 669
669 
Содержание
Для чего смотреть планы выполнения запросов при работе с API pandas в Spark и как это сделать: примеры использования метода spark.explain() и его аргументов для вывода логических и физических планов. Разбираем на примере PySpark-скрипта.
API pandas и физический план выполнения запроса в Apache Spark
Мы уже писали, что PySpark, API-интерфейс Python в Apache Spark, позволяет работать с популярной библиотекой pandas, которая довольно известна, но по своей природе не очень хорошо работает с большим объемом данных. Тем не менее, многие аналитики данных и дата-инженеры по-прежнему используют pandas в своих PySpark-приложениях. Чтобы делать это более эффективно, можно попытаться избежать дорогостоящих операций с датафреймами, вызвав метод spark.explain(). Он построит физический план выполнения этой операции, который всегда представляет собой RDD. Если вызвать метод spark.explain() с аргументом True, он также покажет и логический план — краткое изложение всех шагов преобразования, которые необходимо выполнить. Логический план позволяет получить наиболее оптимизированную версию пользовательского выражения, но не предоставляет подробную информацию о драйвере (главном узле) или исполнителе (рабочем узле). За создание и хранение логического плана отвечает SparkContext, который также использует API pandas в Apache Spark.
Посмотрим, как это работает, написав несложный PySpark-скрипт с использованием API pandas для генерации датафрейма с зарплатами по разным специальностям, вычисления медианной зарплаты и фильтрации тех строк, где зарплата оказалась выше медианной. PySpark-скрипт, запускаемый в Colab, выглядит таким образом:
# Установка необходимых библиотек
!pip install pyspark
!pip install faker
# Импорт необходимых модулей из pyspark
import pyspark
from pyspark.sql import SparkSession
import pyspark.pandas as ps
# Импорт модуля faker
from faker import Faker
from faker.providers.address.ru_RU import Provider
#Создаем сессию Spark
spark = SparkSession.builder.getOrCreate()
# Создание объекта Faker с использованием провайдера адресов для России
fake = Faker('ru_RU')
fake.add_provider(Provider)
# Генерируем данные
i=2000
jobs = [fake.job() for _ in range(i)]
salaries = [fake.random_int(min=20, max=720) for _ in range(i)]
# Создаем Spark DataFrame
data = list(zip(jobs, salaries))
Sample_schema = ["job", "salary"]
dataframe = spark.createDataFrame(data, schema = Sample_schema)
