Почему хранить состояния Flink-приложений лучше на локальных SSD-диски, а не на твердотельных накопителях с удаленной файловой системой NFS или HDFS, зачем отключать блочный кэш RocksDB и как настроить параллелизм заданий. Проблемы сохранения состояния в RocksDB и способы их решения Как мы уже упоминали здесь, key-value хранилище RocksDB является самым популярным...
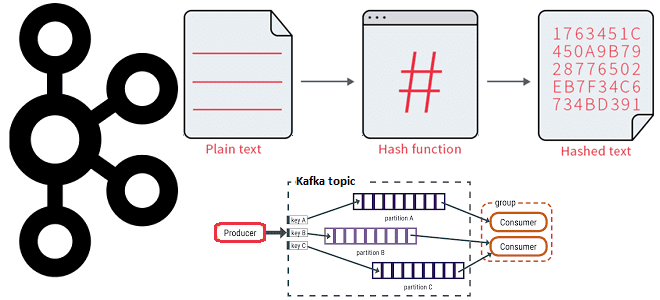
Как работает распределение сообщений по разделам топика Kafka с явно заданным ключом партиционирования и на что влияет язык разработки приложения-продюсера при использовании этой стратегии. 3 стратегии распределения сообщений по разделам в Apache Kafka В Apache Kafka единицей параллелизма выступает раздел топика. Используя несколько разделов, можно распределять нагрузку на брокеров в...

Ранее мы писали про проблемы повышения производительности Apache AirFlow и каковы их причины. В продолжение этой темы сегодня рассмотрим, как настроить этот ETL-оркестратор, чтобы избежать подобных ситуаций и масштабировать кластер в соответствии с нагрузкой. Настройка AirFlow на уровне среды Как мы уже отмечали, Apache AirFlow отлично масштабируется, обеспечивая высокую производительность...
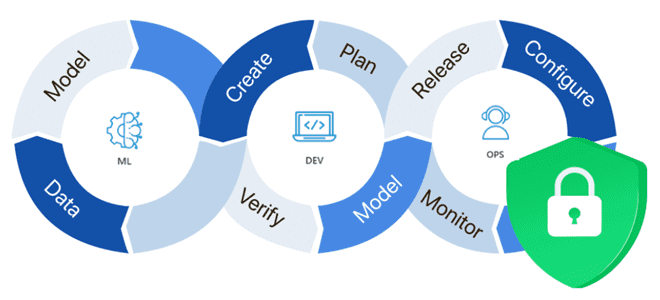
Почему безопасность ML-систем становится все более важным вопросом и как ее обеспечить: MLOps-подходы, практики и технологии защиты данных, моделей машинного обучения, а также вычислительных и инфраструктурных конвейеров. Защита данных для машинного обучения В связи с активным внедрением система машинного обучения в производственное использование, вопрос безопасности становится все более актуальным. ML-системы...
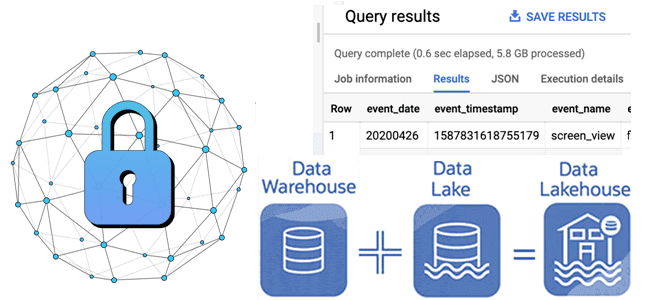
Как отметки времени о событиях в архитектуре данных Lakehouse позволяют обеспечить безопасность Delta Lake: примеры извлечения и преобразования, а также лучшие практики. Почему отметки времени в логах системных событий так важны для архитектуры больших данных Архитектура Lakehouse построена на открытых стандартах и API, которые позволяют сочетать ACID-транзакции и управление данными...

Как управлять средой PySpark-приложения в распределенной вычислительной среде: проблемы зависимостей Python в кластере и способы их решения с помощью сеансов Spark Connect в версии 3.5.0. Управление зависимостями в Python и PySpark Каждый Python-разработчик хотя бы раз сталкивался с проблемой несовместимости пакетов. Эта ситуация называется ад зависимостей (dependency hell), когда вновь...

