 702
702 
Содержание
3 июня 2024 года вышел предварительный релиз Apache Spark 4.0. Эта версия еще не считается стабильной и предназначена только для ознакомления. Поэтому даже полноценные release notes по ней пока отсутствуют. Тем не менее, сегодня познакомимся с наиболее интересными фичами этого выпуска: новый тип данных VARIANT, API источника данных Python и логи в формате JSON.
Новый тип данных VARIANT
В Apache Spark 4.0 добавлено множество новых интересных функций, включая режим ANSI по умолчанию, источник данных Python, полиморфный Python UDTF, поддержку сортировки строк, новый тип данных VARIANT, источник данных хранилища потокового состояния, структурированное журналирование, Java 17 по умолчанию, и многое другое.
Начнем с нового типа данных VARIANT для работы с полуструктурированными данными. Он намного производительнее и гибче, чем хранение данных в виде строк JSON. Этот тип данных содержит примитив (INT, STRING и другие логические типы данных, разрешенные форматом Parquet), массив (упорядоченный список значений) или объект (неупорядоченная коллекция пар ключ-значение, т.е. строка/вариант). Объект не может содержать повторяющиеся ключи.
Вариант кодируется двумя двоичными значениями: значением и метаданными. Спецификация Variant позволяет представлять полуструктурированные данные (например, JSON) в форме, которую можно эффективно запрашивать по пути. Конструкция предназначена для обеспечения эффективного доступа к вложенным данным даже при наличии очень широких или глубоких структур. Каждое внутреннее значение VARIANT является непрерывным и самодостаточным.
Формат двоичного кодирования обеспечивает более быстрый доступ и навигацию по данным по сравнению со строками. Реализация формата двоичной кодировки Variant упакована в библиотеку с открытым исходным кодом, благодаря чему ее можно использовать в других проектах.
Тип данных VARIANT позволяет сохранить гибкость, поскольку не нужно явно определять схему данных и получить значительно более высокую производительность по сравнению с запросом JSON в виде строки. Это особенно полезно, когда схема данных в формате JSON часто меняется. Например, когда у разных у клиентов есть общие сценарии использования Endpoint Detection & Response (EDR), требующие чтения и объединения журналов, содержащих разные схемы JSON. Аналогичным образом, Variant хорошо подходит для использования, связанного с кликами по рекламе и телеметрией приложений, где схема неизвестна и постоянно меняется. В обоих случаях гибкость типа данных Variant позволяет принимать данные и обеспечивать высокую производительность без необходимости использования явной схемы.
Чтобы преобразовать строку JSON в тип данных VARIANT, нужно использовать функцию parse_json(json_string_column). Это логическая инверсия функции to_json(variant_column), но она отличается тем, что пробелы не сохраняются, порядок ключей произвольный и завершающие нули в числах могут быть усечены. Функция parse_json() возвращает ошибку, если строка JSON имеет неверный формат или превышает ограничение размера типа данных VARIANT. Чтобы избежать ошибки, можно использовать функцию try_parse_json(), которая возвращает NULL при возникновении ошибки на этапе парсинга.
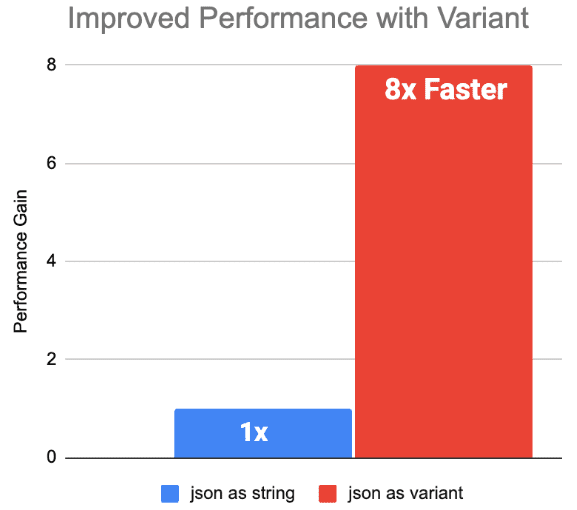
Бенчмаркинговые тесты, проведенные дата-инженерами компании Databricks в среде Databricks Runtime 15.0, для вложенных и плоских схем данных в формате JSON показали, что производительность Variant выше в 8 раз по сравнению со столбцами String.
API источника данных Python
API источника данных Python — это новая функция, представленная в Spark 4.0, позволяющая разработчикам читать из пользовательских источников данных и записывать в пользовательские приемники данных в Python. Чтобы создать собственный источник данных Python, дата-инженеру придется создать собственные подклассы базовых классов DataSource и реализовать необходимые методы для чтения и записи данных.
Определенные пользователем DataSource, DataSourceReader, DataSourceWriter, DataSourceStreamReader и DataSourceStreamWriter, а их методы должны иметь возможность сериализации с помощью формата Pickle. Библиотеку, которая используется внутри метода, необходимо импортировать внутри метода. Например, если планируется использовать контекст при чтении, то TaskContext необходимо импортировать внутри метода read(). После определения источника данных его необходимо зарегистрировать, чтобы использовать в своем пакетной или потоковой обработке данных. Например, в потоковых запросах собственный источник данных Python можно использовать в качестве источника readStream() или приемника writeStream() в Apache Spark Structured Streaming, передав короткое или полное имя в format(). Как это сделать, рассмотрим в следующий раз.
Также в другой статье разберем, чем полезна поддержка полиморфизма в пользовательских табличных функциях Python (UDTF, User Defined Table Function), при котором вызовы UDTF могут динамически вычислять свои выходные схемы в ответ на конкретные аргументы, предоставленные для каждого вызова. В Apache Spark 4.0 это поддерживается также для типов предоставленных входных аргументов и значений любых литеральных скалярных аргументов.
Структурированное логирование в Apache Spark 4.0
Ранее логи Spark представляли собой обычный текст, который не очень удобен для эффективного анализа при отладке. В 4-ой версии фреймворка вместо текстового формата будет использоваться JSON, что сделает логи более понятными. Новые журналы будут включать важные идентификаторы, такие как идентификаторы worker’а, исполнителя, запроса, задания, этапа и задачи, чтобы облегчить поиск и анализ данных. Этот формат позволит пользователям загружать и напрямую запрашивать файлы журналов любых компонентов Spark (драйвера, исполнителя, worker’а и пр.) с помощью Spark SQL для более эффективного решения проблем и анализа. Например, можно отслеживать потери исполнителя или выявлять ошибочные задачи.
Пример JSON-лога в Apache Spark 4.0 может выглядеть так:
{
"ts":"23/11/29 17:53:44",
"level":"ERROR",
"msg":"Fail to know the executor 289 is alive or not",
"context":{
"executor_id":"289"
},
"exception":{
"class":"org.apache.spark.SparkException",
"msg":"Exception thrown in awaitResult",
"stackTrace":"..."
},
"source":"BlockManagerMasterEndpoint"
}
Узнайте больше про возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Архитектура данных с Apache Spark
Источники
- https://spark.apache.org/news/spark-4.0.0-preview1/
- https://www.databricks.com/blog/introducing-open-variant-data-type-delta-lake-and-apache-spark
- https://docs.databricks.com/en/semi-structured/variant-json-diff/
- https://spark.apache.org/docs/4.0.0-preview1/api/python/user_guide/sql/python_data_source/
- https://issues.apache.org/jira/browse/SPARK-47240