# Выводим DataFrame
print('Исходный датафрейм')
dataframe.show(n=10, truncate=False)
# Преобразуем Spark DataFrame в Pandas DataFrame
psdf = ps.DataFrame(dataframe)
# Фильтруем строки, где зарплата выше определенного значения (например, медианы)
median_salary = psdf['salary'].median()
filtered_psdf = psdf[psdf['salary'] > median_salary].sort_values(by=['salary'], ascending=False)
print('Медианная зарплата = ', median_salary)
ps.set_option("display.max_rows", 10)
print('ТОП-10 профессий с зарплатой выше медианной')
display(filtered_psdf)
# Выводим информацию о плане выполнения запроса
filtered_psdf.spark.explain()
Физический план выполнения запроса с датафреймом pandas, вызываемый методом spark.explain() без аргумента True, выглядит так:
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Project [__index_level_0__#2254L, job#2239, salary#2240L]
+- Sort [salary#2240L DESC NULLS LAST, __natural_order__#2301L ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(salary#2240L DESC NULLS LAST, __natural_order__#2301L ASC NULLS FIRST, 200), ENSURE_REQUIREMENTS, [plan_id=2697]
+- Project [distributed_sequence_id#2255L AS __index_level_0__#2254L, job#2239, salary#2240L, monotonically_increasing_id() AS __natural_order__#2301L]
+- Filter CASE WHEN CASE WHEN CASE WHEN isnull(cast(salary#2240L as double)) THEN false ELSE isnull(cast(salary#2240L as double)) END THEN false ELSE CASE WHEN isnull(cast(salary#2240L as double)) THEN false ELSE isnull(cast(salary#2240L as double)) END END THEN false ELSE CASE WHEN CASE WHEN isnull(cast(salary#2240L as double)) THEN false ELSE isnull(cast(salary#2240L as double)) END THEN false ELSE CASE WHEN isnull(cast(salary#2240L as double)) THEN false ELSE (cast(salary#2240L as double) > 366.0) END END END
+- AttachDistributedSequence[distributed_sequence_id#2255L, job#2239, salary#2240L] Index: distributed_sequence_id#2255L
+- Scan ExistingRDD[job#2239,salary#2240L]
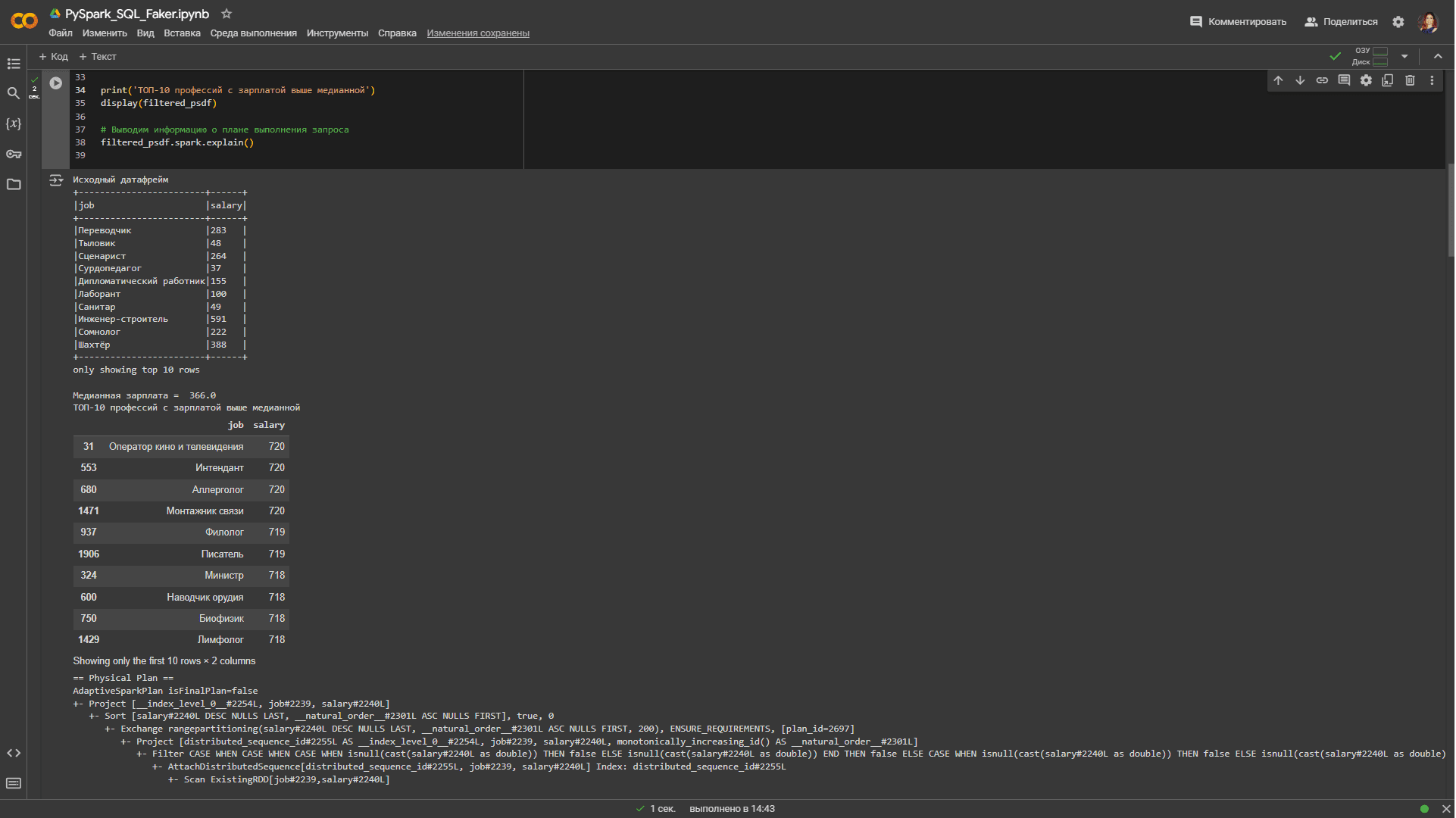
Некоторые операции, например, sort_values(), сложнее выполнять в параллельной или распределенной среде, чем в памяти на одном компьютере, поскольку необходимо отправлять данные на другие узлы через сеть. Об этом свидетельствует операция Exchange в плане выполнения запросов. По возможности рекомендуется избегать таких shuffle-операций, поскольку они замедляют вычисления из-за накладных расходов передачи данных по сети.