24 октября 2023 года вышел очередной релиз Apache Flink. Знакомимся с главными новинками популярного Big Data фреймворка для разработки потоковых stateful-приложений: JDBC-драйвер для SQL-шлюза, хранимые процедуры для коннекторов, расширенная поддержка SQL, динамическое масштабирование с REST API и RocksDB, улучшение пакетных операций, а также другие полезные фичи Apache Flink 1.18. Улучшения...
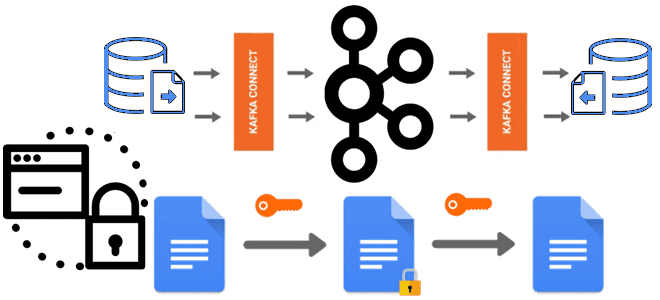
О важности шифрования чувствительных данных, публикуемых в Apache Kafka, мы недавно писали здесь и здесь. В продолжение этой темы сегодня познакомимся с Kryptonite – open-source библиотекой для сквозного шифрования на уровне полей для Apache Kafka Connect. Шифрование данных вне брокеров Apache Kafka: зачем это нужно Apache Kafka поддерживает несколько функций...

Зачем управлять трансферным обучением больших языковых моделей и что входит в это управление: знакомимся с расширением MLOps для LLM под названием LLMOps. Что такое LLMOps Большие языковые модели, воплощенные в генеративных нейросетях (ChatGPT и прочие аналоги), стали главной технологией уходящего года, которая уже активно используется на практике как частными лицами,...
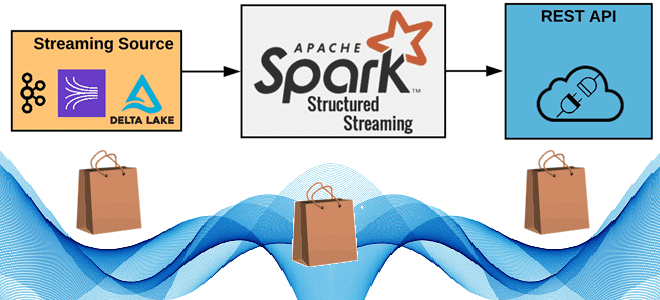
Как реализовать потоковую публикацию данных из приложения Apache Spark Structured Streaming во внешний REST API, используя метод foreachBatch(), зачем перераспределять датафрейм перед его упаковкой в полезную нагрузку HTTP-запроса, от чего зависит число вызовов, и какие приемы помогут избежать сбоев из-за ошибок. 6 шагов потоковой публикации данных в REST API с...
Когда и почему нужно повышать производительность Apache AirFlow, как исполнитель влияет на масштабирование этого ETL-оркестратора. Почему падает производительность AirFlow и что с этим делать Типичными проблемами, которые требуют масштабирования кластера AirFlow, являются медленный доступ к файлам, недостаточный контроль над возможностями DAG, нерегулярные уровни трафика и конкуренция за ресурсы между рабочими...

Что не так с Neosemantics и зачем нужна очередная библиотека для Neo4j: знакомство с Python-пакетом для RDF-графов rdflib-neo4j. Возможности, ограничения и пример использования. Что не так с Neosemantics и зачем нужна очередная библиотека для Neo4j Что такое RDF-графы, триплеты и плагин Neosemantics для работы с этими концепциями в графовой СУБД...

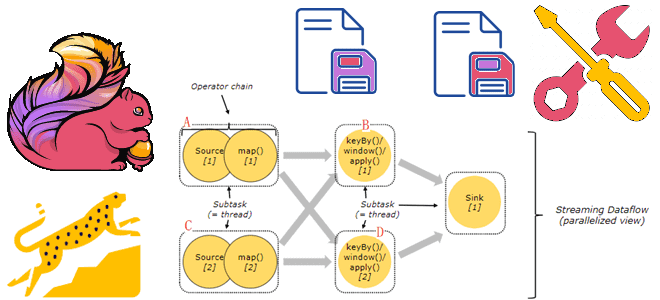
Продолжая недавний разговор про настройку конвейеров из Flink-приложений, сегодня рассмотрим, почему важна локальность данных, как избежать узких мест в приемниках потоковых данных и чем хорош HybridSource для объединения гетерогенных источников. Обеспечьте локальность данных Хотя распределенные системы обладают большим потенциалом по сравнению с локальными, позволяя обрабатывать больше данных, вычисления не происходят...

