 550
550 
Содержание
Где хранятся состояния операторов в stateful-приложениях Apache Spark Structured Streaming, зачем разработчику нужны данные о состояниях, как их получить и чем для этого полезен новый API State Reader от Databricks.
Хранение состояние в Apache Spark Structured Streaming
В феврале 2024 года компания Databricks выпустила очередную версию Databricks Runtime – среду исполнения для запуска Spark-приложений в рамках своей платформы данных. Databricks Runtime 14.3 включает State Reader API, который позволяет пользователям получать доступ и анализировать внутренние данные о состоянии Structured Streaming, чтобы облегчить разработку, отладку и устранение неполадок stateful-приложений. Apache Spark 4.0.0, выход которого ожидается в 2024 году, будет включать API State Reader. Подробнее о свежем мажорном релизе фреймворка читайте в новой статье.
Как мы уже отмечали здесь, все функции или операторы в Spark Structured Streaming можно разделить на две категории:
- stateless – без сохранения состояния, которые выполняют локальные операции только над данными в пределах текущего микропакета, не нуждаясь в данных из предыдущих микропакетов. Например, фильтрация записей не сохраняет состояние, поскольку не требует дополнительных данных, кроме тех, которые обрабатываются в текущий момент.
- stateful — с сохранением состояния, которые выполняют операции с использованием дополнительных данных помимо тех, что уже есть в текущем микропакете. Например, нужно вычислить скользящее среднее или количество запросов, поступивших из разных городов в течение 5 минут.
Разумеется, чтобы работать с состояниями, их следует где-то хранить. В Spark Structured Streaming они хранятся в хранилище типа key-value с поддержкой версий, которое обеспечивает операции чтения и записи. Это позволяет выполнять stateful-операции с данными из разных пакетов в рамках структурированной потоковой передачи событий. Stateful-операции хранят состояния событий в хранилищах состояний исполнителей, занимая их ресурсы: память и дисковое пространство. Поэтому эффективно поддерживать работу поставщика хранилища состояний в одном и том же исполнителе для разных пакетов потоковой передачи, поскольку изменение местоположения поставщика хранилища состояний требует дополнительных затрат на загрузку состояний с контрольными точками. Накладные расходы на загрузку состояния из контрольной точки зависят от внешнего хранилища и размера состояния, что приводит к снижению задержки при выполнении микропакетов.
Изначально в Apache Spark есть две встроенные реализации провайдера хранилища состояний:
- распределенная файловая система Hadoop (HDFS) — реализация [[StateStoreProvider]] и [[StateStore]] по умолчанию, в которой все данные на первом этапе сохраняются в сопоставлении памяти, а затем сохраняются в файлах в файловой системе, совместимой с HDFS. Все обновления хранилища должны выполняться наборами транзакционно, и каждый набор обновлений увеличивает версию хранилища. Эти версии можно использовать для повторного выполнения обновлений (путем повторных попыток в операциях RDD) в правильной версии хранилища и повторного создания версии хранилища. В реализации HDFSBackedStateStore данные о состоянии хранятся в памяти JVM исполнителей, а большое количество объектов состояния создает нагрузку на память JVM, вызывая большие паузы в работе сборщика мусора (Garbage Collector).
- RocksDB – реализация на основе key-value БД, добавленная в Spark Structured Streaming с версии фреймворка 3.2, чтобы избежать проблем с JVM при множестве ключей для операций с отслеживанием состояния (потоковая агрегация, потоковая передача dropDuulates, соединения, mapGroupsWithState или FlatMapGroupsWithState), когда сборка мусора приостанавливается, вызывая большие различия во времени микропакетной обработки. Вместо того, чтобы хранить состояние в памяти JVM, используется NoSQL-хранилище RocksDB для эффективного управления состоянием в собственной памяти и на локальном диске. Более того, любые изменения этого состояния автоматически сохраняются структурированной потоковой передачей в указанное местоположение контрольной точки, обеспечивая полные гарантии отказоустойчивости. Чтобы использовать RocksDB в качестве хранилища состояний, надо установить конфигурации spark.sql.streaming.stateStore.providerClass значение org.apache.spark.sql.execution.streaming.state.RocksDBStateStoreProvider.
Кроме того, можно реализовать своего собственного провайдера хранилища состояний, расширив интерфейс StateStoreProvider.
Запуск провайдера хранилища состояний на том же исполнителе в запросах Spark Structured Streaming при выполнении stateful-операций основан на функции предпочтительного местоположения RDD. Если в следующем микропакете провайдер хранилища состояний снова будет запланирован на этом исполнителе, он сможет повторно использовать предыдущие состояния и сэкономить время на загрузку состояний с контрольными точками. Однако, иногда Spark планирует задачи для исполнителей, отличных от предпочтительных. В этом случае Spark загрузит поставщиков хранилищ состояний из состояний с контрольными точками на новых исполнителях. При этом провайдеры хранилища состояний, запущенные в предыдущем пакете, не будут выгружены немедленно. Spark запускает задачу обслуживания, которая проверяет и выгружает поставщиков хранилища состояний, которые неактивны на исполнителях. Изменяя конфигурации Spark, связанные с планированием задач, например, spark.locality.wait, можно настроить время ожидания запуска локальной задачи данных. Это позволит провайдерам хранилища состояний работать на одних и тех же исполнителях в разных пакетах при выполнении stateful-операций. В частности, для HDFSBackedStateStore можно проверять метрики хранилища состояний, такие как loadedMapCacheHitCount и loadedMapCacheMissCount. Рекомендуется свести количество пропущенных кэшей к минимуму, чтобы ускорить время загрузки состояния контрольной точки.
