Что такое Databricks SQL и как его ускорить, используя кэширование данных: типы хранилищ данных в платформе Lakehouse и виды кэшей. Что такое Databricks SQL Платформа Databricks Lakehouse предоставляет комплексное решение для хранения данных. Она построена на открытых стандартах и API. Эта архитектура данных сочетает ACID-транзакции и управление данными корпоративных хранилищ...
Зачем настраивать конфигурацию конвейера Flink-приложений в зависимости от рабочей нагрузки и как это сделать: примеры и рекомендации. 3 вида рабочей нагрузки в потоковых конвейерах Конвейер потоковой передачи событий может реализовывать различные сценарии: обратная засыпка (backfilling), когда конвейер потребляет все исторические данные, считывая все сообщения, доступные во входных источниках, пока не...
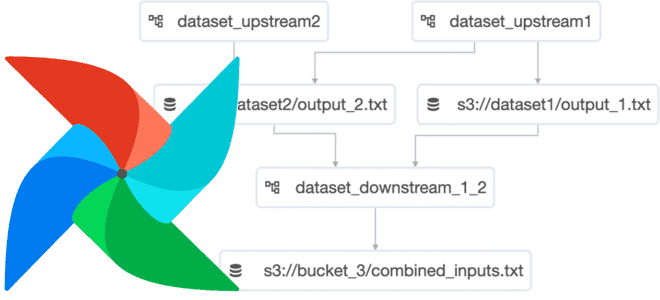
Что такое набор данных в Apache AirFlow и как эта концепция обмена данными между задачами разных DAG улучшает управляемость ETL-конвейера и повышает производительность фреймворка. Что такое набор данных в Apache AirFlow и где это использовать Набор данных (Dataset) – это замена логической группировки данных в Apache AirFlow. Наборы данных могут...

Что настроить в Greenplum 7, чтобы сделать эту MPP-СУБД еще эффективнее. Обзор наиболее популярных параметров конфигурации и рекомендации по установке их значений. Ограничения подключений и выполнения SQL-запросов: 6 параметров с перезагрузкой системы Будучи зрелой системой со множеством настроек, Greenplum предоставляет администратору и дата-инженеру широкие возможности по адаптации этой СУБД к...
Как расширить возможности Apache NiFi, используя Python: знакомимся с библиотекой NiPyAPI. Возможности, принципы работы и примеры использования NiPyAPI в управлении средой NiFi: очистка от неиспользуемых компонентов. Python в Apache NiFi Хотя официальная поддержка Python ожидается в релизе 2.0, о чем мы писали здесь, использовать этот язык программирования в Apache NiFi...

С версии 3.5.0Apache Spark поддерживает Datasketches – программную библиотеку стохастических потоковых алгоритмов. Разбираемся, что это такое, и при чем здесь алгоритм HyperLogLog. Что такое Apache Datasketches и зачем это нужно В аналитике больших данных часто возникают проблемные запросы, которые не масштабируются, поскольку требуют огромных вычислительных ресурсов и времени для получения...
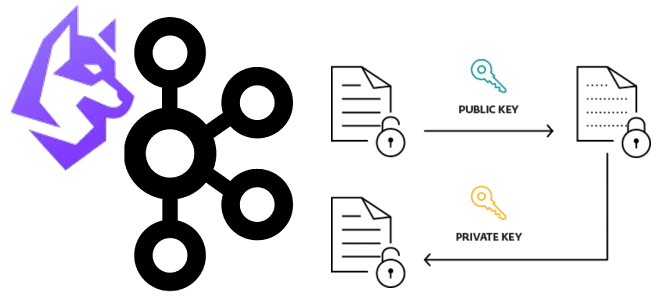
Недавно мы рассматривали пример шифрования полезной нагрузки с чувствительными данными на стороне продюсера и их расшифровку на потребителе Apache Kafka. Такой примитивный способ подходит для интеграции нескольких приложений, но в больших масштабах становится очень неудобным. Читайте, как Conduktor Gateway для Apache Kafka поможет выйти из этой ситуации, обеспечив защиту конфиденциальных...
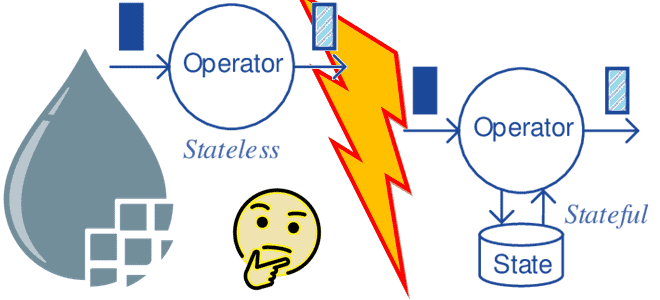
Недавно мы писали, что такое Apache NiFi без сохранения состояния и чем он отличается от классического приложения потокового конвейера обработки данных. Сегодня рассмотрим особенности и ограничения Stateless-механизма и наилучшие сценарии использования в сравнении с классическим движком. Особенности и ограничения Stateless-движка Напомним, классический NiFi предназначен для запуска большого многопользовательского приложения, в...