Логический план выполнения запроса
При вызове метода spark.explain() с аргументом True, выводимая информация будет намного полнее. Теперь она включает не только физический план, но и логический план, причем все стадии работы с ним: от синтаксического анализа до оптимизации перед генерацией физического плана.
== Parsed Logical Plan ==
Project [__index_level_0__#2351L, job#2336, salary#2337L]
+- Project [__index_level_0__#2351L, job#2336, salary#2337L, monotonically_increasing_id() AS __natural_order__#2410L]
+- Project [__index_level_0__#2351L, job#2336, salary#2337L]
+- Sort [salary#2337L DESC NULLS LAST, __natural_order__#2398L ASC NULLS FIRST], true
+- Project [__index_level_0__#2351L, job#2336, salary#2337L, __natural_order__#2398L]
+- Project [__index_level_0__#2351L, job#2336, salary#2337L, monotonically_increasing_id() AS __natural_order__#2398L]
+- Project [__index_level_0__#2351L, job#2336, salary#2337L]
+- Filter CASE WHEN isnull(CASE WHEN isnull(CASE WHEN isnull((cast(salary#2337L as double) > 364.0)) THEN false ELSE (cast(salary#2337L as double) > 364.0) END) THEN false ELSE CASE WHEN isnull((cast(salary#2337L as double) > 364.0)) THEN false ELSE (cast(salary#2337L as double) > 364.0) END END) THEN false ELSE cast(CASE WHEN isnull(CASE WHEN isnull((cast(salary#2337L as double) > 364.0)) THEN false ELSE (cast(salary#2337L as double) > 364.0) END) THEN false ELSE CASE WHEN isnull((cast(salary#2337L as double) > 364.0)) THEN false ELSE (cast(salary#2337L as double) > 364.0) END END as boolean) END
+- Project [__index_level_0__#2351L, job#2336, salary#2337L, monotonically_increasing_id() AS __natural_order__#2356L]
+- Project [__index_level_0__#2351L, job#2336, salary#2337L]
+- Project [distributed_sequence_id#2352L AS __index_level_0__#2351L, job#2336, salary#2337L]
