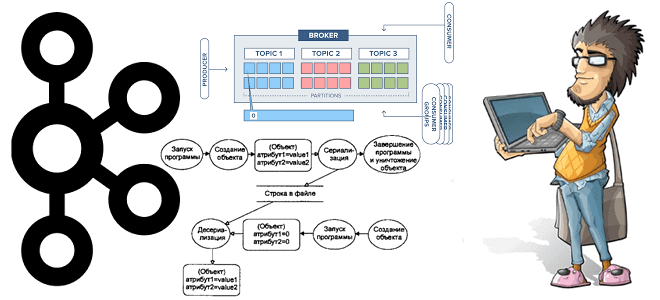
В рамках курсов по Apache Kafka для разработчиков и администраторов кластера, сегодня заглянем под капот AdminClient и на практических примерах разберем, как динамически создавать новый топик и описывать его программным способом через API. Еще рассмотрим, почему метод deleteTopics() нужно применять очень осторожно, а также вспомним основы ООП, говоря про классы...

Чтобы дополнить наши курсы по Kafka и Spark интересными примерами, сегодня рассмотрим практический кейс разработки микросервисного конвейера машинного обучения на этих фреймворках. Читайте далее, зачем выносить ML-компонент в отдельное Python-приложение от остальной части Big Data pipeline’а, и как Docker поддерживает эту концепцию микросервисного подхода. Постановка задачи и компоненты микросервисного ML-конвейера...
6 июня 2021 года компания Confluent, которая продвигает коммерческую версию платформы Apache Kafka, выпустила новый релиз ksqlDB. Сегодня рассмотрим самые важные исправления ошибок и новые функции ksqlDB 0.19.0, уделив особое внимание SQL-запросам соединения таблиц через JOIN по внешнему ключу. ТОП-10 исправленных ошибок в новом релизе ksqlDB Напомним, ksqlDB – это...

Продолжая разбирать тонкости сериализации данных в Apache Kafka на практических примерах, сегодня рассмотрим кейс индийской ИТ-компании Naukri Engineering о повторной обработке сообщений и особенностях форматов. Читайте далее, чем хороши заголовки Kafka и почему их не так просто использовать, а также зачем писать свой сериализатор с десериализатором для достижения 100%-ного SLA....
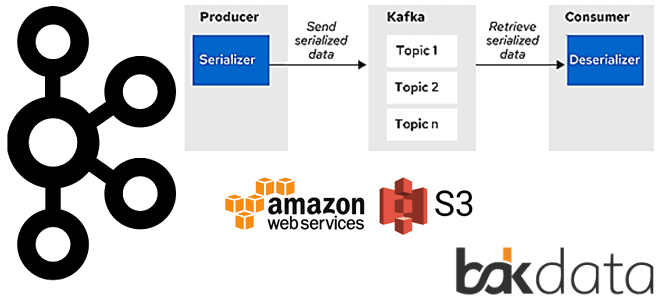
Сегодня рассмотрим проблему обработки больших сообщений в Apache Kafka Streams и способы ее решения с помощью средства сериализации и десериализации (SerDe) от немецкой ИТ-компании Bakdata. Узнайте, почему максимального лимита конфигурации max.message.bytes не хватает, зачем и как приложение Kafka Streams материализует данные, а также каким образом kafka-s3-backed-serde читает и записывает большие...
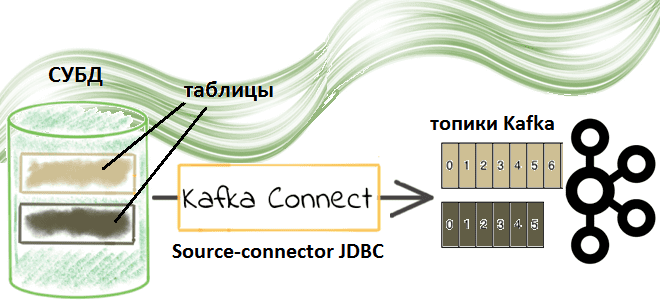
Недавно мы рассматривали пример потоковой передачи данных между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Сегодня заглянем под капот такой интеграции и разберем подробнее, что именно представляет собой JDBC-коннектор источника Kafka от Confluent. Компоненты Kafka Confluent для потоковой интеграции данных: коннекторы и реестр схем...

Сегодня в рамках обучения разработчиков распределенных приложений и дата-инженеров рассмотрим практический пример потоковой интеграции данных из 2-х разных источников с Apache Kafka. Читайте далее, как мгновенно передать данные между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Apache Kafka как средство потоковой интеграции данных Интеграция...
Сегодня рассмотрим 2 важных понятия архитектуры распределенных систем для хранения и аналитики больших данных на примере платформы потоковой обработки событий Apache Kafka.Читайте далее, что такое согласованность и полнота, а также в чем преимущества строго однократной доставки сообщений на основе транзакционной записи и фиксации смещений в журналах, и как все это...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...

Вчера мы рассказывали, почему некоторые OOM-ошибки stateful-приложений Kafka Streams могут быть вызваны некорректной работой RocksDB – встроенного key-value NoSQL-хранилище состояний. Сегодня рассмотрим, какие проблемы с дисковыми операциями характерны для этой СУБД, как они отражаются на Kafka-приложениях потоковой аналитики больших данных и каким образом можно это исправить. Быстрые диски, RocksDB и...