 877
877 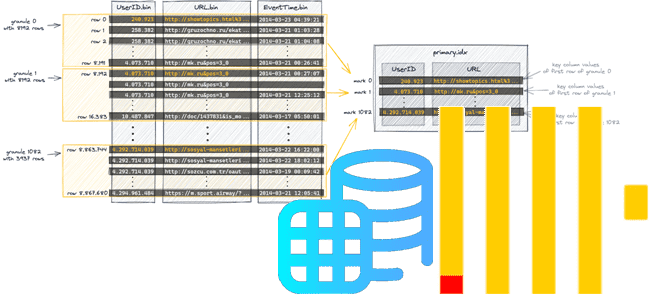
Как ClickHouse реализует разреженные индексы, что такое гранула, чем отличается широкий формат хранения данных от компактного, и почему значения первичного ключа в диапазоне параметров запроса должны быть монотонной последовательностью.
Тонкости индексации в ClickHouse
Индексация считается одним из наиболее известных способов повышения производительности базы данных. Индекс определяет соответствие значения ключа записи (одного или нескольких атрибутов таблицы) и ее местоположения. Для хранения индексов обычно используются такие структуры данных, как деревья и хэш-таблицы. Поскольку хранение и обновление индекса занимают ресурсы, имеет смысл индексировать только те поля, которые часто встречаются в условиях поиска, используются для соединения таблиц или являются внешними ключами, а также имеют высокую селективность, т.е. небольшую долю строк с одинаковым значением индексируемого столбца.
В общем виде, индекс представляет собой файл с последовательностью пар ключей и указателей. Он намного меньше блока данных и может поместиться в буфере основной памяти, повышая скорость поиска записи. Индекс называется разреженным (sparse index), когда каждый ключ ассоциируется с определённым указателем на блок в сортированном файле данных. В плотном индексе (dense index) каждый ключ ассоциируется с конкретным указателем на запись в сортированном файле данных. В кластерных индексах с дублированными ключами разрежённый индекс указывает на наименьший ключ в каждом блоке, а плотный индекс – на первую запись с указанным ключом.
В классических реляционных СУБД первичный индекс содержит одну запись на каждую строку таблицы, позволяя быстро находить определенные строки, чтобы эффективно выполнять поисковые запросы и точечные обновления. Поиск записи в древовидной структуре данных имеет среднюю временную сложность O(log n), в зависимости от коэффициента ветвления сбалансированного дерева (B-дерева) и количества индексированных строк. В большинстве случаев B-деревья не являются глубокими, поэтому для поиска записей требуется несколько операций поиска по диску. Однако, когда данных много, например, несколько миллионов строк, и коэффициент ветвления измеряется тысячами, возникают дополнительные накладные расходы на диск и память. Также растут высокие затраты на вставку при добавлении новых строк в таблицу и записей в индекс, а иногда и на перебалансировку B-дерева.
Поэтому табличные движки в ClickHouse используют другой подход. Основной табличный движок MergeTree разработан и оптимизирован для обработки огромных объемов данных: прием миллионов вставок строк в секунду и хранения сотни петабайт. Данные быстро записываются в таблицу по частям, при этом правила объединения частей применяются в фоновом режиме. В ClickHouse таблица состоит из частей данных, отсортированных по первичному ключу. Когда данные вставляются в таблицу, создаются отдельные части данных, и каждая из них лексикографически сортируется по первичному ключу. Данные, принадлежащие разным разделам, разделяются на разные части. Части, принадлежащие разным разделам, не объединяются. Движок MergeTree не гарантирует, что все строки с одинаковым первичным ключом будут находиться в одной части данных.
Части данных могут храниться в широком (Wide) или компактном (Compact) формате. В Wide-формате каждый столбец хранится в отдельном файле файловой системы, в Compact-формате все столбцы хранятся в одном файле. Компактный формат можно использовать для повышения производительности небольших и частых вставок. Формат хранения данных определяется параметрами min_bytes_for_wide_part и min_rows_for_wide_part настройками табличного движка. Если количество байтов или строк в части данных меньше значения соответствующего параметра, часть сохраняется в Compact-формате, иначе – в Wide. Если ни один из этих параметров не установлен, части данных сохраняются в Wideформате.