+- AttachDistributedSequence[distributed_sequence_id#2352L, job#2336, salary#2337L] Index: distributed_sequence_id#2352L
+- LogicalRDD [job#2336, salary#2337L], false
== Analyzed Logical Plan ==
__index_level_0__: bigint, job: string, salary: bigint
Project [__index_level_0__#2351L, job#2336, salary#2337L]
+- Project [__index_level_0__#2351L, job#2336, salary#2337L, monotonically_increasing_id() AS __natural_order__#2410L]
+- Project [__index_level_0__#2351L, job#2336, salary#2337L]
+- Sort [salary#2337L DESC NULLS LAST, __natural_order__#2398L ASC NULLS FIRST], true
+- Project [__index_level_0__#2351L, job#2336, salary#2337L, __natural_order__#2398L]
+- Project [__index_level_0__#2351L, job#2336, salary#2337L, monotonically_increasing_id() AS __natural_order__#2398L]
+- Project [__index_level_0__#2351L, job#2336, salary#2337L]
+- Filter CASE WHEN isnull(CASE WHEN isnull(CASE WHEN isnull((cast(salary#2337L as double) > 364.0)) THEN false ELSE (cast(salary#2337L as double) > 364.0) END) THEN false ELSE CASE WHEN isnull((cast(salary#2337L as double) > 364.0)) THEN false ELSE (cast(salary#2337L as double) > 364.0) END END) THEN false ELSE cast(CASE WHEN isnull(CASE WHEN isnull((cast(salary#2337L as double) > 364.0)) THEN false ELSE (cast(salary#2337L as double) > 364.0) END) THEN false ELSE CASE WHEN isnull((cast(salary#2337L as double) > 364.0)) THEN false ELSE (cast(salary#2337L as double) > 364.0) END END as boolean) END
+- Project [__index_level_0__#2351L, job#2336, salary#2337L, monotonically_increasing_id() AS __natural_order__#2356L]
+- Project [__index_level_0__#2351L, job#2336, salary#2337L]
+- Project [distributed_sequence_id#2352L AS __index_level_0__#2351L, job#2336, salary#2337L]
