 786
786 
Содержание
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming.
Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей
Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности, мы уже рассказывали про гибридную архитектуру Lakehouse, которая сочетает в себе преимущества озер и хранилищ данных, стараясь нивелировать их недостатки. Она сочетает высокую производительность классических хранилищ данных с масштабируемостью, экономичностью и гибкостью озер, чтобы получить максимум возможностей для эффективного хранения и аналитической обработки Big Data с помощью современных технологий.
Исторически подход LakeHouse возник, чтобы устранить недостатки лямбда- и каппа-архитектур, о которых мы писали здесь и здесь. Напомним, холодный путь в лямбда-архитектуре использует методы пакетной обработки данных для обработки входящих данных с заданной частотой, например, ежедневно или раз в час. А горячий путь использует методы потоковой обработки поступающих данных в режиме реального времени. Чтобы реализовать оба пути, Lambda-архитектура включает 3 уровня:
- пакетный уровень для хранения больших данных и агрегаций на них;
- скоростной уровень для агрегирования данных в реальном времени и предоставления представлений для пользовательских запросов к самым свежим данным;
- уровень обслуживания, который действует как база данных, где хранится информация, нужная пользователям при выполнении запросов к пакетному и скоростному уровням.
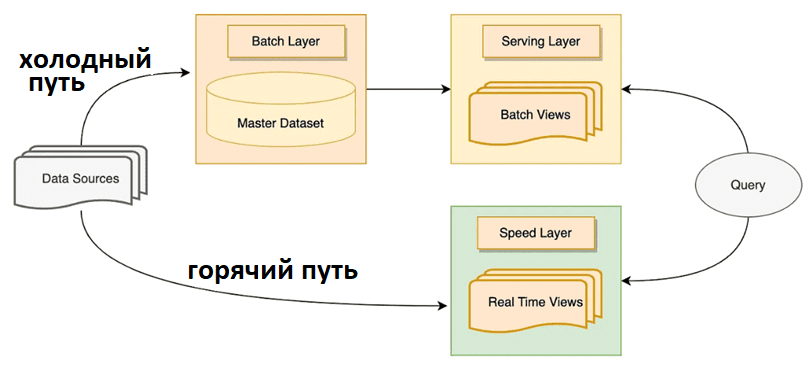
Одной из главных проблем лямбда-архитектуры является ограниченность срока действия данных в представлениях на скоростном уровне. Данные в Speed Layer не являются источником истины, в отличие от пакетного уровня. Если ошибка попадет в данные скоростного уровня, она будет исправлена в конце следующего пакетного анализа на пакетном уровне. Поэтому Speed Layer может хранить денормализованные данные и даже дубли. Проблема заключается в истечении срока действия данных. В конце каждого задания пакетного уровня можно удалить некоторые данные, которые отличить от других, собранных в одних и тех же строках представления. Для управления правильным истечением срока действия данных необходимо постоянно обновлять их, что занимает ресурсы.
У этой проблемы нет элегантного решения, обычно приходится создавать 2 представления вместо одного, вставляя данные, обрабатываемые в Speed Layer, в каждое из двух представлений. Одно из этих двух представлений является текущим, где пользователи делают запросы, а другое — будущим, которое станет текущим, как только данные в текущем представлении будут удалены. Таким образом, данные дублируются и требуют в два раза больше места.
В результате этого качество данных в горячем и холодном пути сильно отличается и требует постоянного согласования, что технически невозможно в Лямбда-архитектуре. Некоторые преобразования, необходимые для интеграции новых данных с существующими, слишком ресурсоемки для выполнения горячем пути.
Еще одним недостатком лямбда-архитектуры является техническая сложность сопровождения, поскольку из-за использования разных технологий горячий и холодный пути внутри одной платформы данных будут иметь разные кодовые базы. Используемая в холодном пути пакетная обработка представляет собой классические ETL-сценарии, регулярно повторяемые с большим объемом данных. Здесь используются реляционные и нереляционные СУБД, файловые системы и/или объектные хранилища для больших объемов данных, а также пакетные оркестраторы типа Apache AirFlow.
А применяемая в горячем пути потоковая обработка в реальном времени представляет собой метод синхронизации данных от источника к получателю с транзакциями в источнике. Данные обрабатываются по мере того, как события происходят в источнике. Этот метод непрерывной обработки происходит по мере того, как данные проходят через систему без принудительных ограничений по времени на вывод. Благодаря почти мгновенному потоку горячий путь не требует хранения больших объемов данных. Здесь используются Apache NiFi, Kafka, Spark Structured Streaming и Flink.
Одной из альтернатив лямбда-архитектуре считается каппа-модель, где отсутствует холодный путь с пакетными технологиями, а все данные проходят через конвейер потоковой обработки. При этом данные хранятся в шине обмена сообщениями, роль которой часто играет Apache Kafka, и когда требуется переиндексация, данные повторно считываются из этого источника. Такое повторное считывание данных для получения правильного представления и стало основным недостатком каппа-архитектуры. Это требует, чтобы потоковые компоненты, включая очереди сообщений, сохраняли значительный объем истории, что снижает их производительность и противоречит их изначальной идее. Поэтому каппа-архитектура не подходит для сценариев с большой долей пакетных данных.
Недостатки лямбда- и каппа-архитектур проложили дорогу новому типу архитектуры под названием Дельта. Подобно каппа, она объединяет пакетные и потоковые данные в одном потоке обработки с одной кодовой базой. Дельта-архитектуру можно рассматривать как легковесное обновление каппа-модели без недостатков лямбда-подхода. Далее рассмотрим технологии ее реализации в LakeHouse.