10 октября 2023 года вышел очередной релиз самой популярной распределенной платформы потоковой передачи событий. Знакомимся с главными новинками Apache Kafka 3.6.0: промышленная поддержка KRaft вместо ZooKeeper, оптимизация транзакций, повышение производительности памяти и другие фичи свежего релиза для разработчика, дата-инженера и администратора. ТОП-10 новинок выпуска 3.6 Apache Kafka 3.6.0 включает 6...
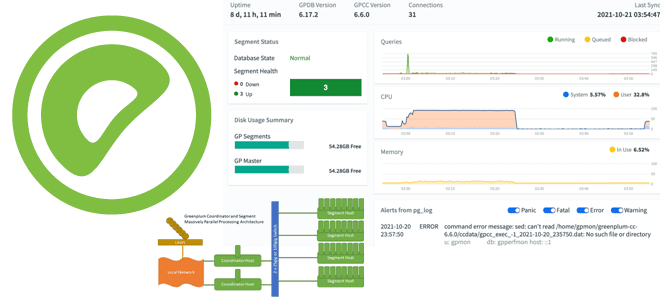
Что такое VMware Greenplum Command Center, как использовать этот инструмент для эффективного управления MPP-СУБД и чем он отличается от Arenadata Command Center для Arenadata DB. Что такое центр управления Greenplum от VMware VMware Greenplum Command Center — это инструмент управления, который отслеживает показатели производительности системы, анализирует состояние кластера и позволяет...

Что представляет собой MLOps-платформа Tecton и как запустить на ней конвейеры машинного обучения, используя провайдер Tecton-AirFlow, чтобы управлять ресурсами Tecton в этом ETL-оркестраторе. Что такое Tecton и при чем здесь MLOps Поскольку концепция MLOps направлена на безбарьерную автоматизацию всех этапов жизненного цикла систем машинного обучения, для этого нужны специализированные средства....
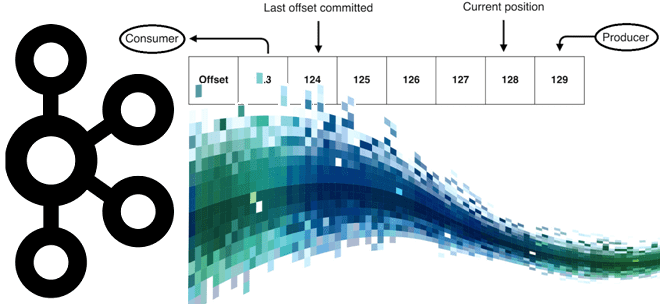
Чем политика сброса смещения earliest отличается от latest в конфигурации auto.offset.reset, зачем устанавливать свойству enable.auto.commit значение false и чем потребитель Java отличается от клиентов на основе librdkafka (C/C++, Python, Go и C#). Конфигурации Apache Kafka для управления смещением Потребитель Apache Kafka — это клиентское приложение, которое подписывается на весь топик...
Для чего разработчику Flink-приложения инструменты профилирования, и почему надо избегать сериализации Kryo и динамической загрузки классов. Используйте инструменты профилирования Разработка и отладка высоконагруженных приложений требует специальных средств, позволяющих понять причины их медленной работы и повысить производительность. Такой анализ работы приложение называется профилированием и выполняется с помощью специальных средств – инструментов...

Продолжая тему недавней статьи про настройки Greenplum 7, сегодня рассмотрим еще несколько конфигураций, которые позволят сделать эту MPP-СУБД еще быстрее и надежнее. Глобальные конфигурации Greenplum для настройки рабочих файлов Параметры глобальной конфигурации пользователя (GUC, Global User Configuration) Greenplum могут быть как глобальными, так и локальными по отношению к экземплярам сегмента. Глобальные...
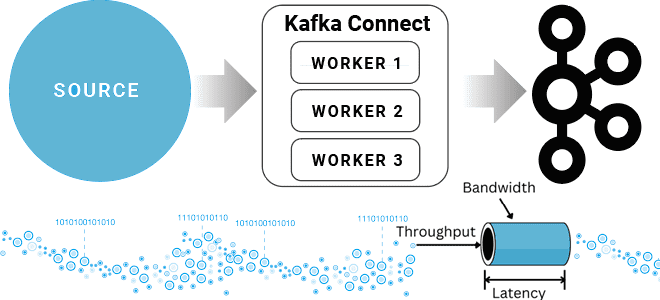
Компоненты платформы Kafka Connect и их настройки для повышения скорости и объема данных, считываемых из внешних источников и публикуемых в топике Kafka. Разбираем на примере JDBC-коннектора для реляционной базы данных. Проблемы и возможности коннекторов Kafka Connect Kafka Connect — это инструмент интеграции данных с открытым исходным кодом, который упрощает процесс...