 1082
1082 
Содержание
Как Apache Kafka реализует требование к изоляции потребления сообщений, опубликованных транзакционно, и где это настроить в клиентских API, зачем отслеживать LSO, для чего прерывать транзакцию, и какими методами это обеспечивается в библиотеке confluent_kafka.
Транзакционое потребление: изоляция чтения сообщений в Apache Kafka
При том, что Apache Kafka не является базой данных, она все равно хранит опубликованные сообщения, поддерживая распределённые транзакции с полноценными ACID-гарантиями только в пределах самой платформы, включая несколько продюсеров и потребителей для разных топиков. Про атомарность (atomic) транзакционной публикации сообщений мы недавно писали здесь, а сегодня рассмотрим другое свойство из набора ACID – изоляцию (isolation).
Транзакции были представлены в Kafka 0.11.0, где приложения могут атомарно записывать данные в несколько топиков и разделов. Для этого потребители, читающие из этих разделов, должны быть настроены на чтение только зафиксированных данных. За это отвечает параметр isolation.level в конфигурации потребителя. Этот параметр управляет чтением сообщений, опубликованных транзакционно. Если для него установлено значение read_committed, метод потребителя poll() будет возвращать только зафиксированные транзакционные сообщения. Если установлено значение по умолчанию read_uncommitted, то метод poll() будет возвращать все сообщения, даже транзакция публикации которых была прервана.
Свойство isolation.level устанавливается при инициализации потребителя, чтобы контролировать, какие записи транзакций ему доступны. Значение read_uncommited разрешает получение всех записей независимо от результата транзакции, а read_commited – только записей из зафиксированных транзакций. При этом уровень изоляции не означает, что потребитель будет читать только записи транзакций: незафиксированные записи всегда доступны.
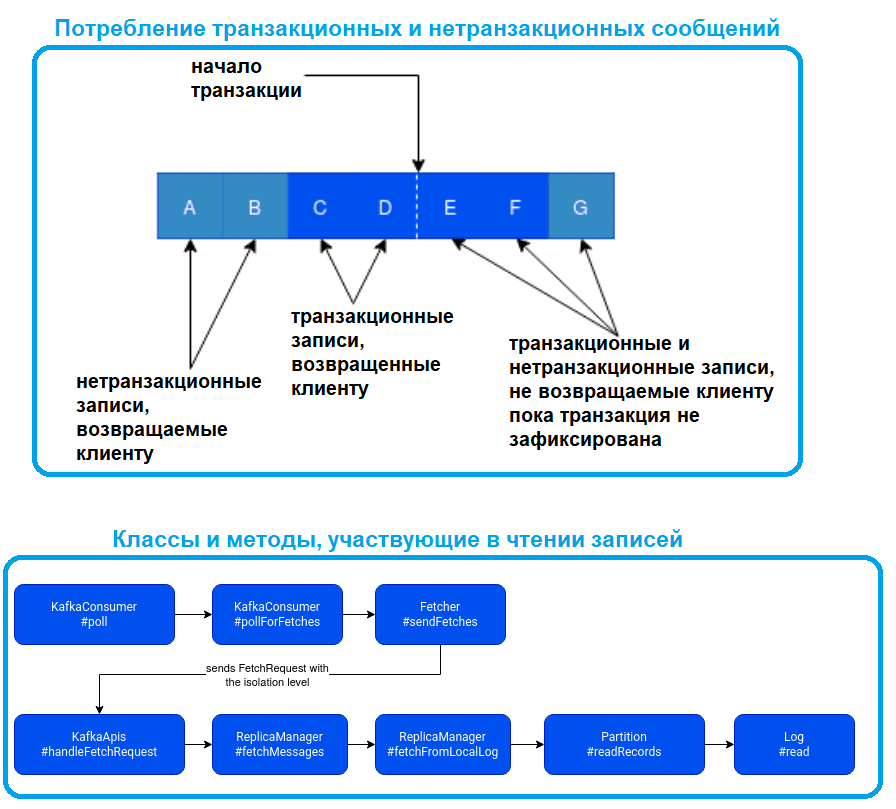
В режиме read_commited буферизация на стороне клиента отсутствует. Вместо этого конечное смещение раздела для потребителя read_commited будет смещением первого сообщения в разделе, принадлежащем открытой транзакции. Это смещение известно как последнее стабильное смещение (LSO, Last Stable Offset). Потребитель read_commit будет читать только LSO и отфильтровывать любые транзакционные сообщения, которые были прерваны. LSO также влияет на поведение методов SeekToEnd(Collection) и endOffsets(Collection) для потребителей с уровнем изоляции, установленным в read_committed. Показатели задержки выборки также корректируются относительно LSO для потребителей read_committed. Разделы с транзакционными сообщениями будут включать маркеры фиксации или прерывания, которые указывают результат транзакции. Там маркеры не возвращаются в приложения, но имеют смещение в журнале. В результате приложения, читающие топики с транзакционными сообщениями, будут видеть пробелы в потребляемых смещениях. Эти недостающие сообщения будут маркерами транзакций, и они отфильтровываются для потребителей на обоих уровнях изоляции. Кроме того, приложения, использующие потребителей с уровнем изоляции, установленным в read_committed, также могут видеть пробелы из-за прерванных транзакций, поскольку эти сообщения не возвращены потребителем, но имеют действительные смещения.