+- AttachDistributedSequence[distributed_sequence_id#2352L, job#2336, salary#2337L] Index: distributed_sequence_id#2352L
+- LogicalRDD [job#2336, salary#2337L], false
== Optimized Logical Plan ==
Project [__index_level_0__#2351L, job#2336, salary#2337L]
+- Sort [salary#2337L DESC NULLS LAST, __natural_order__#2398L ASC NULLS FIRST], true
+- Project [distributed_sequence_id#2352L AS __index_level_0__#2351L, job#2336, salary#2337L, monotonically_increasing_id() AS __natural_order__#2398L]
+- Filter CASE WHEN CASE WHEN CASE WHEN isnull(cast(salary#2337L as double)) THEN false ELSE isnull(cast(salary#2337L as double)) END THEN false ELSE CASE WHEN isnull(cast(salary#2337L as double)) THEN false ELSE isnull(cast(salary#2337L as double)) END END THEN false ELSE CASE WHEN CASE WHEN isnull(cast(salary#2337L as double)) THEN false ELSE isnull(cast(salary#2337L as double)) END THEN false ELSE CASE WHEN isnull(cast(salary#2337L as double)) THEN false ELSE (cast(salary#2337L as double) > 364.0) END END END
+- AttachDistributedSequence[distributed_sequence_id#2352L, job#2336, salary#2337L] Index: distributed_sequence_id#2352L
+- LogicalRDD [job#2336, salary#2337L], false
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Project [__index_level_0__#2351L, job#2336, salary#2337L]
+- Sort [salary#2337L DESC NULLS LAST, __natural_order__#2398L ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(salary#2337L DESC NULLS LAST, __natural_order__#2398L ASC NULLS FIRST, 200), ENSURE_REQUIREMENTS, [plan_id=2794]
+- Project [distributed_sequence_id#2352L AS __index_level_0__#2351L, job#2336, salary#2337L, monotonically_increasing_id() AS __natural_order__#2398L]