Архитектура Delta и технологии реализации LakeHouse
Как уже было отмечено выше, лямбда-архитектура почти всегда включает озеро данных для хранения промежуточных данных, постоянное хранилище данных с жесткой схемой, а также временное хранилище для аналитики холодного и горячего пути соответственно. В конфигурации Lakehouse DWH и временное хранилище данных становятся избыточными, поскольку высокоскоростная аналитика может выполняться в самом хранилище озера данных. Благодаря современным механизмам обработки данных, таким как Apache Spark, Flink и Trino, стало возможным объединять пакетные и потоковые данные при сохранении всей логики в одной кодовой базе. Каждый из этих механизмов обработки поддерживает по крайней мере одну из трех популярных реализаций LakeHouse (Hudi, Delta Lake и Iceberg), что делает дельта-архитектуру доступной.
Данные в LakeHouse хранятся в полуструктурированных форматах, но их можно эффективно запрашивать с помощью схемы при чтении, о которой мы писали здесь. Это достигается за счет хранения метаданных поверх файлов в хранилище данных. Эти метаданные в основном содержат прошлые вставки и обновления файлов, а также некоторую форму схемы, которая позволяет механизмам обработки обрабатывать файлы как виртуальные таблицы с помощью стандартных SQL-запросов, как обычные таблицы в DWH.
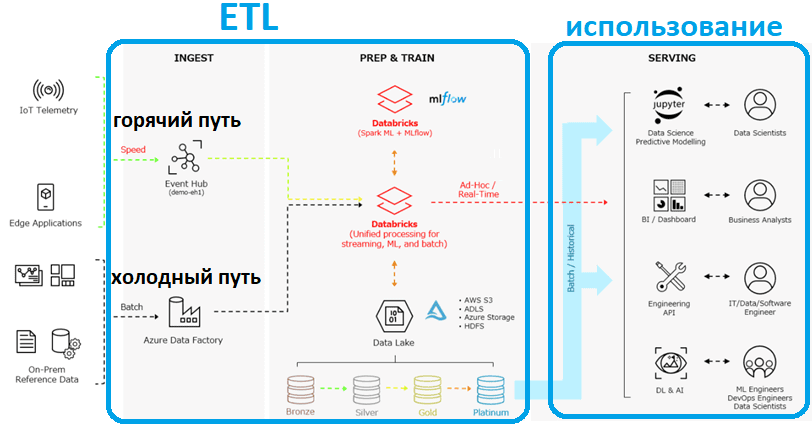
Однако, практическая реализация дельта-архитектуры даже с использованием мощных вычислительных движков не совсем проста. В частности, Apache Spark Structured Streaming поддерживает пакетную и потоковую технологии, позволяя разбивать входящие данные на настраиваемые микропакеты, которые можно обрабатывать с помощью API DataFrame и Dataset. Но при этом надо найти баланс между низкой задержкой и экономической эффективностью обработки большого количества таблиц почти в реальном времени. Для этого при разработке LakeHouse с дельта-архитектурой надо определить следующие требования:
- максимально допустимую задержку обработки данных для каждого из пакетных и потоковых заданий;
- периодичность выполнения пакетных заданий и объем данных, обрабатываемый ими;
- количество структурированных потоков, запускаемых параллельно в одном кластере Apache Spark, необходимое для обновления данных и выполнения заданий пакетной и потоковой обработки.
При развертывании LakeHouse на Delta Lake от Databricks для автоматизации пакетных и потоковых ETL-операций можно использовать Auto Loader – инструмент платформы Databricks, который поэтапно и эффективно обрабатывает новые файлы данных по мере их поступления в облачное хранилище без дополнительной настройки. Auto Loader может загружать файлы разных форматов (JSON, CSV, PARQUET, AVRO, ORC, TEXT и BINARYFILE) из AWS S3 (s3://), Azure Data Lake Storage Gen2 (ADLS Gen2, abfss://), Google Cloud Storage (GCS, gs://), Azure Blob Storage (wasbs:/ /), ADLS Gen1 (adl://) и файловой системы Databricks (DBFS, dbfs:/).
Auto Loader предоставляет источник структурированной потоковой передачи под названием cloudFiles. Учитывая входной путь к каталогу в облачном хранилище файлов, источник cloudFiles автоматически обрабатывает новые файлы по мере их поступления с возможностью обработки существующих файлов в этом каталоге. Auto Loader поддерживает Python и SQL в Delta Live Tables и масштабируется для поддержки загрузки миллионов файлов в час практически в реальном времени.
По мере обнаружения файлов их метаданные сохраняются в масштабируемом хранилище ключей и значений (RocksDB) в контрольной точке конвейера Auto Loader. Это хранилище ключей и значений гарантирует, что данные обрабатываются ровно один раз, согласно семантике exactly once. В случае сбоя Auto Loader может возобновить работу с того места, где он был остановлен, с помощью информации, хранящейся в расположении контрольной точки, и продолжать предоставлять гарантии строго однократной обработки при записи данных в Delta Lake. Про повышение надежности и скорости работы Delta Lake с помощью кэширования мы рассказываем здесь.
Впрочем, Delta Lake от Databricks — не единственная платформа данных категории Lakehouse. Об ее альтернативе под названием Chango на базе распределенного SQL-движка Trino, читайте в нашей новой статье.
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники
- https://blog.devgenius.io/what-is-stream-processing-7fcb561e65d9
- https://medium.com/@axel.westeinde/unifying-batch-and-stream-processing-in-a-data-lakehouse-61fe3441ae48
- https://diawahad.medium.com/big-data-architecture-understanding-the-lambda-architecture-with-detailed-explanation-7ff41522840e
- https://docs.databricks.com/ingestion/auto-loader/index/