Нетранзакционные сообщения будут возвращаться безо всяких условий в любом режиме. Сообщения всегда будут возвращаться в порядке смещения. Следовательно, в read_committed режиме Consumer.poll() будет возвращать сообщения только до последнего стабильного смещения, которое меньше смещения первой открытой транзакции. В частности, любые сообщения, появляющиеся после сообщений, принадлежащих текущим транзакциям, будут храниться до тех пор, пока соответствующая транзакция не будет завершена. Поэтому в режиме read_committed потребители не смогут прочитать верхнюю границу, когда есть незавершенные транзакции.
Уровень изоляции устанавливается для каждого потребителя и отправляется брокеру с запросом на выборку. На стороне брокера уровень изоляции позже преобразуется в экземпляр kafka.server.FetchIsolation (один из FetchLogEnd, FetchTxnCommited, FetchHighWatermark) и передается из ReplicaManager в Log , где происходит физическое извлечение данных. Извлечение состоит из поиска LSO – максимально допустимого смещения и чтения записей до него.
Как настроить уровень изоляции потребителя в клиентских API
Примечательно, что настроить isolation.level можно не во всех клиентских приложениях. Например, библиотека kafka-python, которую я обычно использую для разработки скриптов публикации и потребления сообщений, не поддерживает этот параметр. А вот в API библиотеки confluent_kafka, которая также позволяет создавать Python-клиентов, можно настроить уровень изоляции потребителя. Это связано с тем, что в библиотеке confluent_kafka есть транзакционный API, в котором продюсер транзакций работает поверх идемпотентного продюсера и обеспечивает полную семантику exactly once для потребителя с уровнем изоляции read_committed.
Экземпляр продюсера настраивается для транзакций путем установки transactional.id –идентификатора, уникального для приложения. Как недавно писали здесь, этот идентификатор будет использоваться для изоляции устаревших транзакций от предыдущих экземпляров приложения после сбоя.
После создания экземпляра транзакционного продюсера состояние транзакции должно быть инициализировано путем вызова метода confluent_kafka.Producer.init_transactions(). Это блокирующий вызов, который получит идентификатор продюсера во время выполнения от брокера координатора транзакций, а также прервет любые устаревшие транзакции и изолирует все еще работающие экземпляры продюсера с помощью того же файла transactional.id. После инициализации транзакций приложение может начать новую транзакцию, вызвав метод confluent_kafka.Producer.begin_transaction(). Экземпляр продюсера может иметь только одну текущую транзакцию. Любые сообщения, созданные после запуска транзакции, будут принадлежать текущей транзакции и будут зафиксированы или отменены атомарно.