+- Filter CASE WHEN CASE WHEN CASE WHEN isnull(cast(salary#2337L as double)) THEN false ELSE isnull(cast(salary#2337L as double)) END THEN false ELSE CASE WHEN isnull(cast(salary#2337L as double)) THEN false ELSE isnull(cast(salary#2337L as double)) END END THEN false ELSE CASE WHEN CASE WHEN isnull(cast(salary#2337L as double)) THEN false ELSE isnull(cast(salary#2337L as double)) END THEN false ELSE CASE WHEN isnull(cast(salary#2337L as double)) THEN false ELSE (cast(salary#2337L as double) > 364.0) END END END
+- AttachDistributedSequence[distributed_sequence_id#2352L, job#2336, salary#2337L] Index: distributed_sequence_id#2352L
+- Scan ExistingRDD[job#2336,salary#2337L]
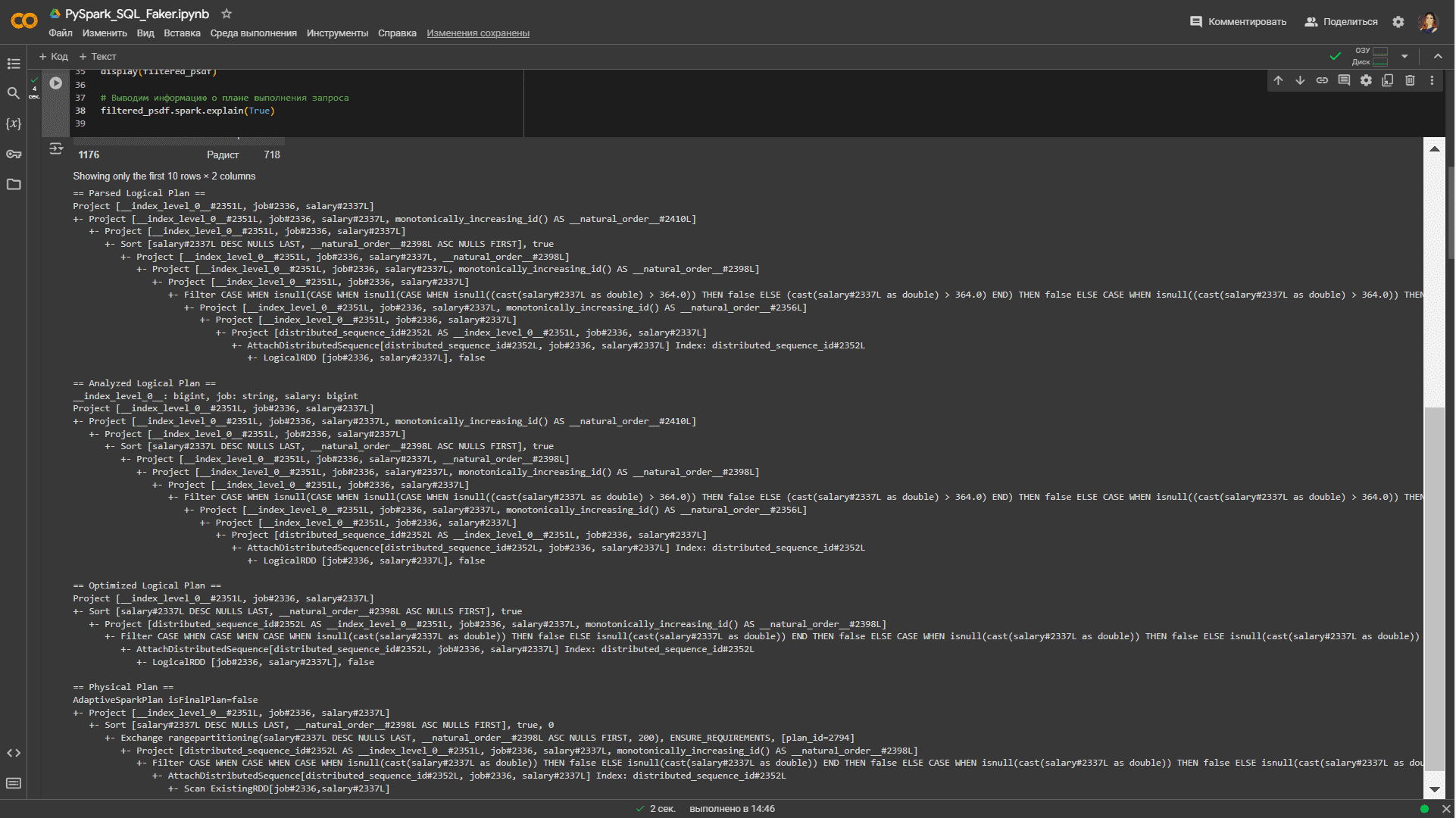
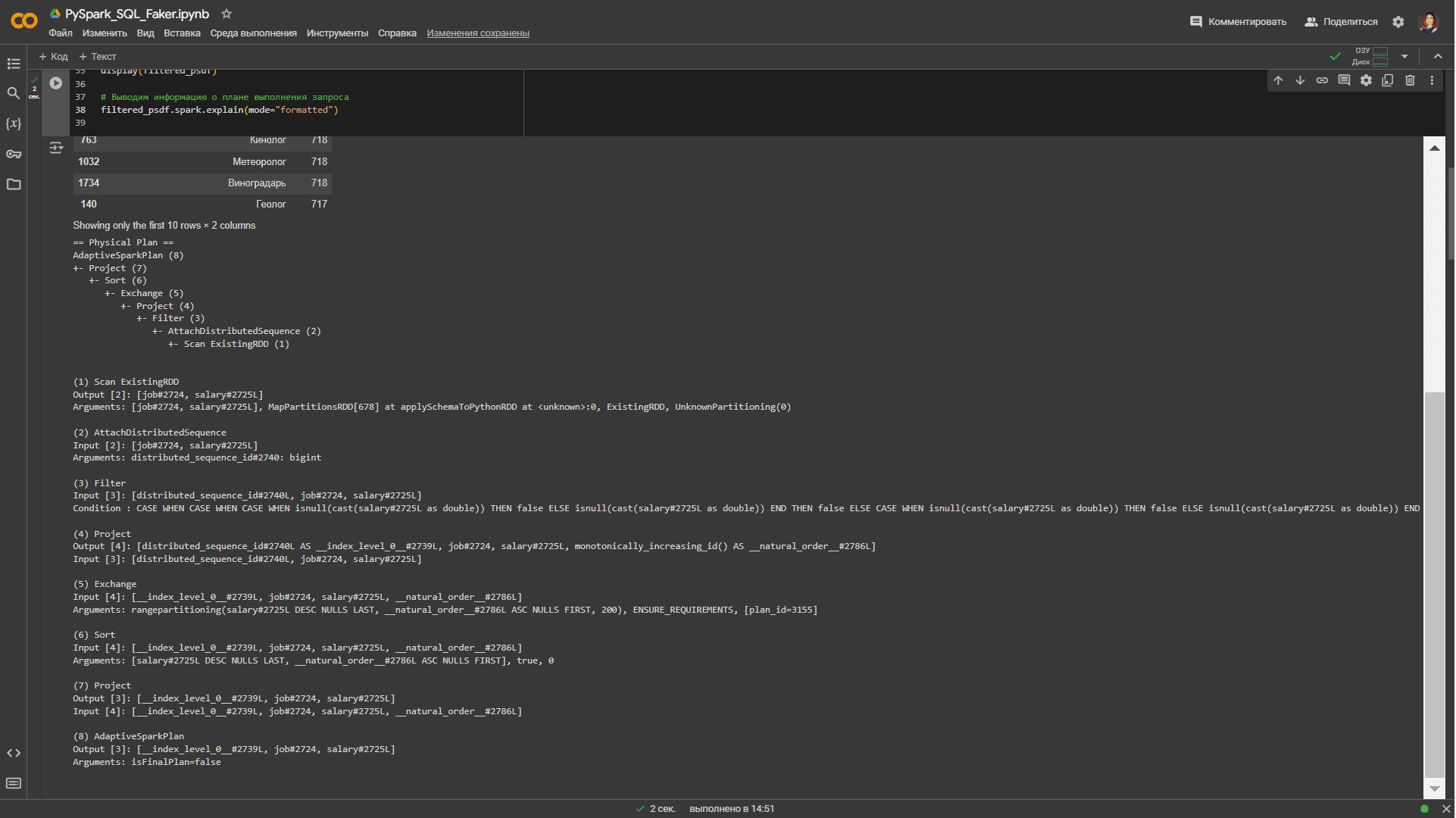
Вместо аргумента True в методе spark.explain() можно использовать аргумент mode=»extended«, который также выводит логические и физические планы выполнения запроса. А аргумент mode=»formatted» показывает разделенный вывод, созданный на основе оптимизированного физического плана, и раздел с деталями каждого узла:
== Physical Plan ==
AdaptiveSparkPlan (8)
+- Project (7)
+- Sort (6)
+- Exchange (5)
+- Project (4)
+- Filter (3)
+- AttachDistributedSequence (2)
+- Scan ExistingRDD (1)
(1) Scan ExistingRDD
Output [2]: [job#2724, salary#2725L]
Arguments: [job#2724, salary#2725L], MapPartitionsRDD[678] at applySchemaToPythonRDD at <unknown>:0, ExistingRDD, UnknownPartitioning(0)
(2) AttachDistributedSequence
Input [2]: [job#2724, salary#2725L]
Arguments: distributed_sequence_id#2740: bigint
(3) Filter
Input [3]: [distributed_sequence_id#2740L, job#2724, salary#2725L]
Condition : CASE WHEN CASE WHEN CASE WHEN isnull(cast(salary#2725L as double)) THEN false ELSE isnull(cast(salary#2725L as double)) END THEN false ELSE CASE WHEN isnull(cast(salary#2725L as double)) THEN false ELSE isnull(cast(salary#2725L as double)) END END THEN false ELSE CASE WHEN CASE WHEN isnull(cast(salary#2725L as double)) THEN false ELSE isnull(cast(salary#2725L as double)) END THEN false ELSE CASE WHEN isnull(cast(salary#2725L as double)) THEN false ELSE (cast(salary#2725L as double) > 379.0) END END END