Как использовать Greenplum в проектах машинного обучения: знакомимся с расширением PostgresML и модулем pgvector. Возможности и ограничения плагинов, превращающих MPP-СУБД в полноценный MLOps-инструмент. Как превратить Greenplum в векторную базу данных с расширением pgvector Будучи вариацией PostgreSQL с механизмами массово-параллельной загрузки, Greenplum отлично справляется с огромным объемом данных. Однако, к хранилищам...
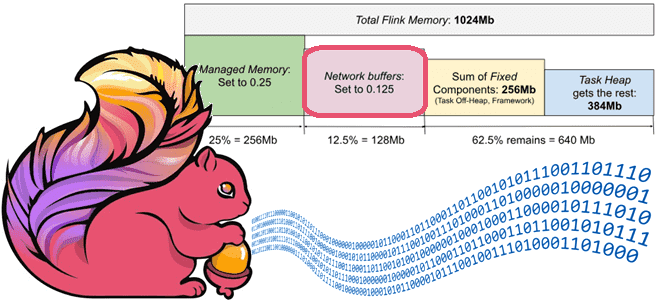
Как Apache Flink обеспечивает стабильно высокую пропускную способность потоковой обработки данных с помощью сетевых буферов и контрольных точек, каковы возможности и ограничения этих механизмов и какие конфигурации надо настроить для их эффективного использования. Зачем Apache Flink нужны сетевые буферы Каждая запись в Flink отправляется следующей подзадаче вместе с другими записями...
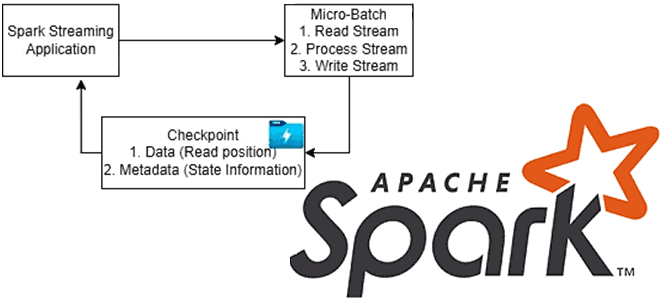
Чтобы обеспечить отказоустойчивость потоковых приложений, Apache Spark использует механизм контрольных точек. Какие они бывают, когда их включать и как настроить для эффективной работы. Что такое checkpoint в Apache Spark и зачем он нужен Чтобы приложение потоковой передачи было устойчиво к сбоям по внешним причинам, например, отказ JVM, Spark Streaming сохраняет...
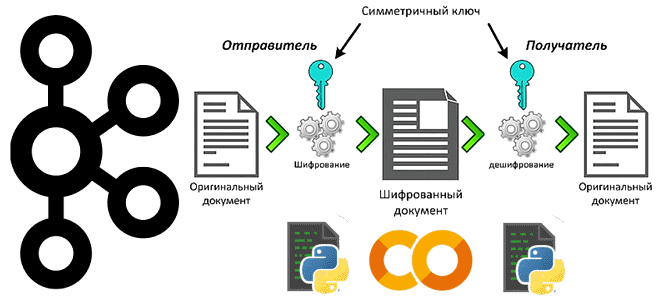
Простой пример шифрования полезной нагрузки с чувствительными данными на стороне продюсера и их расшифровка на потребителе Apache Kafka: пишем и запускаем Python-код в Google Colab. Публикация данных в Kafka: шифрование на стороне продюсера Apache Kafka часто используется для обмена данными между несколькими системами внутри предприятия. Однако, даже при работе во...
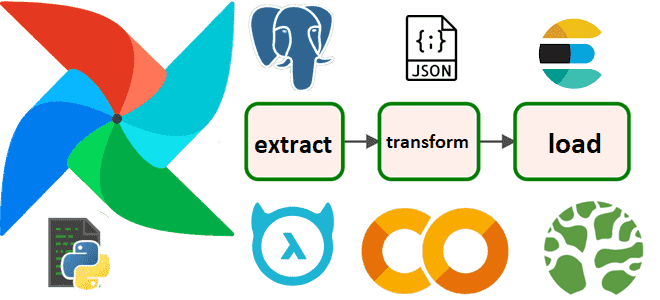
Пример ETL-процесса в DAG Apache AirFlow: извлечение данных о выполненных заказах из PostgreSQL, преобразование в JSON-документ и загрузка в NoSQL-хранилище Elasticsearch в виде JSON-документа с отправкой уведомления в Telegram. Разработка и запуск кода в Google Colab. Постановка задачи и проектирование конвейера в виде DAG AirFlow О том, как построить простой...