Каждая часть имеет свой первичный индекс, основанный на первичном ключе, который полностью загружается в основную память. Если размер индексного файла превышает доступное свободное пространство памяти, ClickHouse выдает ошибку. Когда части данных объединяются, их первичные индексы также объединяются. Чтобы максимально эффективно использовать диск и память в очень больших масштабах, вместо индексации каждой строки в ClickHouse первичный индекс части имеет одну запись индекса (mark, метку) на группу строк (granule, гранулу).
Первичный индекс не содержит непосредственно физических местоположений гранул, соответствующих индексным меткам, чтобы максимально эффективно использовать диск и память, т.к. первичный индексный файл должен помещаться в основную память. Поэтому значения столбцов таблицы логически делятся на гранулы. Однако, значения столбцов физически не хранятся внутри гранул: гранула — это просто логическая организация значений столбцов для вычислений, наименьший неделимый набор данных, который передается в ClickHouse для обработки данных. Поэтому вместо чтения отдельных строк ClickHouse всегда потоково и параллельно читает целую группу строк, т.е. гранулу. Например, при обработке запроса ClickHouse использует первичный индекс, выбирая гранулу, которая может содержать строки, соответствующие запросу. Только для этой одной гранулы ClickHouse требуются физические местоположения для потоковой передачи соответствующих строк для дальнейшей обработки.
ClickHouse не разбивает строки или значения, поэтому каждая гранула всегда содержит целое число строк. Первая строка гранулы помечается значением первичного ключа строки. Для каждой части данных ClickHouse создает индексный файл, в котором хранятся отметки. Для каждого столбца, независимо от того, находится он в первичном ключе или нет, ClickHouse также сохраняет одни и те же метки, которые позволяют находить данные непосредственно в файлах столбцов. Размер гранул ограничен настройками табличного движка index_granularity и index_granularity_bytes. Количество рядов в грануле варьируется от 1 до index_granularity и зависит от размера гранулы. Размер гранулы может превысить значение index_granularity_bytes, если размер одной строки превышает значение параметра. Тогда размер гранулы равен размеру ряда.
Наличие гранул реализует разреженную индексацию в ClickHouse благодаря тому, что строки хранятся для части на диске, упорядоченные по столбцам первичного ключа. Вместо непосредственного поиска отдельных строк, например, индекса на основе B-дерева, разреженный первичный индекс в ClickHouse позволяет быстро идентифицировать группы строк, которые могут соответствовать запросу. Это реализуется с помощью двоичного поиска по записям индекса. Найденные гранулы, т.е. группы потенциально совпадающих строк затем параллельно передаются в движок ClickHouse для поиска совпадений. Такой дизайн позволяет сделать основной индекс небольшим, чтобы он полностью помещался в основную память, и сокращает время выполнения запроса. Это особенно заметно для запросов диапазона, которые типичны для сценариев использования анализа данных и машинного обучения, о чем мы рассказываем здесь.
Будучи колоночной СУБД, ClickHouse хранит данные на диске в одном bin-файле для каждого столбца таблицы. Причем все значения для этого столбца хранятся в сжатом формате, и все строки хранятся на диске в лексикографическом порядке возрастания по столбцам первичного ключа и дополнительным столбцам ключа сортировки, если он указан при создании таблицы. Как это сделать, читайте в нашей новой статье. Поскольку первичный ключ определяет лексикографический порядок строк на диске, таблица может иметь только один первичный ключ.
Первичный индекс создается на основе гранул и представляет собой несжатый файл primary.idx плоского массива, содержащий так называемые числовые индексные метки, начинающиеся с 0. Файл меток также представляет собой плоский несжатый mrk-файл массива, содержащий метки, нумерация которых начинается с 0. Индекс хранит значения столбцов первичного ключа каждой первой строки для каждой гранулы, т.е. хранит значения столбцов первичного ключа из каждой n-й строки таблицы на основе физического порядка строк, определенного столбцами первичного ключа. Здесь n – размер гранулы, т.е. количество строк, входящих в эту группу.
