минут вместо недель или месяцев ранее.
- Бренд видеоигр Xbox от Microsoft, который имеет около 100 миллионов активных пользователей в месяц, с помощью TigerGraph смог улучшить пользовательский опыт своих клиентов через обнаружение закономерностей в данных. Используя алгоритмы PageRank, Community Detection, Shortest Path и Louvain для экспериментов с различными сегментами игрового сообщества, Xbox может точно сегментировать своих клиентов, предлагая им наиболее подходящие продукты.
Чем TigerGraph отличается от открытой графовой СУБД Neo4j, читайте в нашей новой статье.
Познакомиться с современными средствами графовых алгоритмов и лучшими практиками их применения в реальных проектах аналитики больших данных вам помогут специализированные курсы нашего лицензированного учебного центра обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

