 868
868 
Содержание
6 июня 2021 года компания Confluent, которая продвигает коммерческую версию платформы Apache Kafka, выпустила новый релиз ksqlDB. Сегодня рассмотрим самые важные исправления ошибок и новые функции ksqlDB 0.19.0, уделив особое внимание SQL-запросам соединения таблиц через JOIN по внешнему ключу.
ТОП-10 исправленных ошибок в новом релизе ksqlDB
Напомним, ksqlDB – это клиент-серверная СУБД потоковой передачи событий с API на основе SQL для запроса и обработки данных, хранящихся в топиках Apache Kafka. До ноября 2019 года этот SQL-движок для Apache Kafka от компании Confluent назывался KSQL. Свежий релиз ksqlDB, выпущенный в июне 2021, включает 10 новых функций и 14 исправленных ошибок. Сперва перечислим исправленные ошибки, наиболее важные для разработчиков приложений Kafka Streams [1]:
- разрешена передача переменной среды KSQL_GC_LOG_OPTS, позволяя указывать параметры сборки мусора (Garbage Collection) в переменных среды, смоделированных на основе текущей конфигурации брокера K
- уточнена формулировка сообщения об ошибке при операциях со значениями NULL;
- исправлена проблема запроса INSERT, когда базовый запрос CREATE_AS не завершался при удалении потока через DROP из-за QueryRegistryImpl, который удалял ссылки на запросы из переменных сопоставления insertQueries и createAsQueries;
- расширены тесты анонимайзера запросов с функциональными тестами, в частности, добавлена анонимизация пользовательских типов данных и операторов JOIN;
- исправлено неверное определение типа Struct из схемы protobuf;
- исправлен тест shouldNotBeAbleToUseWssIfClientDoesNotTrustServerCert, чтобы предупредить атаку типа «человек посередине» — значение по умолчанию для ssl.endpoint.identification.algorithm изменено на https;
- запрос Select * теперь работает в n-сторонних соединениях с повторными разделами и несколькими уровнями вложенности, чтобы верно находить все исходные и дочерние узлы;
- отклонены несовпадения десятичных дроби в топиках AVRO – теперь при наличии таких данных, выполняется попытка их преобразования в схему ksql. Если это невозможно, то значение пропускается и регистрируется исключение apache.kafka.common. errors.SerializationException в логе потоков;
- исправлена ошибка с многоколоночными ключами в перегруппировке из-за несоответствия исходной схемы и схемы проекции. Теперь оператор SELECT * можно применять с исходной схемой без учета порядка ключей в условии PARTITION BY. А в проекции SELECT, где ключи упорядочены не так, как в источнике, они будут переупорядочены для пользователя в соответствии с исходной схемой.
- Исправлены ошибки несовместимости с новыми версиями jetty/jackson, netty. Рекомендуется также обновить оболочку Maven и использовать Java Base64 вместо Jersey.
Однако, в свежем релизе ksqlDB 0.19.0 выполнен не только баг-фиксинг, но и добавлены 10 новых функций, подробнее о которых мы расскажем далее.
Новые фичи KSQL для приложений Apache Kafka Streams
В ksqlDB 0.19.0 добавлены следующие функциональные возможности:
- таймаут простоя сервера, который могут задавать сами пользователи, чтобы обеспечить способ длительной потоковой передачи push-запросов, не позволяя отключенным клиентам слишком долго удерживать ресурсы сервера. Ранее один push-запрос мог передаваться в потоковом режиме не более 10 минут за раз, после чего сервер закрывал соединение.
- функция NULLIF, которая сравнивает аргументы и возвращает NULL, если они равны, аналогично как в других SQL-платформах. Если сравниваемые значения отличаются, NULLIF возвращает первое из них. Это особенно полезно для преобразования в NULL таких значений, как пустая строка, контрольное значение или ноль.
- масштабируемые физические операторы push-запросов. В частности, введен оператор PeekStreamOperator, который регистрирует ProcessingQueue с помощью ScalablePushRegistry. Вместе с существующими операторами pull-запросов (ProjectOperator и SelectOperator) это позволяет создать полный план выполнения. Новые операторы созданы с помощью PushPhysicalPlanBuilder, создающего PushPhysicalPlan, который фактически и выполняет запрос асинхронно в контексте Vertx. При этом для всей передачи строк не требуются какие-либо выделенные потоки, позволяя запросам выполняться одновременно и продолжительное время, не нагружая пулы потоков. Кроме того, общие операторы, которые используются как pull-, так и в push-запросах перемещены в единый пакет.
- масштабируемая маршрутизация push-запросов, чтобы решить проблему невыполнения запросов при перебалансировке. Ранее push-запрос в ksqlDB определял набор хостов во время запуска, к которым нужно подключиться, и далее придерживается их. Теперь PushRouting делает все асинхронно, используя Vertx Context и CompletableFutures для обработки, не требуя пула потоков. Также добавлен клиента http2 для KsqlClient, нужный для выдачи запросов http2 как для запросов /query-stream между экземплярами кластера.
- ScalablePushRegistry, который хранится в PersistentQueryMetadata и просматривает строки, до конца топологии приложения Kafka Streams. ProcessingQueue – это объект, зарегистрированный для данного масштабируемого push-запроса с помощью ScalablePushRegistry, и где предлагаются строки.