Записи первичного ключа называются индексными метками, поскольку каждая запись индекса отмечает начало определенного диапазона данных. Этот глобальный порядок позволяет ClickHouse использовать алгоритм двоичного поиска по индексным меткам для первого ключевого столбца, когда запрос фильтруется по первому столбцу первичного ключа. Когда запрос фильтруется по столбцу, который является частью составного ключа и является первым ключевым столбцом, ClickHouse запускает алгоритм двоичного поиска по индексным меткам ключевого столбца.
Алгоритмы использования индекса
Индексное поле указывается при создании таблицы в DDL-инструкции, например, следующий запрос указывает составной ключ сортировки для таблицы с помощью оператора ORDER BY и явно задает, сколько записей в первичном индексе с помощью настройки index_granularity.
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;
Значение index_granularity_bytes, равное 0, отключает отключить адаптивную детализацию индекса, при которой ClickHouse автоматически создает одну запись индекса для группы из n строк, когда n меньше index_granularity и размер объединенных данных строки для этих n строк больше или равен 10 МБ (значение по умолчанию для index_granularity_bytes) или общий размер данных строки для n строк меньше 10 МБ, но n равно index_granularity.
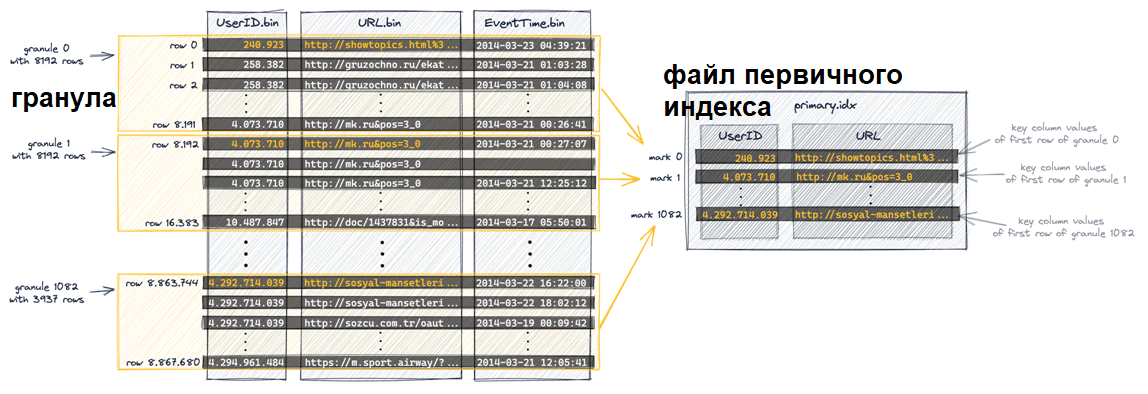
ClickHouse использует свой разреженный первичный индекс для быстрого двоичного поиска гранул, которые могут содержать строки, соответствующие запросу. После выбора гранул при выполнении запроса ClickHouse находит выбранные гранулы, чтобы передать все их строки в движок и найти строки, которые действительно соответствуют запросу. Физическое расположение всех гранул для таблицы хранится в файлах меток. Как и в случае с файлами данных, на каждый столбец таблицы приходится один файл меток.
После того как ClickHouse определил и выбрал индексную метку для гранулы, которая может содержать совпадающие строки для запроса, в файлах меток выполняется поиск по позиционному массиву, чтобы получить физическое местоположение гранулы. Каждая запись файла меток для определенного столбца хранит два местоположения в виде смещений:
- первое смещение block_offset определяет местоположение блока в сжатом файле данных столбца, который содержит сжатую версию выбранной гранулы. Этот сжатый блок потенциально содержит несколько сжатых гранул. Найденный блок сжатого файла при чтении распаковывается в основную память.
- Второе смещение granule_offset из файла меток определяет местоположение гранулы в несжатых данных блока.