Зачем разделять таблицы в озере данных, что не так с Hive-разделением и Z-упорядочение в Delta Lake и как работает жидкая кластеризация (Liquid Clustering) – новая стратегия оптимизации размещения данных от Databricks. Что не так с Hive-разделением и Z-упорядочение таблиц в Delta Lake В озере данных физическое расположение данных может оказать...
Мы уже писали про особенности тестирования систем машинного обучения. Чтобы не повторяться, сегодня рассмотрим фреймворки для реализации идей MLOps, а также рассмотрим, какие тесты должны быть пройдены для проверки работоспособности ML-продукта. 3 категории тестов для ML-систем Согласно концепции MLOps, полный конвейер разработки включает в себя три основных компонента: конвейер данных,...

Как выбирать политики распределения и разделения данных в Greenplum, в чем польза динамического сканирования индексов, зачем регулярно использовать операции VACUUM и ANALYZE, из-за чего тормозят SQL-запросы и как это исправить. Эффективное распределение и разделение Будучи основанной на PostgreSQL, Greenplum расширяет возможности этой замечательной СУБД, добавляя операции с массово-параллельной обработкой. Для...
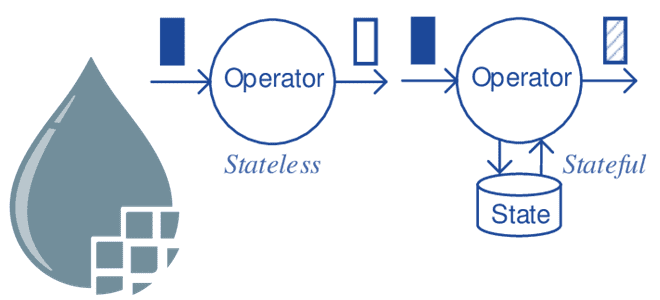
Чем Stateless-движок отличается от классического механизма потоковой обработки данных Apache NiFi, каковы его ключевые принципы работы и почему здесь особенно важна надежность источника. Классический Apache NiFi: основные понятия Приложение Apache NiFi можно рассматривать как два отдельных, но взаимосвязанных компонента: подлинности потока и его движок. Объединив их в одном приложении, NiFi...

Насколько быстро работает Apache Kafka в облачной платформе Upstash: пишем простой пример для пары продюсер-потребитель на Python и измеряем задержку. Миллисекундное отставание при публикации и минутная задержка обработки данных на потребителе. Задержка публикации сообщений в Kafka Чтобы измерить задержку асинхронного обмена данными в системе с EDA-архитектурой из продюсера и потребителя...

Каждому специалисту по Data Science и инженеру данных знакома Python-библиотека pandas. Однако, для работы с большими данными она не очень подходит из-за высокого потребления памяти. Тем не менее, отказаться от старых привычек сложно. Поэтому разбираемся, зачем использовать API Pandas в Apache Spark и как это сделать наиболее эффективно. Чем отличается...
Простой пример объединения нескольких задач, описанных в разных Python-файлах, в единый DAG Apache AirFlow на кейсе выгрузки из реляционной базы PostgreSQL данных о выполненных заказах за последние 100 дней. Разработка и запуск кода в Google Colab. Объединение задач из отдельных Python-файлах в один DAG AirFlow Я уже показывала, как построить...