Что такое модификатор FINAL в SELECT-запросе ClickHouse, с какими табличными движками он работает, почему снижает производительность и как этого избежать. Тонкости потокового выполнения SQL-запросов в колоночной СУБД.
Зачем в SELECT-запросе ClickHouse нужен модификатор FINAL?
Хотя SQL-запросы в ClickHouse имеют типовую структуру, их реализация зависит от используемого движка таблиц. Например, запрос на выборку SELECT, который выполняет получение данных, выглядит так (в квадратных скобках показаны опциональные ключевые слова):
[WITH expr_list|(subquery)] SELECT [DISTINCT [ON (column1, column2, ...)]] expr_list [FROM [db.]table | (subquery) | table_function] [FINAL] [SAMPLE sample_coeff] [ARRAY JOIN ...] [GLOBAL] [ANY|ALL|ASOF] [INNER|LEFT|RIGHT|FULL|CROSS] [OUTER|SEMI|ANTI] JOIN (subquery)|table (ON <expr_list>)|(USING <column_list>) [PREWHERE expr] [WHERE expr] [GROUP BY expr_list] [WITH ROLLUP|WITH CUBE] [WITH TOTALS] [HAVING expr] [ORDER BY expr_list] [WITH FILL] [FROM expr] [TO expr] [STEP expr] [INTERPOLATE [(expr_list)]] [LIMIT [offset_value, ]n BY columns] [LIMIT [n, ]m] [WITH TIES] [SETTINGS ...] [UNION ALL ...] [INTO OUTFILE filename [COMPRESSION type [LEVEL level]] ] [FORMAT format]
В секции FROM указывается источник, из которого будут читаться данные. Это может быть таблица, подзапрос или табличная функция. Если в запросе используется модификатор FINAL, то ClickHouse выполняет полное слияние (merge) данных перед выдачей итогового результата. Этот модификатор применим при выборе данных из таблиц, использующих семейство движков MergeTree, которе считается основным в ClickHouse. Также модификатор FINAL поддерживается для реплицированных вариантов MergeTree-движков, т.е. Replicated-таблиц, и представлений (View, Buffer, Distributed, MaterializedView), которые работают поверх других движков, если они созданы для таблиц с движками семейства MergeTree.
Поскольку ClickHouse при чтении из MergeTree-таблиц использует несколько потоков, имеет смысл настроить их количество. За это отвечает настройка max_final_threads, которая устанавливает максимальное количество потоков. А параметр merge_tree_uniform_read_distribution включает и выключает равномерное распределение заданий по рабочим потокам. Алгоритм равномерного распределения стремится сделать время выполнения всех потоков примерно равным для одного запроса SELECT.
В текущей версии SELECT-запросы с модификатором FINAL выполняются параллельно, что ускоряет работу. Но так было не всегда. До версии 20.5 модификатор FINAL всегда выполнялся в один поток, что было довольно медленно. Начиная с ClickHouse 20.5, модификатор FINAL может быть параллельным. А с версии 24.1 модификатор FINAL окончательно использует вертикальный алгоритм, который лучше использует кэш ЦП.
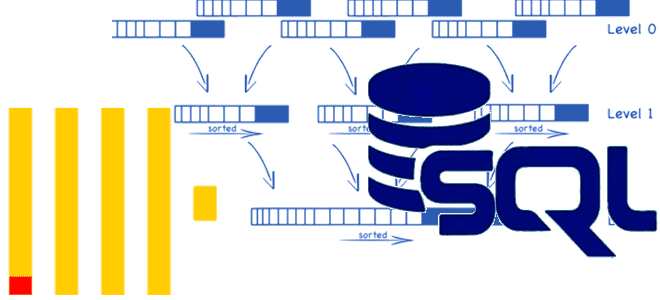
Вообще модификатор FINAL представляет собой сортировку слиянием, которая работает со строками с помощью sort_cursors. Для каждой строки он перебирает все столбцы и копирует данные в новый блок. Но если блок достаточно велик и имеет достаточный входной поток, то при возвращении для чтения или записи следующего значения в одном столбце, столбец исключался из кэша ЦП из-за большого количества данных. Для больших таблиц это приводило к тому, что каждая копия строк в конечном итоге требовала доступа к памяти, что замедляло работу. Как это было исправлено, рассмотрим далее.