Для таблиц с wide-форматом и без адаптивной детализации индекса, которая включена по умолчанию, ClickHouse использует mrk-файлы меток, которые содержат записи с двумя адресами длиной 8 байт на каждую запись. Эти записи представляют собой физическое расположение гранул одинакового размера. Для таблиц с широким форматом и с адаптивной детализацией индекса ClickHouse использует mrk2-файлы меток, которые содержат аналогичные записи для mrk-файлов меток, но с дополнительным третьим значением для каждой записи: количеством строк гранулы, с которой связана текущая запись. Для таблиц компактного формата ClickHouse использует mrk3-файлы меток.
Когда запрос фильтруется по нескольким ключевым столбцам, ClickHouse выполняет двоичный поиск по индексным меткам первого ключевого столбца. В составном первичном ключе порядок ключевых столбцов может существенно влиять эффективность фильтрации по столбцам вторичного ключа в запросах и степень сжатия файлов данных таблицы. Когда запрос фильтруется хотя бы по одному столбцу, который является частью составного ключа и является первым ключевым столбцом, ClickHouse запускает алгоритм двоичного поиска по индексным меткам ключевого столбца. Когда запрос фильтруется (только) по столбцу, который является частью составного ключа, но не является первым ключевым столбцом, ClickHouse использует общий алгоритм поиска исключений по индексным меткам ключевого столбца. Во втором случае порядок ключевых столбцов в составном первичном ключе важен для эффективности общего алгоритма поиска исключений, который работает наиболее эффективно, когда гранулы выбираются через столбец вторичного ключа, где предшествующий ключевой столбец имеет меньшую мощность.
Если нужно идентифицировать отдельные строки таблицы ClickHouse с помощью первичного ключа столбца UUID с уникальным значением для каждой строки, он должен быть первичным ключом. Поскольку данные строк таблицы ClickHouse хранятся на диске, упорядоченные по столбцам первичного ключа, наличие столбца с очень высокой мощностью, например, UUID в первичном ключе или составном первичном ключе перед столбцами с более низкой мощностью снижает степень сжатия других столбцов таблицы. Компромисс между самым быстрым поиском и оптимальным сжатием данных заключается в использовании составного первичного ключа, в котором UUID является последним ключевым столбцом после ключевых столбцов с низкой мощностью, которые используются для обеспечения хорошей степени сжатия для некоторых столбцов таблицы.
Для SELECT-запросов ClickHouse анализирует, можно ли использовать индекс. Обычно это происходит, когда в запросе есть операторы фильтрации WHERE/PREWHERE, IN или LIKE с фиксированным префиксом для столбцов или выражений, находящихся в первичном ключе. Также если есть ключ разделения или логическими связями этих выражений. Таким образом, можно быстро выполнять запросы по одному или нескольким диапазонам первичного ключа.
Если пользователь создает таблицу с частично монотонным первичным ключом, например, дни месяца, ClickHouse создает разреженный индекс. Когда пользователь выбирает данные из такой таблицы, ClickHouse анализирует условия запроса. Если надо получить данные между двумя отметками индекса и обе эти отметки попадают в пределах одного месяца, ClickHouse может использовать индекс в данном конкретном случае, поскольку умеет рассчитывать расстояние между параметрами запроса и отметками индекса.
Однако, ClickHouse не может использовать индекс, если значения первичного ключа в диапазоне параметров запроса не представляют собой монотонную последовательность. В этом случае ClickHouse полностью сканирует данные. Для таблиц с движками семейства MergeTree можно указать индексы пропуска данных, которые агрегируют некоторую информацию об указанном выражении по блокам, состоящим из гранул granularity_value. Размер гранулы задается с помощью настройки index_granularity в табличном движке, по умолчанию равной 1. Затем эти агрегаты используются в SELECT-запросах для уменьшения объема данных, считываемых с диска, путем пропуска больших блоков данных, когда запрос с оператором WHERE не может быть удовлетворен.
Узнайте больше про администрирование и эксплуатацию ClickHouse для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