(4) Project
Output [4]: [distributed_sequence_id#2740L AS __index_level_0__#2739L, job#2724, salary#2725L, monotonically_increasing_id() AS __natural_order__#2786L]
Input [3]: [distributed_sequence_id#2740L, job#2724, salary#2725L]
(5) Exchange
Input [4]: [__index_level_0__#2739L, job#2724, salary#2725L, __natural_order__#2786L]
Arguments: rangepartitioning(salary#2725L DESC NULLS LAST, __natural_order__#2786L ASC NULLS FIRST, 200), ENSURE_REQUIREMENTS, [plan_id=3155]
(6) Sort
Input [4]: [__index_level_0__#2739L, job#2724, salary#2725L, __natural_order__#2786L]
Arguments: [salary#2725L DESC NULLS LAST, __natural_order__#2786L ASC NULLS FIRST], true, 0
(7) Project
Output [3]: [__index_level_0__#2739L, job#2724, salary#2725L]
Input [4]: [__index_level_0__#2739L, job#2724, salary#2725L, __natural_order__#2786L]
(8) AdaptiveSparkPlan
Output [3]: [__index_level_0__#2739L, job#2724, salary#2725L]
Arguments: isFinalPlan=false
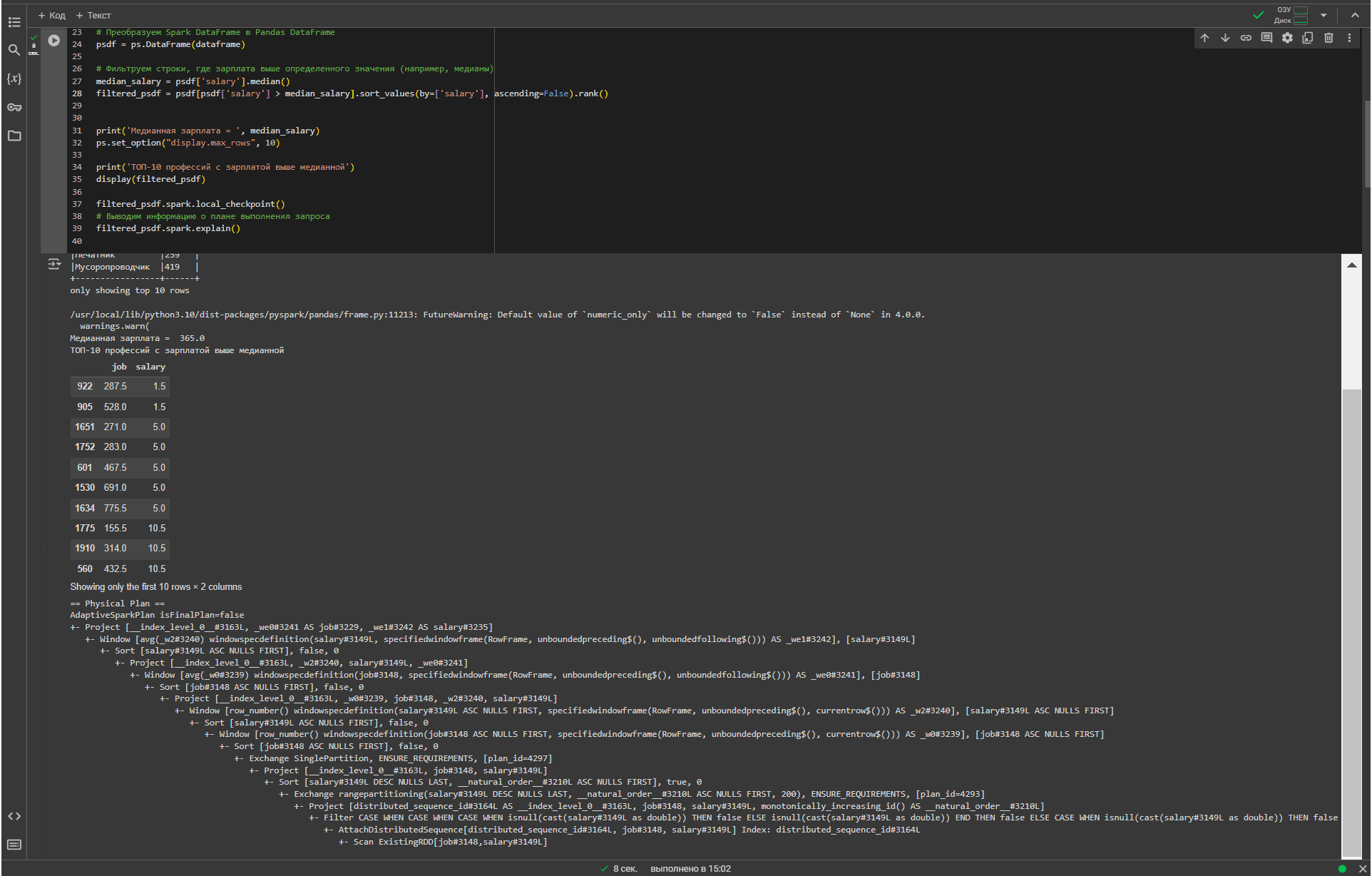
Когда над объектами Spark вызывается много операций API pandas, базовый планировщик фреймворка может замедлиться из-за огромного и сложного плана. В таком случае можно вызвать метод работы с контрольной точкой DataFrame.spark.checkpoint() или DataFrame.spark.local_checkpoint(), который удалит предыдущий план выполнения и построит его заново в более простом варианте. Результат предыдущего DataFrame сохраняется в настроенной файловой системе при вызове DataFrame.spark.checkpoint() или в исполнителе при вызове DataFrame.spark.local_checkpoint().