- класс для вычисления важных метаданных, чтобы фильтровать анонимные запросы по физическому кластеру, организации и времени создания;
- точность для десятичных знаков Avro в Kafka Connect, если в схеме явно не указано иное. Это необходимо, чтобы ksqlDB отражал поведение реестра схемы с точностью десятичных знаков до 64. Генерация схем вывод ksqlDB осталась прежней: точность явно записывается в схему, даже если использовалось значение по умолчанию.
- возможность определять условие соединения таблиц по внешнему ключу, что позволяет реализовать связь «много-ко-многим», что часто требуется при нормализации схемы реляционной СУБД путем разложения данных на несколько таблиц и их соединение через внешний ключ. Ранее это было возможно, если строки в каждой из соединяемых таблиц имеют одинаковый первичный ключ. Также добавлено построение физического плана для соединений таблиц по внешнему ключу и поддержка ungate.Как теперь это работает, мы детально рассмотрим далее.
JOIN-соединения по внешнему ключу в SQL-движке Apache Kafka
Рассмотрим пример соединения таблиц users и orders, данные которых хранятся в топиках Apache Kafka:
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT,
value INT
) WITH (
KAFKA_TOPIC = ‘my-orders-topic’,
VALUE_FORMAT = ‘JSON’,
PARTITIONS = 2
);
CREATE TABLE users (
u_id INT PRIMARY KEY,
name VARCHAR,
last_name VARCHAR
) WITH (
KAFKA_TOPIC = ‘my-users-topic’,
VALUE_FORMAT = ‘JSON’,
PARTITIONS = 3
);
CREATE TABLE orders_with_users AS
SELECT * FROM orders JOIN users ON user_id = u_id
EMIT CHANGES;
Можно указать любой столбец левой таблицы в условии соединения, чтобы выразить соответствие первичному ключу правой таблицы. Например, в кейсах аналитики больших данных, связанных с OLAP-запросами, можно рассматривать левую таблицу как таблицу фактов, а правую таблицу – как таблицу измерений в звездных схемах моделирования данных.
В данном примере выражение ON использует неключевой столбец в левой части вместо первичного ключа левой входной таблицы. Таблица результатов унаследует первичный ключ левой входной таблицы:
ORDERS_WITH_USERS <ID INT PRIMARY KEY, USER_ID INT, VALUE BIGINT, U_ID INT, NAME VARCHAR, LAST_NAME VARCHAR>
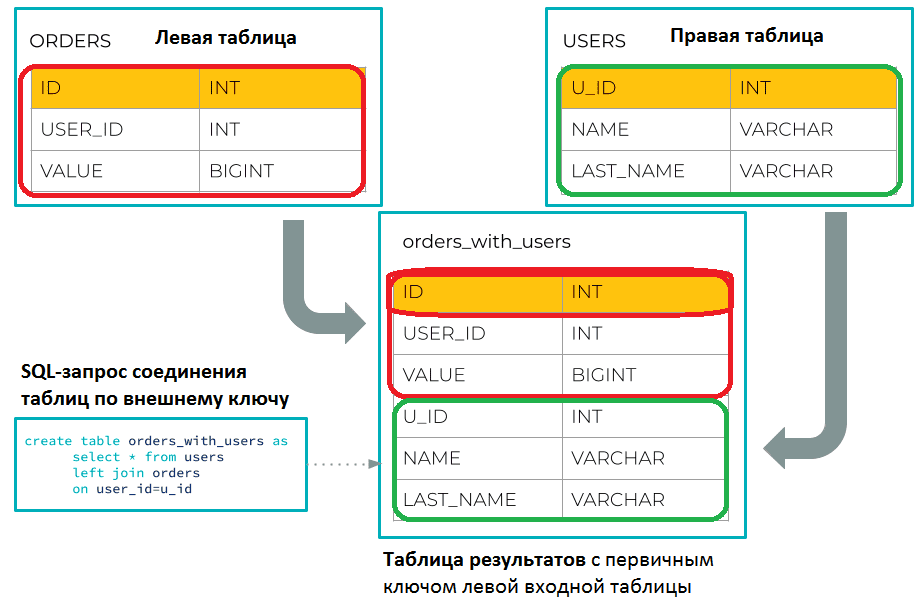
Подобно соединениям таблицы с первичным ключом, каждый раз при обновлении левой или правой входной таблицы, таблица результатов будет тоже обновляться. Поскольку соединение по внешнему ключу реализует связь «много-к-одному», обновление правой входной таблицы может привести к обновлению нескольких строк в таблице результатов. А обновление левой входной таблицы вызовет обновление одной строки в таблице результатов, подобно соединению таблицы с первичным ключом.
Однако, в отличие от соединений таблиц по первичному ключу, JOIN-запросы по внешнему ключу не требуют совместного разделения: каждая таблица может иметь разное количество разделов (партиций), как и рассмотрено в нашем примере. Таблица результатов унаследует количество разделов левой входной таблицы. Единственное ограничение в том, что левая часть условия соединения должна быть столбцом, а не выражением, содержащим столбец.
Соединения по внешнему ключу могут применять семантику INNER или LEFT OUTER, а по первичному ключу поддерживают INNER, LEFT OUTER и FULL OUTER. Кроме того, соединения по внешнему ключу нельзя использовать как часть n-стороннего соединения [2].
Другие практические особенности использования ksqlDB и других компонентов платформы Apache Kafka для разработки распределенных приложений потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://github.com/confluentinc/ksql/blob/master/CHANGELOG.md#0190-2021-06-08
- https://www.confluent.io/blog/ksqldb-0-19-adds-data-modeling-foreign-key-joins/