Построение DWH на ClickHouse
Код курса
CLICH
Ближайшая дата курса
14 июля, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Особенности использования модификатора
Чтобы устранить минусы применения модификатора FINAL, в 24-м релизе ClickHouse вместо копирования всех столбцов для каждой строки при сортировке слиянием идет работа только с ключом сортировки и запись индекса для всех блоков. Индекс сообщает, должна ли строка быть отфильтрована, поскольку она заменена другой строкой с более поздней версией, или сохранена. Это сводит к минимуму данные, считываемые/записываемые во время сортировки слиянием, и снижает использование кэша ЦП. Возвращаются блоки, полученные в результате чтения, дополненные индексом, а затем происходит преобразование фильтра. Фильтр обрабатывает блоки и удаляет строки на основе индекса, «сворачивая» столбцы. Это происходит столбец за столбцом и оптимизировано, поэтому он также удобен для кэша, поскольку работает вертикально, а не горизонтально, поэтому кэш ЦП работает быстро.
Таким образом, использование модификатора FINAL в разделе FROM запроса SELECT ускоряет работу со средними и большими таблицами благодаря пропуску непересекающихся блоков данных и передачи их как есть с постоянным индексом. Однако, эти преимущества кэширования на уровне ЦП не работают для маленьких таблиц. Если в запросе с FINAL надо фильтровать много данных, это приводит к очень маленьким блокам, что снижает производительность. Часто запросы с FINAL выполняются медленнее, чем без него, поскольку данные объединяются во время выполнения запроса в памяти, но это не приводит к физическому слиянию фрагментов на дисках. Кроме того, запросы с модификатором FINAL читают столбцы первичного ключа в дополнение к столбцам, используемым в запросе.
Поэтому в целом использование FINAL не рекомендуется. Особенно следует избегать запроса OPTIMIZE TABLE с модификатором FINAL, поскольку его вариант использования предназначен для администрирования, а не для повседневных операций. Использование модификатора FINAL в запросе OPTIMIZE TABLE… инициирует незапланированное объединение частей данных конкретной таблицы в одну часть данных. Во время этого процесса ClickHouse считывает все части данных, распаковывает, объединяет, сжимает их в одну часть, а затем перезаписывает обратно в хранилище объектов, вызывая огромную нагрузку на процессор и операции ввода-вывода. При этом оптимизация перезаписывает одну часть, даже если они уже объединены.
Вообще запрос OPTIMIZE TABLE пытается инициализировать незапланированное объединение частей данных для таблиц. Этот запрос поддерживается для семейства движков MergeTree, включая материализованные представления, и механизмов Buffer. При использовании OPTIMIZE с ReplicationdMergeTree-движком ClickHouse создает задачу для слияния и ожидает выполнения на всех репликах, если для параметра alter_sync установлено значение 2, или в текущей реплике, когда этот параметр равен 1. Если при этом использовать модификатор FINAL, оптимизация выполняется даже, когда все данные уже находятся в одной части. Изменить это поведение можно с помощью оптимизации _skip_merged_partitions. Слияние выполняется принудительно, даже если это происходит параллельно.
При использовании движка ReplacingMergeTree рекомендуется разбивать таблицы так, чтобы ключ разделения был постоянным для каждой строки. Это гарантирует, что обновления, относящиеся к одной и той же строке, будут отправляться в один и тот же раздел таблицы. Объединение данных в ClickHouse происходит на уровне разделов таблицы. Но, если две строки с одним и тем же ключом замены окажутся в разных разделах, они никогда не будут объединены в одну строку. Избежать этого поможет добавление параметра do_not_merge_across_partitions_select_final к модификатору FINAL, который объединяет все строки во всех разделах таблицы. Чтобы повысить производительность таких запросов, можно задать параметру do_not_merge_across_partitions_select_final значение 1. Это приведет к слиянию и независимой обработке разделов.
Например, когда для партиционированной таблицы выполняется ежедневное разделение по дате и по окончания дня есть некоторый интервал времени, в течение которого можно получать обновления. Для оптимизации таблицы можно применить запрос OPTIMIZE TABLE xxx PARTITION ‘prev_day’ FINAL do_not_merge_across_partitions_select_final. Добавление параметра do_not_merge_across_partitions_select_final указывает ClickHouse, что не нужно объединять файлы результатов во время запроса. Это ускорит выборку данных. А, чтобы соединять части результатов через определенное время, можно задать параметр min_age_to_force_merge_seconds. Это позволит гарантировать, что по истечении заданного периода времени данные будут находиться в наименьшем количестве файлов, что повышает производительность запросов.
Узнайте больше про эффективное применение ClickHouse в аналитике больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Построение DWH на ClickHouse
Код курса
CLICH
Ближайшая дата курса
14 июля, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Источники