Поскольку в Apache Spark раздел является единицей параллелизма, рекомендуется избегать вычислений на одном разделе. Однако, некоторые API, такие как DataFrame.rank, используют оконные функции PySpark без указания раздела. Это перемещает все данные в один раздел на одном узле и может привести к серьезному снижению производительности. Таких API следует избегать для очень больших наборов данных. Например, добавим к фильтрации профессий с зарплатой выше медианной функцию rank() и посмотрим, как это отразится на физическом плане выполнения запроса.
В физическом плане появилась оконная функция, а сам он теперь выглядит так:
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Project [__index_level_0__#3163L, _we0#3241 AS job#3229, _we1#3242 AS salary#3235]
+- Window [avg(_w2#3240) windowspecdefinition(salary#3149L, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS _we1#3242], [salary#3149L]
+- Sort [salary#3149L ASC NULLS FIRST], false, 0
+- Project [__index_level_0__#3163L, _w2#3240, salary#3149L, _we0#3241]
+- Window [avg(_w0#3239) windowspecdefinition(job#3148, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS _we0#3241], [job#3148]
+- Sort [job#3148 ASC NULLS FIRST], false, 0
+- Project [__index_level_0__#3163L, _w0#3239, job#3148, _w2#3240, salary#3149L]
+- Window [row_number() windowspecdefinition(salary#3149L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS _w2#3240], [salary#3149L ASC NULLS FIRST]
+- Sort [salary#3149L ASC NULLS FIRST], false, 0
+- Window [row_number() windowspecdefinition(job#3148 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS _w0#3239], [job#3148 ASC NULLS FIRST]
+- Sort [job#3148 ASC NULLS FIRST], false, 0
+- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=4297]
+- Project [__index_level_0__#3163L, job#3148, salary#3149L]
+- Sort [salary#3149L DESC NULLS LAST, __natural_order__#3210L ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(salary#3149L DESC NULLS LAST, __natural_order__#3210L ASC NULLS FIRST, 200), ENSURE_REQUIREMENTS, [plan_id=4293]
+- Project [distributed_sequence_id#3164L AS __index_level_0__#3163L, job#3148, salary#3149L, monotonically_increasing_id() AS __natural_order__#3210L]
+- Filter CASE WHEN CASE WHEN CASE WHEN isnull(cast(salary#3149L as double)) THEN false ELSE isnull(cast(salary#3149L as double)) END THEN false ELSE CASE WHEN isnull(cast(salary#3149L as double)) THEN false ELSE isnull(cast(salary#3149L as double)) END END THEN false ELSE CASE WHEN CASE WHEN isnull(cast(salary#3149L as double)) THEN false ELSE isnull(cast(salary#3149L as double)) END THEN false ELSE CASE WHEN isnull(cast(salary#3149L as double)) THEN false ELSE (cast(salary#3149L as double) > 365.0) END END END
+- AttachDistributedSequence[distributed_sequence_id#3164L, job#3148, salary#3149L] Index: distributed_sequence_id#3164L
+- Scan ExistingRDD[job#3148,salary#3149L]
Чтобы rank() не замедлял работу распределенной программы, перемещая данные в один раздел, можно использовать метод groupBy.rank, который менее затратен, поскольку данные можно распределять и вычислять для каждой группы. В ранее приведенном примере нет явно выделяемых групп, поэтому оставим этот совет без иллюстрации.
Узнайте больше про возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Архитектура данных с Apache Spark
Источники