Нельзя создавать сообщения за пределами границы транзакции, например, до вызова confluent_kafka.Producer.begin_transaction(), после confluent_kafka.commit_transaction(), confluent_kafka.Producer.abort_transaction() или после сбоя текущей транзакции. Если потребляемые сообщения используются в качестве входных данных для транзакции, экземпляр потребителя должен быть настроен с параметром Enable.auto.commit, установленным в значение false. Эта настройка тоже есть в библиотеке kafka-python, она называется enable_auto_commit и по умолчанию установлена в значение True, что означает периодическую фиксацию смещения потребителя в фоновом режиме.
Чтобы зафиксировать использованные смещения вместе с транзакцией, надо перед фиксацией транзакции методом confluent_kafka.Producer.send_offsets_to_transaction() передать список использованных разделов и последнее обработанное смещение + 1. Это позволяет перезапустить прерванную транзакцию с использованием ранее зафиксированных смещений. Чтобы зафиксировать созданные сообщения и любые использованные смещения в текущей транзакции, надо вызвать метод confluent_kafka.Producer.commit_transaction(). Этот вызов будет блокироваться до тех пор, пока транзакция не будет полностью зафиксирована или не завершится неудачно. В качестве альтернативы, если обработка завершается неудачно или возникает ошибка прерываемой транзакции, транзакцию необходимо прервать, вызвав метод, confluent_kafka.Producer.abort_transaction() который помечает любые созданные сообщения и фиксации смещения как прерванные. После того, как текущая транзакция была зафиксирована или прервана, новая транзакция может быть запущена confluent_kafka.Producer.begin_transaction() повторным вызовом.
Текущая транзакция может необратимо завершиться неудачей из-за различных ошибок, таких как недоступность координатора транзакций, сбои записи в журнал Apache Kafka, недостаточно реплицированные разделы и т. д. На этом этапе приложение-продюсер должно прервать текущую транзакцию, используя метод confluent_kafka.Producer.abort_transaction() и, при необходимости, запустить новую транзакцию, вызвав confluent_kafka.Producer.begin_transaction(). Возможность прерывания из-за ошибки определяется вызовом confluent_kafka.KafkaError.txn_requires_abort().
Чтобы запустить операцию, прерванную из-за ошибки истечения тайм-аута, сбоя транспорта и пр., повторно, надо соответствующий флаг повторного выполнения объекта KafkaError методом confluent_kafka.KafkaError.retriable(). Если этот флаг установлен, приложение может повторить операцию немедленно или через короткий период отсрочки во избежание зацикливания.
Базовый идемпотентный продюсер обычно выдает фатальные исключения только для неисправимых ошибок кластера, когда гарантии идемпотентности не могут быть сохранены. Тем не менее, большинство таких ошибок рассматриваются транзакционным продюсером как прерываемые, поскольку транзакции могут быть прерваны и повторены полностью. С другой стороны, транзакционный продюсер вносит ряд дополнительных фатальных ошибок, которые приложению необходимо обработать путем закрытия производителя и завершения работы. У экземпляра продюсера нет возможности восстановиться после фатальных ошибок. Фатальность ошибки определяется путем вызова confluent_kafka.KafkaError.fatal().
Освоить администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники
- https://www.waitingforcode.com/apache-kafka/isolation-level-apache-kafka-consumers/read
- https://docs.confluent.io/platform/current/installation/configuration/consumer-configs/#consumerconfigs_isolation.level
- https://docs.confluent.io/platform/current/clients/confluent-kafka-python/html/index/#pythonclient-consumer
- https://github.com/dpkp/kafka-python/issues/1707
- https://kafka-python.readthedocs.io/en/master/apidoc/KafkaConsumer/
- https://docs.confluent.io/platform/current/clients/confluent-kafka-python/html/index/#pythonclient-transactional