Вспомнив, что такое хранилище состояний в Spark Structured Streaming, далее рассмотрим, чем API State Reader от Databricks отличается от текущих решений.
Новый API State Reader от Databricks
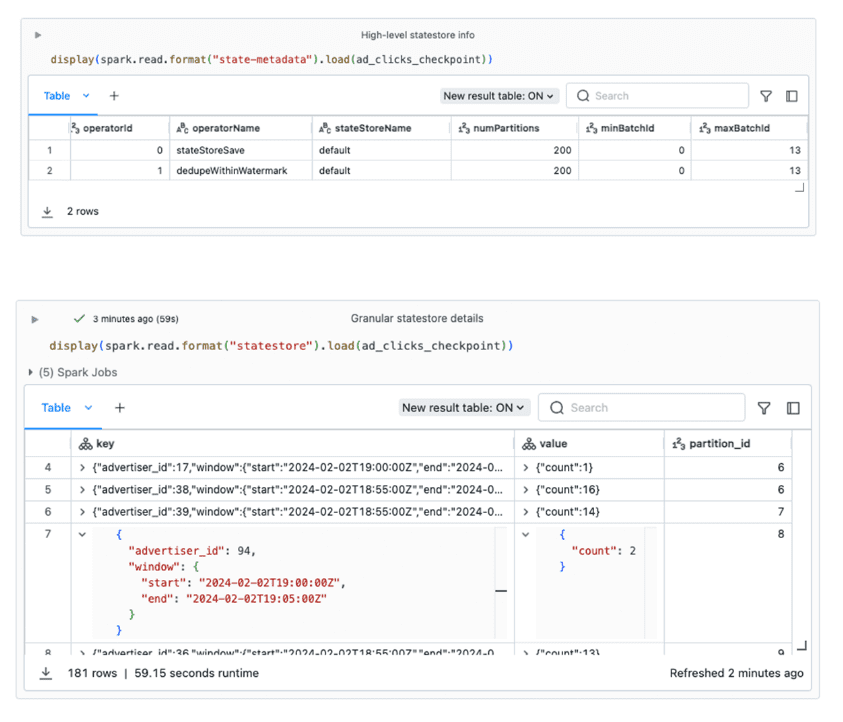
Одна из самых частых трудностей, с которой сталкиваются разработчики stateful-приложений Spark Structured Streaming – это необходимость логирования при разработке и отладке из-за проблем с пониманием хранилища состояний. Это снижает скорость разработки и тестирования. Поэтому Databricks предлагает новый API State Reader, который позволяет запрашивать данные и метаданные о состоянии с помощью форматов state-metadata и statestore. Формат state-metadata предоставляет высокоуровневую информацию о том, что хранится в хранилище состояний, а statestore позволяет детально просматривать сами данные типа ключ-значение. При исследовании производственной проблемы можно начать с формата state-metadata, чтобы получить общее представление об используемых stateful-операторах: какие идентификаторы пакетов задействованы и как данные разделены. Затем можно использовать формат statestore для проверки фактических ключей и значений состояния или для анализа данных состояния.
Для использования обоих форматов необходимо указать путь к контрольной точке __cpLocation, где сохраняются данные хранилища состояний:
- read.format(«state-metadata»).load(«<checkpointLocation>»)
- read.format(«statestore»).load(«<checkpointLocation>»)
Информация из state-metadata поможет обнаружить следующие потенциальные проблемы:
- удержание состояния. В идеале по мере продвижения потока данные о состоянии очищаются автоматически. Однако произвольные stateful-операции, например, FlatMapGroupsWithState, требуют ручных действий разработчика, чтобы он учитывал и кодировал логику удаления или истечения срока действия данных состояния. Если значение минимального идентификатора пакета minBatchId со временем не увеличивается, это может указывать на то, что объем данных о состоянии неограниченно растет, что итоге приведет к ухудшению работы и сбою.
- параллелизм. Значение конфигурации sql.shuffle.partitions по умолчанию равно 200. Это определяет количество экземпляров хранилища состояний, создаваемых в кластере. Для некоторых stateful-нагрузок это не подходит.
Формат statestore позволяет проверять и анализировать детализированные данные о состоянии, включая содержимое ключей и значений, используемых для каждой операции с отслеживанием состояния в базе данных хранилища состояний. Они представлены как выходные структуры датафрейма, которые можно посмотреть в Spark UI. Доступ к этим детализированным данным о состоянии помогает ускорить разработку stateful-конвейера потоковой передачи, устраняя необходимость включения отладочных сообщений в код. Это также полезно для исследования производственных проблем, например, когда нужно посмотреть детали отдельного stateful-оператора, используя его идентификатор operatorId.
В заключение подчеркнем, что API State Reader не предназначен для использования в постоянном контексте, поскольку это не источник потоковой передачи. Однако, он позволяет автоматизировать получение метаданных состояния и их анализ при разработке, тестировании и отладке stateful-приложений.
Узнайте больше про возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Архитектура данных с Apache Spark
[elementor-template id=»13619″]
Источники

